原名: Socrates: The New SQL Server in the Cloud
用户期望: 高可用、安全、scalability、弹性。但传统架构无法满足这些要求。
答案是上云。
笔者注:虽然上云似乎越来越被证明是伪需求了。
socrates是微软推出的云原生数据库架构,和Aurora一样,也是存算分离的, 同样遵循log is database的设计原理。log存储和数据(page)存储分离,log保证durability,page保证availability。
(a) In contrast to availability, durability does not require copies in fast storage; (b) in contrast to durability, availability does not require a fixed number of replicas.
持久化保证的是不丢数据,所以通常需要多副本。 可用性保证的是服务质量,要做到快速恢复,所以需要fast storage。
下表展示了Socrates目前在各维度上达成的目标:
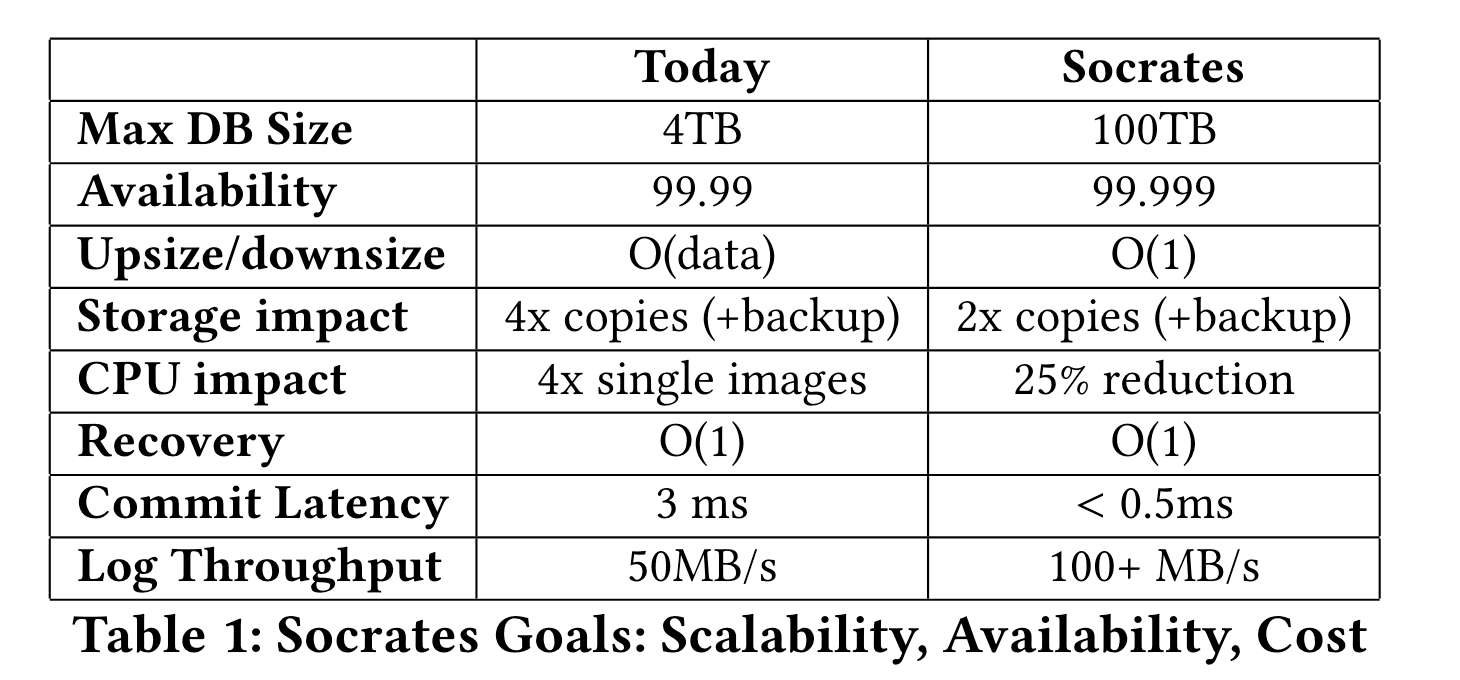
全文描述的如何达成上述目标。
现有成熟架构·
1. HADR·
HADR是微软家的老架构,架构图如下:
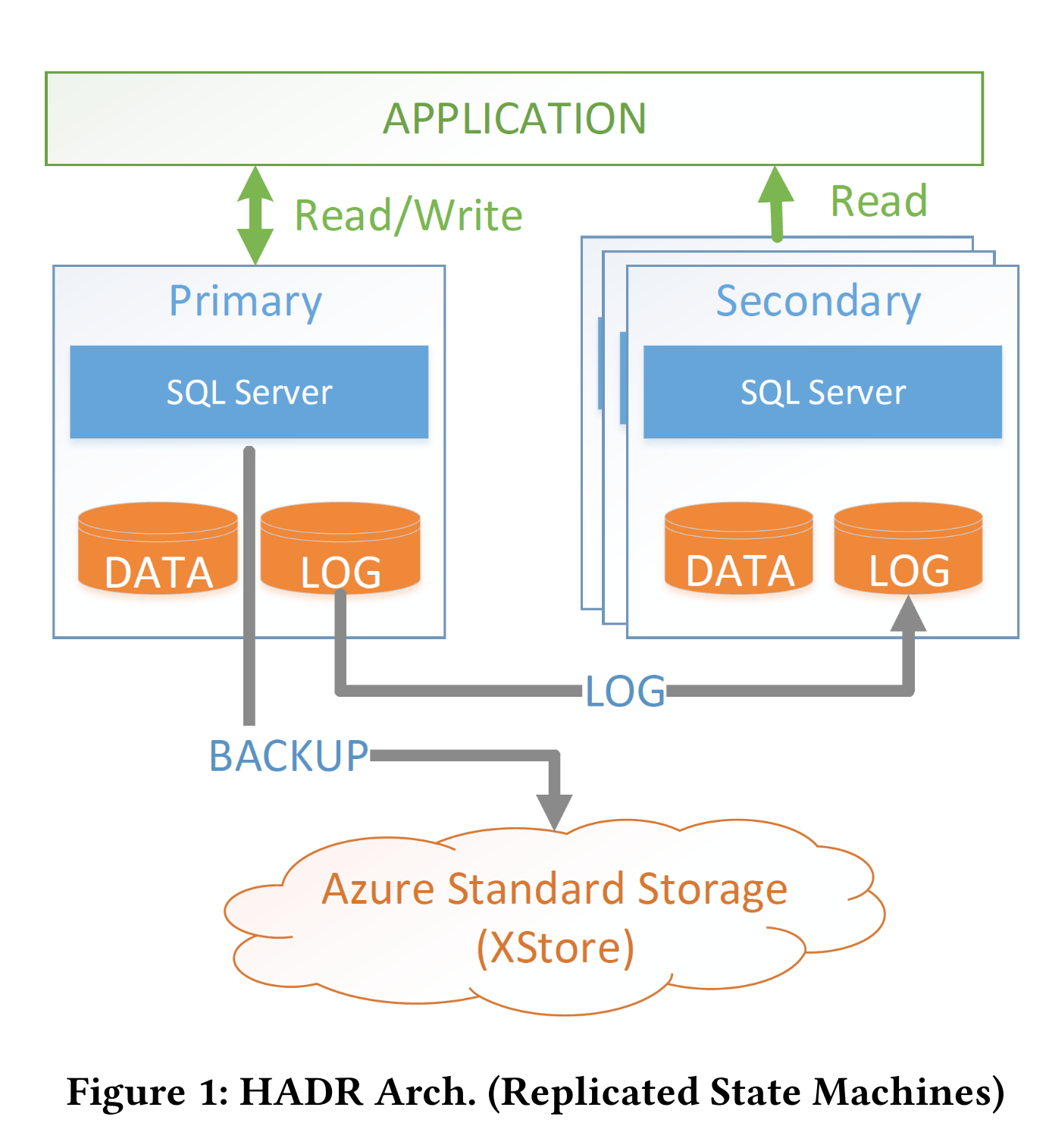
primary是读写,secondary是读only的,主备的同步是通过log shipping。
笔者注:数据的持久性需要保证log shipping也完成,时延效果如何?笔者没做过传统架构的研发和测试。
HADR采用一主三备的模式,用于保证可用性。这种架构的明显缺点有: 1. 每个节点都有全数据,但节点的容量上限限制了用户实例大小, 容量scalability不太行。 2. 空间占用过大,成本过高。 3. scale一个节点的速度和 data size强相关。
其余架构还有 Spanner、 Aurora、pioneer。
构建基础·
socrates的构建实际上是复用了很多SQL server就有的服务,包括:
1. page version store·
page MVCC的存储。 HADR的多版本是存放在本地的,socrates保存在共享存储层。
2. ADR: accelerated database recovery·
在ADR之前,sql server采用ARIES-style的恢复流程,过程包括: 分析日志–apply redo–undo failed txn. 其中undo日志的size是不控的。 使用共享的MVCC存储(后台会周期checkpoint)后,恢复过程可以消除undo阶段,只留下 分析日志-apply redo的过程。 由于有周期checkpoint,所以整个恢复时延可控。
笔者注: 这点和Aurora是一样的。
细节未知,个人认为undo依然存在,靠后台回收这些没有提交的事务。 暂不清楚ARIES-style的undo 日志是怎么用的,是否可以转后台?
