原名: PolarFS: An Ultra-low Latency and Failure Resilient Distributed File System for Shared Storage Cloud Database
PolarFS是 PolarDB 的底层分布式文件系统。
极低延迟和高可用, 充分利用用户态网络/IO栈,激进使用新技术(现在看来都是平常的技术了),包括RDMA、NVMe和SPDK等。 写延迟接近本地SSD。
为了提高io吞吐,PolarFS还开发了ParallelRaft,打破Raft只能顺序提交的约束。
笔者注:整体来看,本篇都是一些当年的新技术的应用,如RDMA,SPKD,核心可以说是os-bypass和zero-copy等工程优化。 架构上没有什么特别的亮点。 当然开发的ParallelRaft笔者没关注,不予评价。
PPT: https://fuis.me/html/polarfs/polarfs.html
PolarFS之上的应用是PolarDB,PolarDB架构如下:
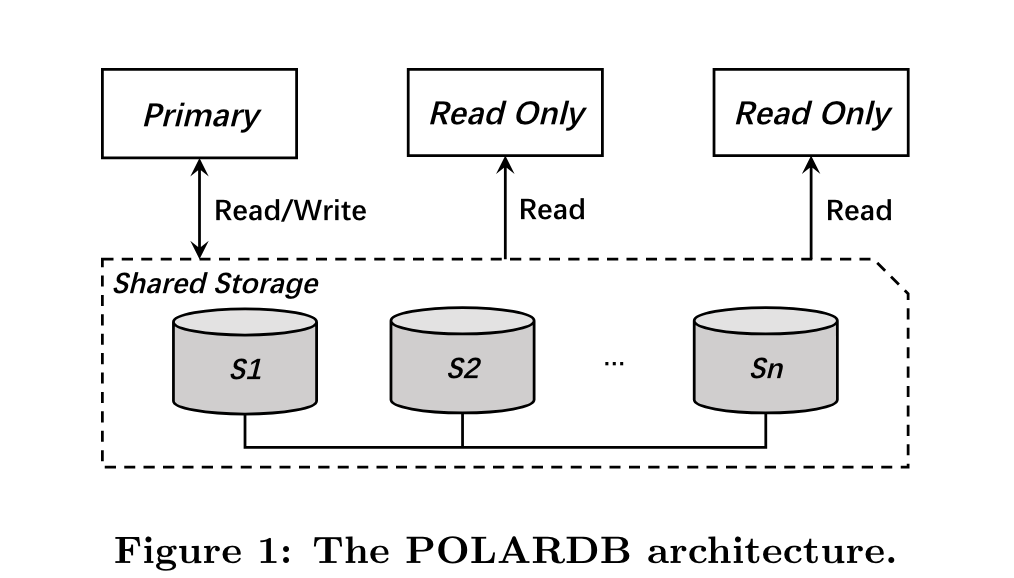
依然是存储分离架构,RW和RO节点之间共享存储。
笔者注:
这里的Shared Storage实际上就是指PolarFS吗?即将innodb的数据文件直接对接到FS上。还是说PolarDB有自己的存储引擎,然后存储引擎的文件持久化对接到PolarFS?
笔者更倾向后者,因为云原生数据库通常是需要做定制化的,直接架到分布式文件系统系统上虽然快,但是往往没那匹配云原生数据库的特性,性能、成本上做不到极致。 但是如果是第二种架构那一次读就要两跳网络(一次到polardb的存储引擎,一次到polarfs),性能也有问题,同时也看不到polarfs带来的具体收益,也就说不接入分布式文件系统,直接怼到本地盘,每个节点都是shard-nothing架构也无所谓(类似Aurora)。
TODO(zhangxingrui): 慢慢看polardb的系列论文吧,这个问题应该很快就能得到解答。
PolarFS为支持PolarDB,实现以下特性:
- 同步元数据修改(file truncation, expansion, creation or deletion),并保证RW的修改能够同步到RO
- 并发修改保证强一致性
背景·
polarfs使用当时最新的各项技术,其中的背景包括:
- NVMe SSD, SSD之间的传输协议从SAS、SATA到当前最新的NVMe,NVMe带来了更高的带宽和更低的延迟。 典型参数为 500K iops, 100us, 最新的3D XPoint SSD甚至能将延迟降到10us。 盘硬件的进化,需要推动软件的进化,目前内核的io stack开销已经成为瓶颈,一个4kb io需要耗费约20k个指令。 同时,intel推出了SPDK,能用用户态驱动来管理设备,使用polling 模式而不是interrupts模式,避免陷入内核。
- RDMA,RDMA能显著降低网络传输延迟,典型参数,传输4kb data packet 只需要4us。 RDMA支持两种API, Send/Recv 已经 Read/Write. 前者是一种配对的操作,two-side operations, 每个Send都需要一个匹配的Recv操作。 后者是one side operation。
架构·
PolarFS的架构如下:
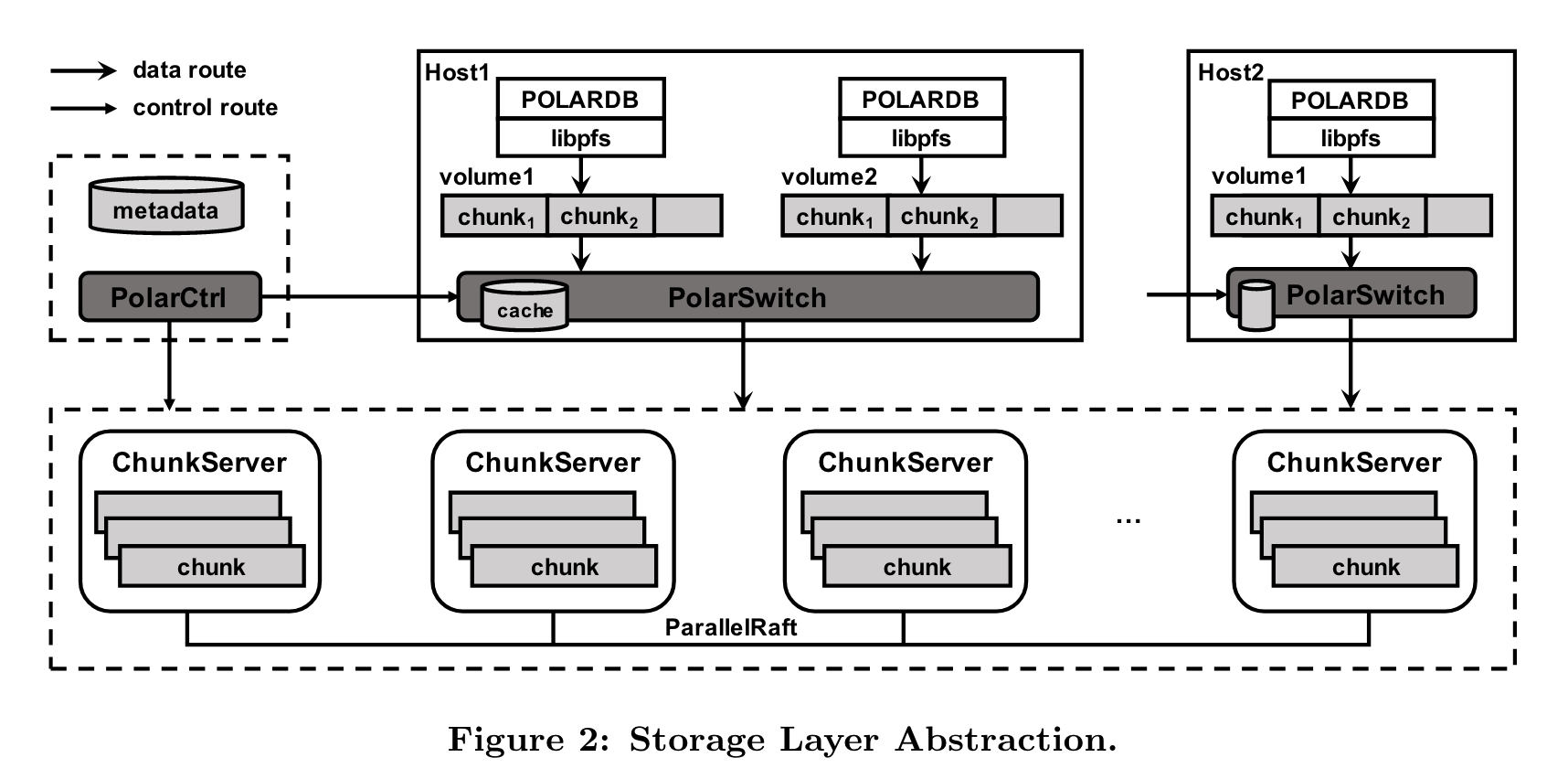
两层架构。上层为文件系统成,提供文件管理,操作互斥和同步。 下层为存储层,存储层管理盘资源,为每个db实例提供一个volume。架构图中的各组件解释如下:
- libpfs: 用户态文件系统实现库,提供类似POSIX文件系统API
- Polar Switch: resides在计算节点,重定向IO到chunkserver
- chunkserver: 部署在存储层,提供io服务
- PolarCtrl: 控制面服务,包含一组微服务作为主控,在计算和存储节点上还会部署一个agent。同时使用mysql作为metadata存储。
1. 文件系统层·
文件系统层提供共享和并发的文件修改&访问,同时还要保证一致性。
libpfs: 是一个轻量级的用户态文件系统实现。提供如下API:

论文举了一个使用的例子,每个db实例对应一个volume,当db node启动时,调用pfs_mount将实例对应的volume mount起来,并初始化文件系统状态,volume name是全局unique id(相当于应用层(polardb)要保证该id唯一), host_id为db node id,用于后续paxos共识投票。
2. 存储层·
一个volume由多个chunks组成,每个volume的容量range为 10GB 到 100TB。 volume和传统磁盘一样,可按对齐512B扇区访问。
chunk不会跨disk分配,chunk具有多副本用于保证高可用,且在不同chunkserver之间迁移,可用于消除chunkserver的热点问题。PolarFS中的 chunk大小为10GB(相比GFS 64M就大了很多了),但是可以极大减少metadata的大小,简化metadata管理,同时所有metadata可以缓存在内存,减少io cost。 但是由于size比较大,单chunk的热点问题不能消除(对于阿里EBS的data sector才2MB),作者说由于chunkserver管理的chunk很多,chunk数比节点的比例约为1000:1,所以可以靠迁移chunk,来消除单节点的热点。
block 是chunk下的单位,chunk分为多个block,每个block 64KB,block按需分配。 chunk到block的LBA映射,存储在chunkserver本地(还包含bitmap 表示free block)。单个chunk的map table占用640KB, 也可以被全缓存。
1. PolarSwitch·
polarswitch 是单独的daemon进程,部署在计算节点。libpfs将io request forward到PolarSwitch, PolarSwitch完成地址(volume, offset, len) 到chunk的转换,如果包含多个chunk,io request被拆分为多个sub io request, 然后发给leader chunkserver。
PolarSwitch要获取chunk的所有replica location(通过本地的mta cache, 如果找不到则向PolarCtrl要)。 识别leader,并向leader发起request。
另外,一个PolarSwitch可对应多个db实例,相当于一个代理。
2. ChunkServer·
一个存储节点上可以run多个ChunkServers。每个ChunkServer管理一块SSD,并且绑定到专用的一个CPU core。
笔者注: 一个ChunkServer用一个core就够了? 如果是这样,软件栈非常薄。另外一个chunk的分配由谁控制,一个chunk的多个replica不应该分配到同一个存储节点上,不然容灾怎么搞? 也就是某个组件(或许是PolarCtrl)既要感知chunkserver的逻辑location,还要感知chunkserver的物理location?
chunkserver的write,先写WAL, 为了保证WAL提交够快,使用 3DX Point介质的SSD作为WAL 提交buffer,如果该SSD满了则切换到NVMe的 SSD。
3. PolarCtrl·
PolarCtrl职责:
- 追踪memship of chunkserver, 管理chunk的migrate(成员location管理)
- 管理volume和chunk location(用mysql存????)
- 分配volume和chunk 到chunkserver
- 同步元数据到PolarSwitch (push + pull)
- 追踪每个volume的metrics, latency 和iops
- 副本完整性校验
PolarCtrl自身是多节点组成的高可用,且PolarCtrl本身不再io关键路径上(除非是创建和删除),即使短暂断连 polar switch也可以服务。
IO执行模型·
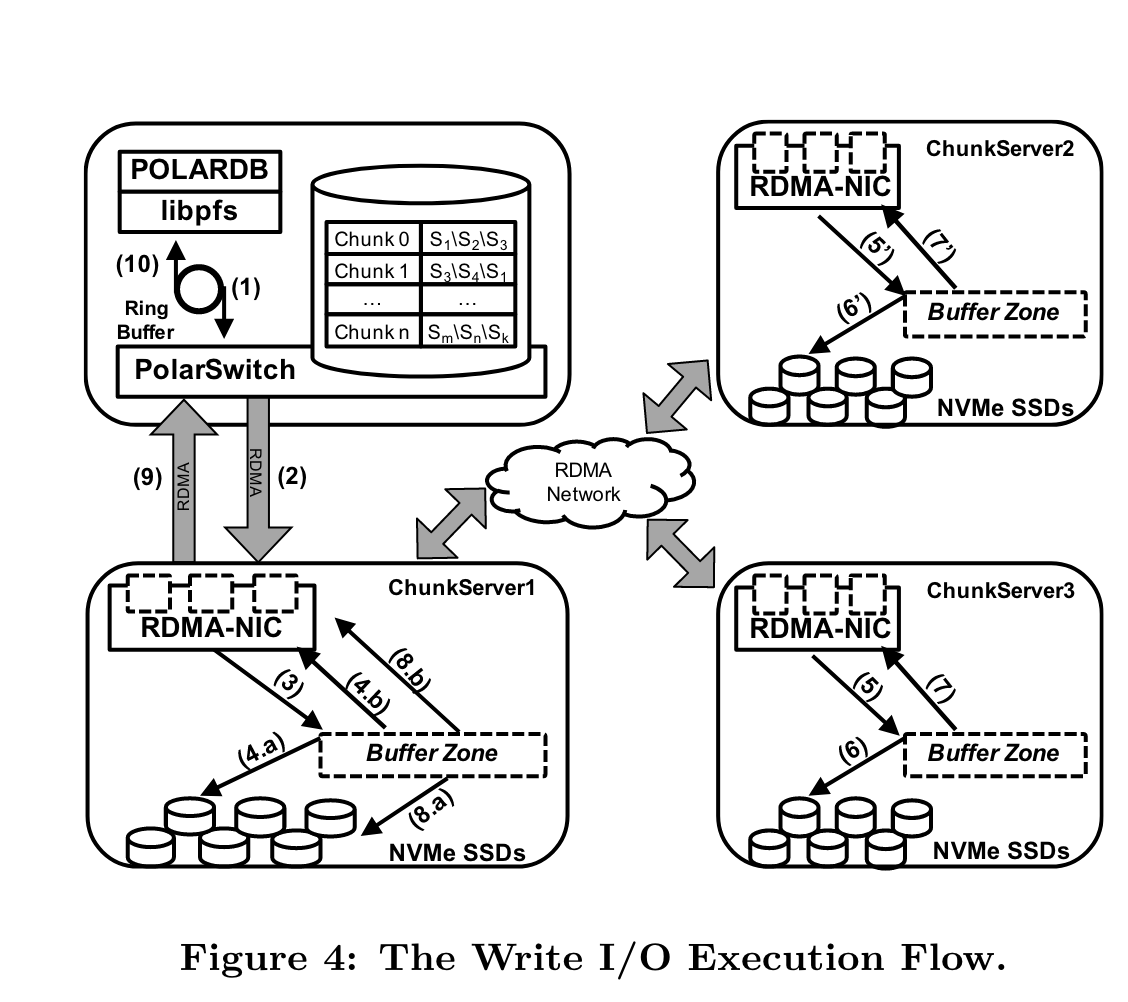
libpfs和PolarSwitch通过共享内存通信,共享内存是多条ring buffer queue。当发起io时,libpfs向buffer入队一个request,PolarSwitch内有专用线程一直polling queue(polling模式的时延更低,但是会更耗费cpu)。
一次write IO流程如下:
- PolarDB(libpfs)发起一次IO request到PolarSwitch,通过共享内存的ring buffer queue。
- PolarSwitch将request转换到对应的chunk leader node (本地meta中有location信息,如果没有则向polarctrl要)
- ChunkServer RDMA网卡将request放入预注册的buffer中,然后将request entry放在request queue中。一个I/O loop thread会polling request queue,如果发现有request则立即处理。
- request会立即写入LOG block通过SPDK,并向其他follower传播。 操作都是异步的。
- follower收到请求,处理同第3步。
- follower的io polling现成处理请求。
- follower处理完请求发起ACK。
- leader收到majority flolwer的ack,则可以apply write request
- leader终于可以回复Polar Switch
- Polar Switch回复给client
笔者注:为什么要用Raft协议,用quorum感觉更好
read io 流程只由leader处理(笔者注:leader的压力不会比较大吗?raft协议也是支持用follower去分担读压力的,为什么不用?)