3. resilient buffer pool extension(RBPEX)·
BPE (Buffer pool extension) 是sql server 2012实现的功能,将buffer pool在SSD中维护一份镜像,和内存的buffer pool有一样的生命周期(当前除了掉电不丢失)。 Socrates扩展该功能,实现了resilient。 该功能在计算层和存储层都使用,用于快速恢复,避免冷启动(升级、重启)时,buffer pool需要重新注入的阶段,减少MTTR,提升可用性。
该功能底层使用了微软的Hekaton, 内存存储引擎实现。
笔者注:使用共享内存可以达到类似的效果,共享内存解决重启问题,但是无法解决机器掉电问题。
4. RBIO协议 (Remote block I/O protocol)·
微软家自实现的网络协议,特点: 无状态,错误透明、qos support。 还有两个笔者不理解的功能: strongly typed, automatic verioning。
5. Snapshot Backup/Restore·
由于数据文件存在 XStore 中, XStore是log-structured的存储系统,所以搞snapshot很简单,抽象为记录一个pointer指向log流即可。 所以打快照是非常快的额,且与data size无关。socrates的PITR基于XStore实现。
笔者注: 感觉云存储里, log-structured 有些一统江湖的感觉。
6. I/O stack 虚拟化·
SQL Serever使用 FCB(File Control block)抽象IO层,sql server可接入不同的文件系统、存储平台。好的抽象使得接入socrates时,计算层的core改动很小。
Socrates架构·
1. 设计目标和原则·
本节为微软在HADR架构下得到的一些lessons。
- Local Fast Storage vs Cheap Scalable Durable storage. SSD for high performance。 cheap storage(HDD) for durability and scalability. socrates架构存储是分层架构, 管理不同的存储设别。
- bounded-time operations. 在HADR中,很多操作都是和节点size绑定的,如添加一个RO节点(这和MTTR时间强相关)。 为了避免任何 “size of data operations”. socrates架构考虑了备份、恢复,snapshot,如何存储log,如何扩容。
- from shard-nothing to shared-disk. shard-nothing架构通常每个节点都有完整的数据(如HADR),但这和第2点是冲突的,很难管理大规模数据。即使单个节点可以管理such large dataset,那其他资源也可能浪费,如一个节点的盘非常多,通常cpu也不会太差,即使盘充分利用了,cpu也可能会被浪费(说明了,弹性度不够)
- low log latency, separation of log. log是非常重要的,所有操作都需要先logged,而为了保证durability,通常还需要写入多副本,而log是在io的关键路径上的,所以需要“高性能”写log。 在socrates中,将log service单独提取出来,单独优化保证性能。 如使用优化后的 quorum协议保证log的持久性。 (可见Table 1 commit latency相比HADR更低)。 另外,也提升了灵活性,因为log通常具有recent access的访问模式,所以对于old log可以写入冷存,new log保存在内存,即保证性能,又节约成本,又扩容log service“逻辑容量”。 此外,log service单独抽象,在存储技术不断演进过程中,还可以单独更换技术。(笔者注:不过往往都是技术或者运维债务的)
- pushdown storage funtions. 下推算子。常见技术了,不多记录。
- Reuse Components, Tuning, Optimization. 保持和HADR的兼容性、不重复造轮子。 (笔者注: 这其实非常重要,不要轻易尝试改变用户习惯)
2. 架构设计·

整体架构分为4层:
- 计算层:计算层采用一主多备架构,理论上可以无限扩展备机。 主备之间不需要同步通信。 每个计算节点在内存和SSD缓存buffer pool(用RBPEX技术),每当主机挂了,可选择一个备机替换。
- XLOG Service:xlog专用于存储log,保证高性能和好的扩展性。 只有主节点可写入,备节点主动从xlog service拉取log,异步消费。
- Page Server:每个page server负责一个page partition。 两个职责:1.给计算层提供page 读能力。2. 计算算子下推到page server,提升计算能力。 pageserver周期checkpoint page,并且备份数据到XStore。 和计算节点一样,在内存中缓存所有数据,采用RBPEX。 (笔者注:即使做了分区,但内存有这么大吗?毕竟是MVCC的,如果有超长事务呢?或许是一部分数据落在了SSD上吧,相当于OS的swap分区)。
- XStore, 底层采用cheap storage实现,应该是类似S3的服务。
笔者注:socrates的数据gc是怎么做的?感觉是需要协同xlog service、pageserver和xstore的来做page回收的。log回收应该是靠计算层推进。
计算节点和pageserver都是stateless的。 可随意宕机并重新拉起,因为数据的持久性有xlog service和xstore保证。
持久性有x log service和xstore
可用性有计算节点和page server保证
笔者注:page server的拉起速度有多快?
3. XLog service·
架构图如下:

RW计算节点将log blocks写入到 landing zone(LZ)中, LZ类似SAN,提供fast、durable storage service,保证数据的高可用。实现上,采用 Azure Premium Storage service (XIO) 实现,数据实际上是三副本。
log blocks是同步写入的,LZ需要是fast(但expensive and small的),LZ实际上是一个循环buffer,log format和SQL server的log format完全兼容,LZ支持log writer和log reader同时进行,而不需要任何同步语义(笔者注:如何实现的?类似无锁队列?毕竟append写应该是很简单的)
RW计算节点除了将log写入到LZ外,同时(并行)写入到一个XLOG process中, 向该进程的写入是尽力而为+异步。 该进程负责将log block分发给page server和ro计算节点。由于log是并行写入到LZ和XLOG process,那么是有可能XLOG先完成持久化并分发给page server和RO节点,再在LZ中完成持久化,这违反了WAL的原则,如果组件故障,那么恢复起来会发现数据状态不一致。 为了解决这个问题,向XLOG process写入时,先写到一个pending区域,只有当LZ数据持久化完成后,再通知给XLOG process,xlog将数据从pending区域移动给LogBroker,之后分发。
LogBroker接受到log block后,会将log移动到一个fixed size的本地SSD用于做cache,同时将数据写入到XStore保证持久性。XStore中提供的log服务区域称为LT(long term)。
笔者注:LZ保证快速commit, LT保证数据低成本长期持久化。 不过数据写放大也挺大的,光在XLOG Service,数据至少存了3份(LZ + Local SSD + LT)
XLOG Process同样是无状态的。LZ到XLOG process之间应该还有通道,毕竟XLOG process是尽力而为的,XLOG process的职责有两个:1.分发log。 2. 将log持久化到XStore,LZ是宝贵的,不可能无限扩展,所以数据越快持久化到XSTore越好。
再说log consumer(RO节点和page server),RO节点和page server主动从XLOG Service中pull log,XLOG service不用维护有多少个consumer,相反LogBroker维护了log在内存的hash map(可能是lsn到log数据的内存地址),如果内存中没找到,则在local ssd中寻找,如果也没找到,到LZ中找,如果LZ中都没找到,则到LT中找。
4. RW计算节点和GetPage@LSN·
socrates和本地部署的SQL server的区别包括:
- 备份、恢复、page修复、checkpoint功能,都委托给Pageserver和底层存储服务,而不是在一个进程中做。
- RW节点通过特定的virtualized filesystem machanism写入XLOG service
- 使用RBPEX
- 最大的不同的是,RW节点只保存最热的数据在本地(扩展的Buffer pool, RBPEX)
对于不在本地的page,通过GetPage@LSN rpc获取(该RPC透过FCB I/O 抽象层,使用RBIO协议)
1 | getPage(pageId, LSN) |
pageId: unique的page id,指定要读的page
LSN:要求读取的page的最小LSN,读到的page至少apply到这个LSN
笔者注: 这样Page Server会返回一个未来的page,有点奇怪的语义,为什么不是最接近该LSN(小于等于)的page?
这里的问题是,RW节点如何知道某个page用哪个LSN?RW应该总是最新的,但是RW未记录这个信息,至少不能记住所有page的lsn信息。所以RW构建了一个hash map,每个bucket记录这个bucket中的page的最大LSN,这样给定一个page,到这个bucket取最大LSN,这样至少保证该page的LSN小于等于bucket 的LSN,一定是最新的。
笔者注:如上是笔者个人的理解,不知道理解对没。原文如下:
We have not described yet how the Primary knows which X-LSN to use when issuing the getPage(X, X-LSN) call. Ideally, X-LSN would be the most recent page LSN for Page X. However, the Primary cannot remember the LSNs of all pages it has evicted (essentially the whole database). Instead, the Primary builds a hash map (on pageId) which stores in each bucket the highest LSN for every page evicted from the Primary keyed by pageId. Given that Page X was evicted at some point from the Primary, this mechanism will guarantee to give an X-LSN value that is at least as large as the largest LSN for Page X and is, thus, safe.