CONSISTENCY MODEL – ParallelRaft·
略。不太关注,不过感觉也是这篇文章的重点之一了,不然系统的吞吐量上不去。
文件系统层实现·
文件系统层主要是metadata的管理,分为两部分:
- 单database node内,对文件的更新、访问组织
- database node之间的文件同步
1. metadata 组织·
文件系统内分为三种metadata:
- 目录entry
- inode
- block tag
上述三种结构在实现中用一种通用的object表示,称为metaobject。 metaobject在make fs的时候就生成了,生成在连续的4kb空间中。当文件系统mout时,加载这些metaobjects到内存中。
更新metaobject采用常规的txn设计。
2. 协调和同步·
通过journal file当做txn记录修改,database node通过polling journal file来apply新txn。
通常写journal file只有一个write node,多个read node。为了预防出现多写场景,PolarFS使用disk Paxos算法。 disk paxos由多个4kb page组成(用于实现原子读写), page由一个 leader record + data blocks构成, data blocks是database writer的write content,而leader record表示当前Paxos的winner和log anchor, disk paxos只在write node上运行,read node通过polling journal file,识别leader record中的log anchor,如果log anchor推进,则apply新的txn。
论文举了个例子:
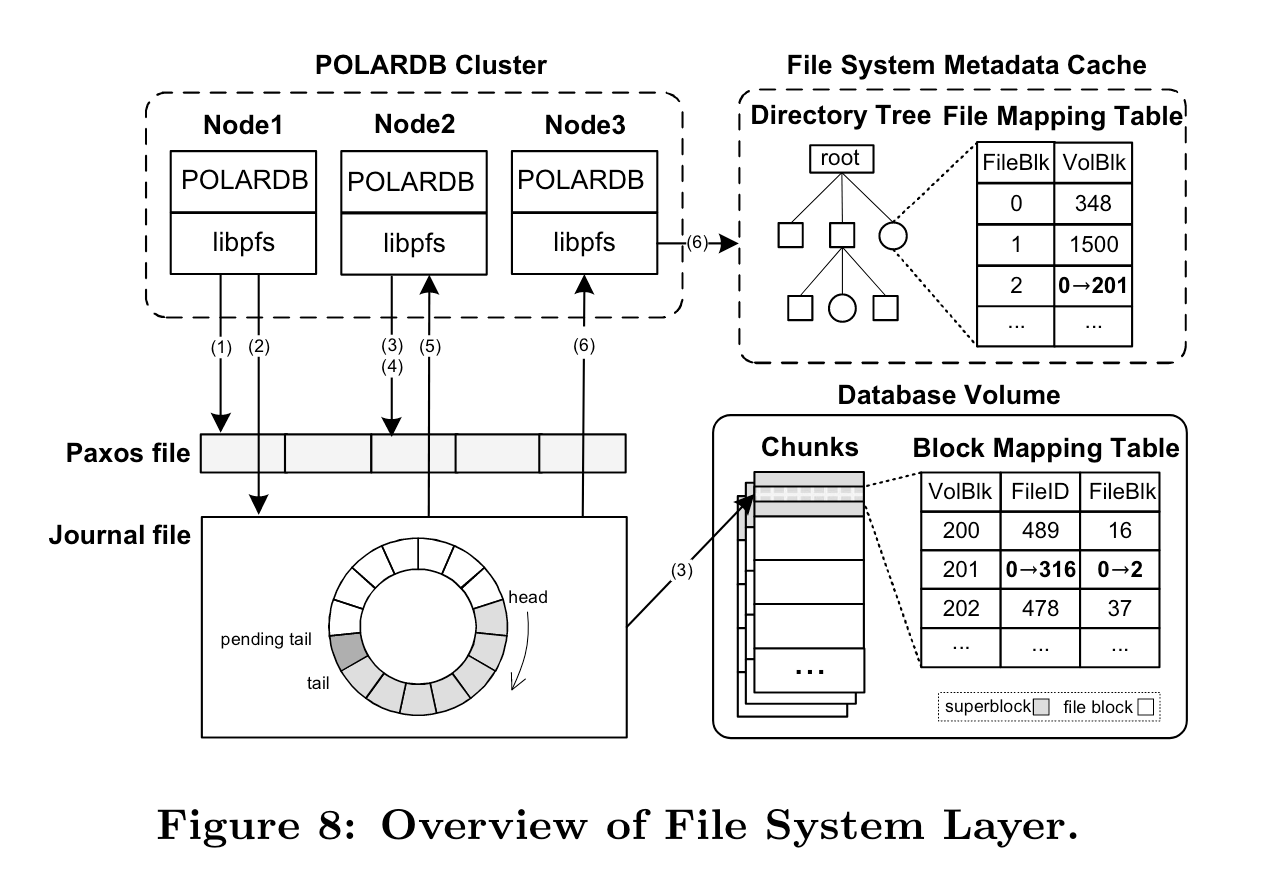
-
节点 1 在将块 201 分配给文件 316 后,获取 paxos 锁,该锁最初是空闲的。
-
节点 1 开始将事务记录到日志中。最新写入条目的位置用pending tail表示。存储所有条目后,pending tail将成为日志的valid tail。
-
节点1用修改后的元数据更新superblock。同时,节点 2 尝试获取节点 1 已经持有的互斥锁。节点 2 必定会失败,之后retry。
-
在节点 1 释放锁后,节点 2 获取lock,节点2发现本地缓存的meta cache过期。
-
节点2扫描新条目并释放锁。然后节点 2 回滚未记录的事务并更新本地元数据。最后节点 2 retry txn。
-
节点3开始自动同步元数据,只需要加载增量条目并在本地内存中重播即可。
笔者注:反正journal file都是append only的,superblock更新完,记录下一致性点,通知到另外两端(或者另外两端polling也可以)直接load就行了,为啥要搞“串行”lock?