5. RO计算节点·
RO节点响应Read only, 和RW一样,RO不存储所有数据,只是一个cache层,也是stateless的。且与RW没有通信。RO通过消费XLOG Service来“追逐”RW的一致性状态。这里有一个问题:
由于RO是一个cache那么不是所有page数据都在RO中(既不在内存、也不在SSD中),所以如果消费了一段log,它所属的page既不在内存也不在SSD中,socrates直接忽略这段log。
另一种策略是从源端存储中拉取page并apply,这样RO的状态更接近RW,如果RW fail, failover的时候恢复更快。
采用这种策略有个race问题,如果需要的page正在由getPage rpc获取,但还未返回时,这部分log不应该被忽略,解决方案是在发出getPage请求之前,先将请求的page信息注册一下,后续到达的该page的log会排队等待,直到page加载完成。
还有一个race问题,结合getPage@LSN接口,由于主备之间通过XLOG Service同步,这之间是有gap的,所以RO拿到的page数据可能和RW的数据是不一致的(按照LSN一致,如果LSN相同,那么数据一定相同,调用同一个GetPage@LSN接口,即使一样的参数也可能返回不一样LSN的page)。
当secondary节点处理只读事务做B-tree遍历时,它本地有一个pageLSN cache用于决定对应page的位点,但这个位点可能已经过期了,因为primary上可能已经更新了这个page,这会导致数据不一致,场景如下:
- secondary用LSN 23读取B-tree节点P(本地已经apply log至23);
- P的子节点C不在本地cache中,secondary需要发送getPage(C,23)请求获取它;
- page server返回一个位点为25的page C。
如果C在lsn=24时发生了分裂,那么就和secondary节点在lsn=23时要看到的C不一致了。解决方案是遇到这种情况,secondary节点需要等待log apply线程将apply位点推过25之后,再重新从P执行遍历。(不断retry,直到成功)
6. Page Server·
page server的职责:
- 维护一个page partition,并执行log apply
- 响应GetPage请求
- 执行分布式checkpoint和备份
由于page server只用管所属自己partition的page,所以XLOG Service在分发log block需要识别log属于哪个block,这部分信息由计算节点在带外生成。
笔者注: page server的分区算法是什么?
Page Server同时使用RBPEX,但是和计算层的RBPEX略有不同,计算层cache最热的page,导致它的page是sparse的。但是Paeg Server cache less hot的pages,也就是说这部分page没被计算层缓存,这些page是dense的,(笔者注:不理解为什么是dense的),这对scan类型的操作是友好的。 同时PageServer一定程度上提高了可用性,因为即使XStore fail了,PageServer也还有全量数据,可以抗一段时间,之后的io中,没被下到XStore中的page会被记住,等待XStore恢复后,再次写入,同样的,pageserver作为XStore与上层的中间层,可以用来聚IO,将多次io聚合为一次io,充分利用XStore的高带宽属性(通常,类S3服务是低iops但是高带宽的)。
另外,RBPEX是异步(后台)启动的,PageServer不用等待RBPEX加载完成即可提供服务。
有两种扩容PageSever的方式:
- 充当一个shard 分片扩容,减少每个shard的数据大小,减少MTTR,提高可用性。论文中额外提到:PageServer管理的分区大小是128GB。
- 充当一个replica扩容,充当副本提高可用性那,一个replica挂了,另一个replica立即替换。
7. XStore·
在socrates架构中,xstore充当了传统架构中的disk, ssd充当了内存。xstore保证数据持久性,用于备份恢复,snapshot。
- pageserver周期checkpoint并写入到XStore
- 备份通过XStore的snapshot实现,snapshot可在constant时间完成。
- 恢复(PITR):找到时间点前的snapshot,确定要回放的log,将snapshot拷贝到新的blob,启动新的XLOG process分发要apply的log。
上述PITR相比HADR明显更快。snapshot更快,恢复也更快,PageServer可以立即拉起并服务,只是数据还没恢复到PageServer,PageServer需要从XStore中读取Page,时延更差(实际上对XStore的iops也是一个考验)。
讨论和部署·
socrates架构的一个显著特点是:分离 availability 和durability,提供足够的灵活性。 XLog和XStore提供durability,计算和Page Server提供availability。
其余略。
总结·
Socrates特点总结:
- 存算分离
- 持久性和可用性分离
- 可以更好的在 cost/performance/availability 中做trade off。
参考·
知乎:https://zhuanlan.zhihu.com/p/401929134