DESIGN CHOICES AND LESSONS·
1. 中心化和去中心化·
GFS和HDFS采用中心化节点,但是中心化节点容易称为瓶颈。
Dynamo是去中心化实现,但是系统比较复杂。
PolarFS是个折中方案,PolarCtrl是中心化组件,ChunkServer则是去中心化组件(跑了Raft,实际上io还是有中心化的思想在里面,leader可能是瓶颈)。
2. Snapshot·
PolarFS实现了文件系统层面的Snapshot,PolarDB可通过该Snapshot结合一些log(用于事务回滚,或者提交)来恢复一致性状态。
PolarFS实现的Snapshot的方式:
- 打快照不会block io request
- 当user发起snapshot请求, PolarCtrl将通知PolarSwitch来生成快照,从该时刻之后,PolarSwitch会添加一个snapshot tag,用于表明host在该快照点之后的io request(笔者注:估计类似一个序列号),并且会将snapshot tag随着io request转发到chunkserver,chunkserver收到带有snapshot tag的请求后,会先打快照(可能是并行的),再处理请求。只不过打快照是很轻量的操作,具体而言,chunkserver会copy一份block mapping的meta信息,之后的通过COW的形式处理io 请求。 当request with snapshot tag完成后,PolarSwitch停止给io request添加snapshot tag。
这里不太理解,snapshot是copy完block mapping后才处理io? 那COW的意义是什么? 如果是触发copy后的修改通过COW的形式处理倒是可以,那为什么完成request with snapshot tag完成后,PolarSwtich才会停止添加snapshot tag? 意思是说这之间的request都会带上snapshot tag?
评估实验·
实验对照组:本地Ext4和CephFS
测量指标:吞吐量和时延
时延结果·
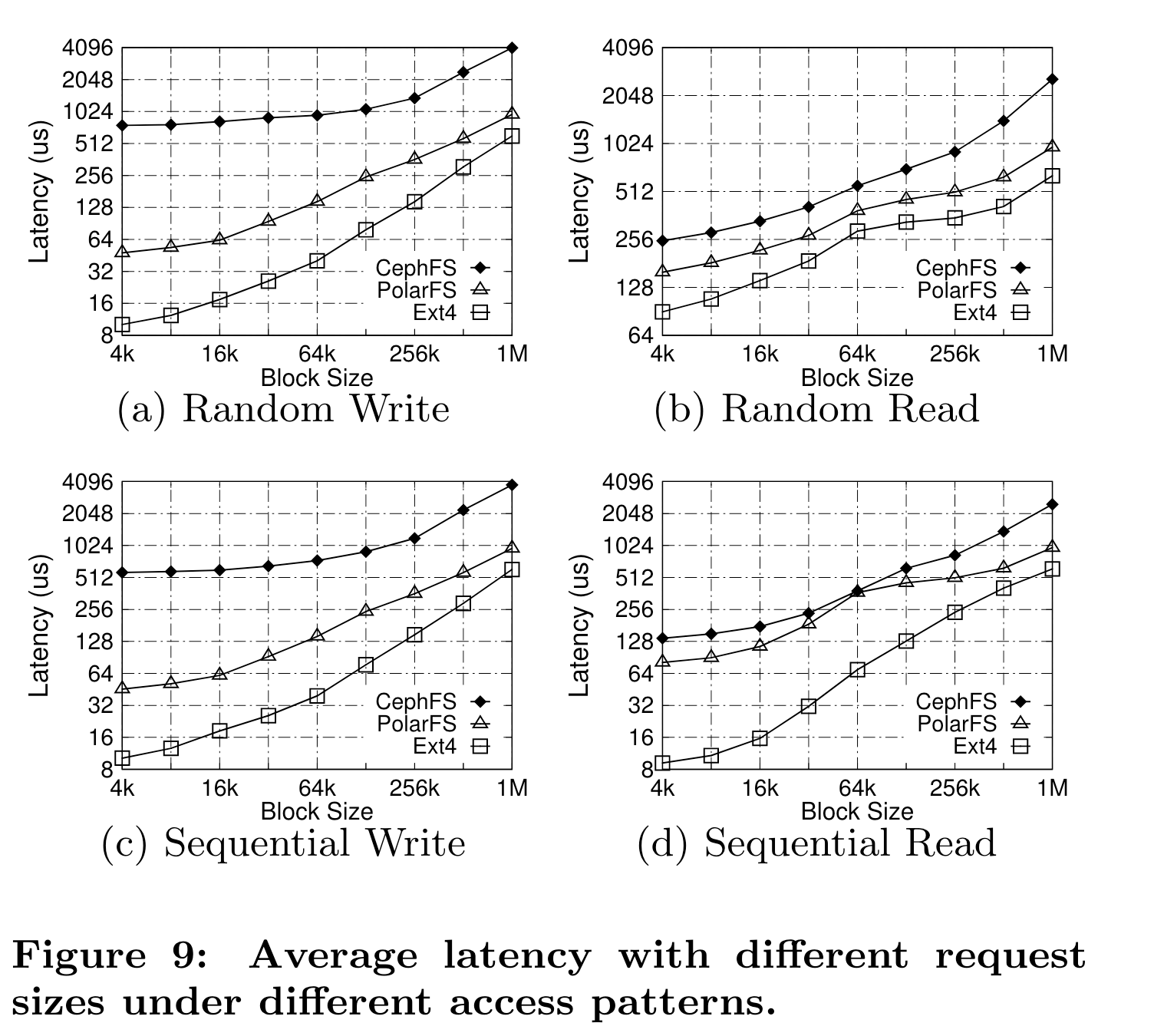
PolarFS优于CephFS,和Ext4相比在小size io下有差距,但是大io size接近。
PolarFS相比CephFS更好的原因在于:
- PolarFS io只由一个thread处理,避免了context switch(CephFS是多线程+pipeline)
- PolarFS使用内存池,避免object频繁构建和析构,使用大页减少TLB miss
- 所有的元数据data都缓存在内存中
- PolarFS使用RDMA和SPKD, 而CephFS使用TCP/IP和block driver
笔者注:都是些工程优化,从架构上看不到特别明显的优点,不过这毕竟是18年的文章
吞吐结果·
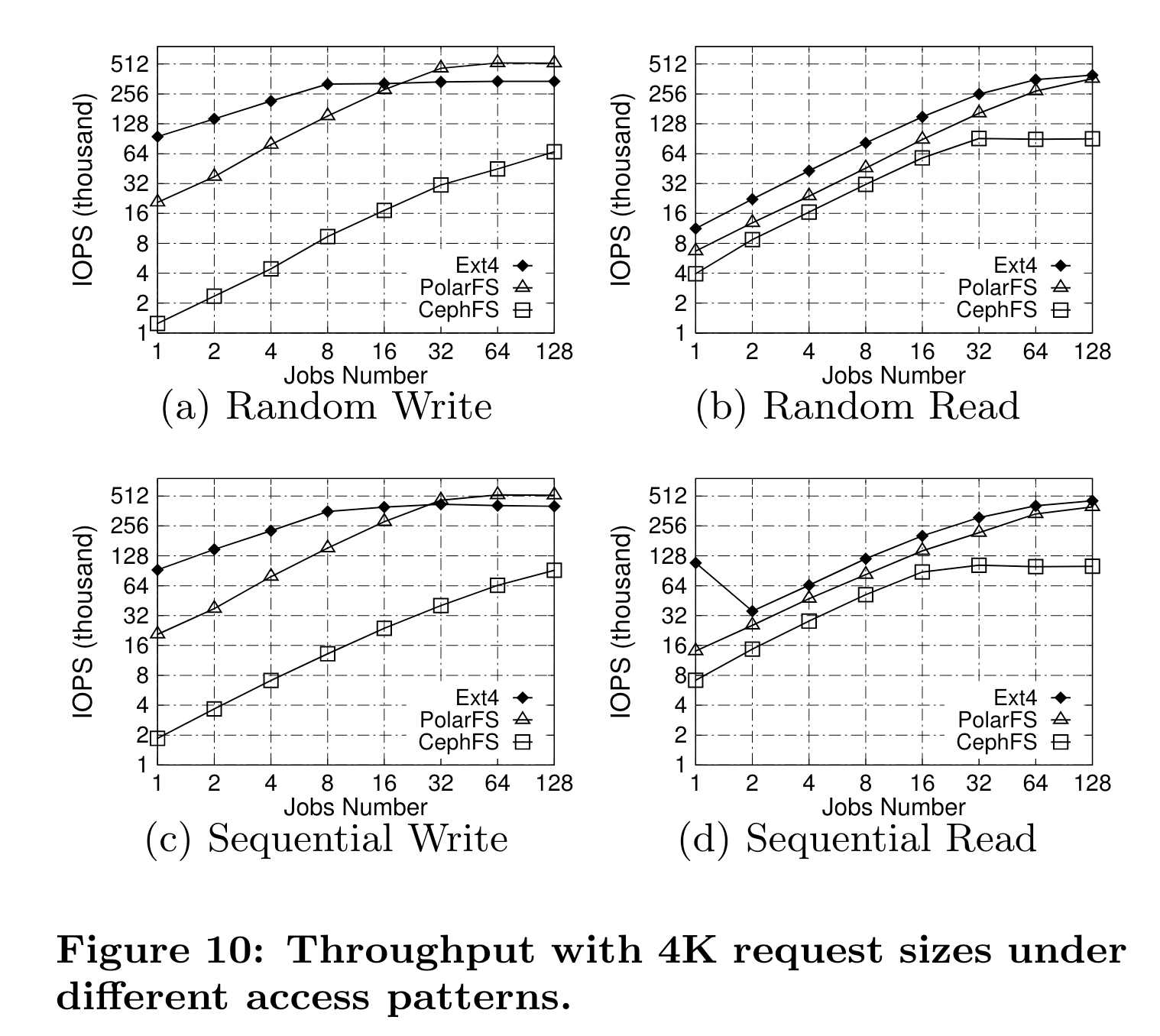
scalability瓶颈:ext4是本地盘的iops,polarfs是网络带宽,cephfs则是packet processing能力。
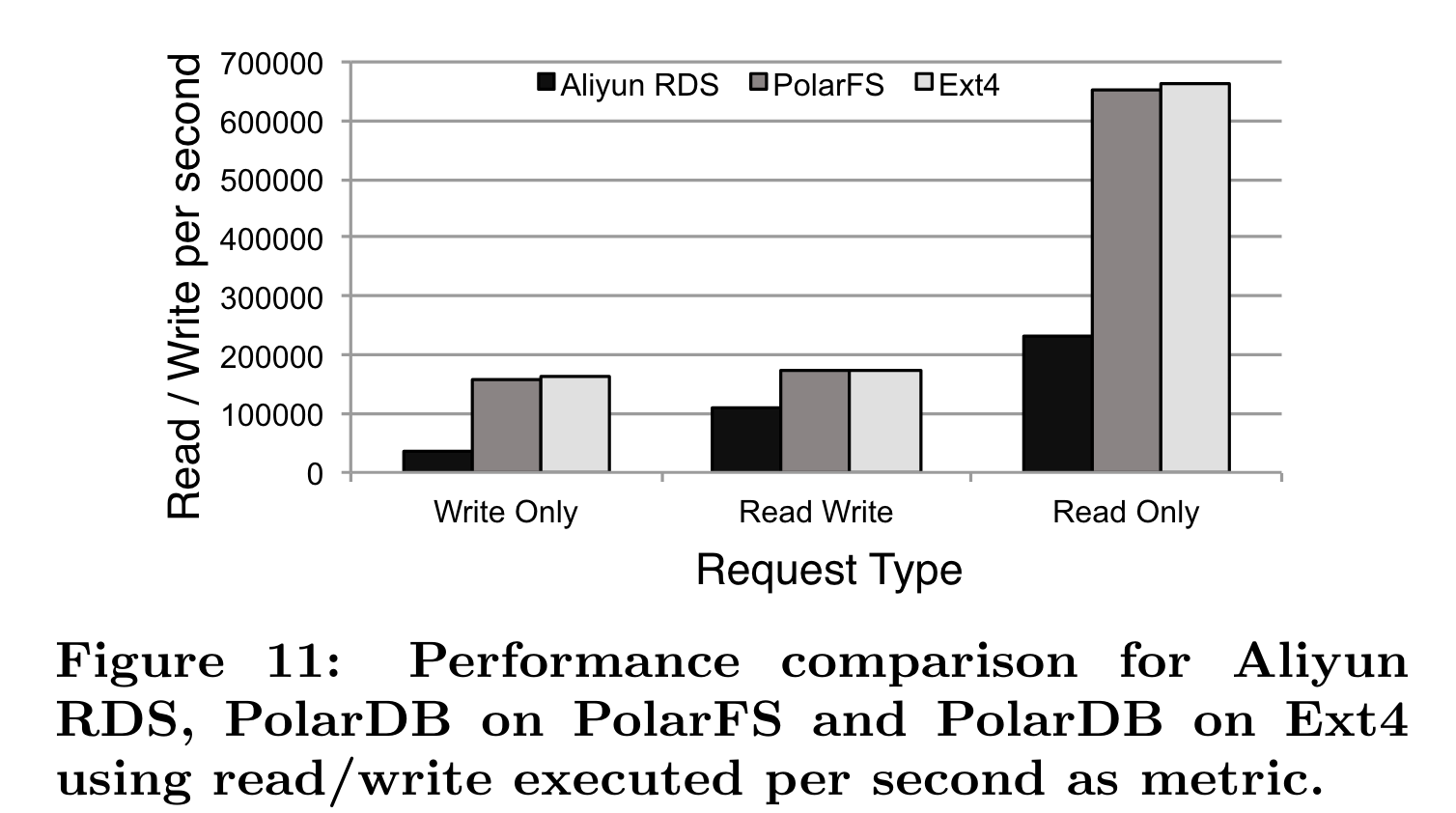
PolarDB·
实验对照组: PolarDB on PolarFS, PolarDB on ext4, RDS。