原文名: We Ain’t Afraid of No File Fragmentation: Causes and Prevention of Its Performance Impact on Modern Flash SSDs
推翻SOSP21·
这篇paper推翻 SOSP 21 中 《FragPicker: A New Defragmentation Tool for Modern Storage Devices》 的结论:文件碎片对性能的影响主要受内核的request splitting 影响。
下图展示了什么是request splitting:
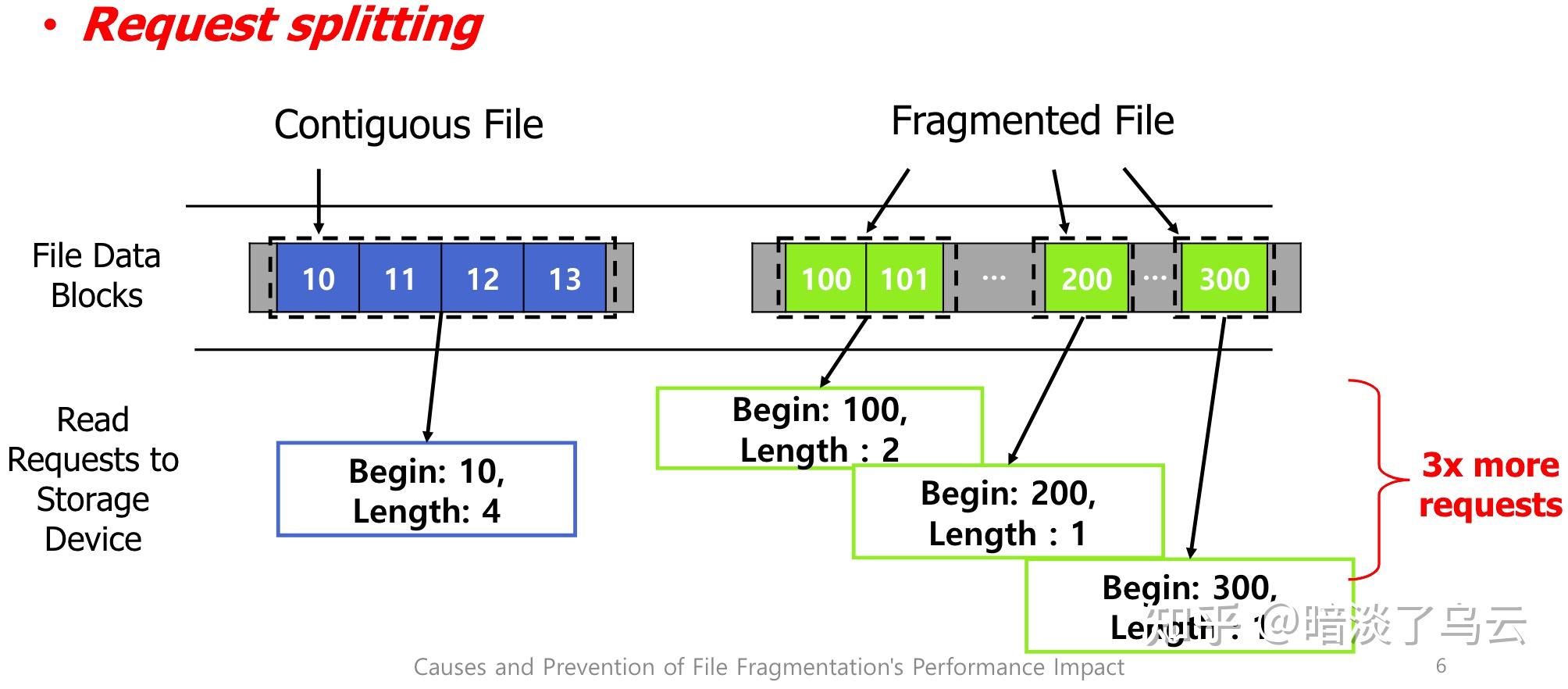
即,请求的文件分散在不同的地址,内核需要拆分为多个io,然后再merge。
作者通过做如下实验来推翻SOSP 21文章的结论:使用ram disk(ram disk可以忽略物理盘io的时间,所以cost主要在控制层面),验证在不同文件碎片程度下的读时延:
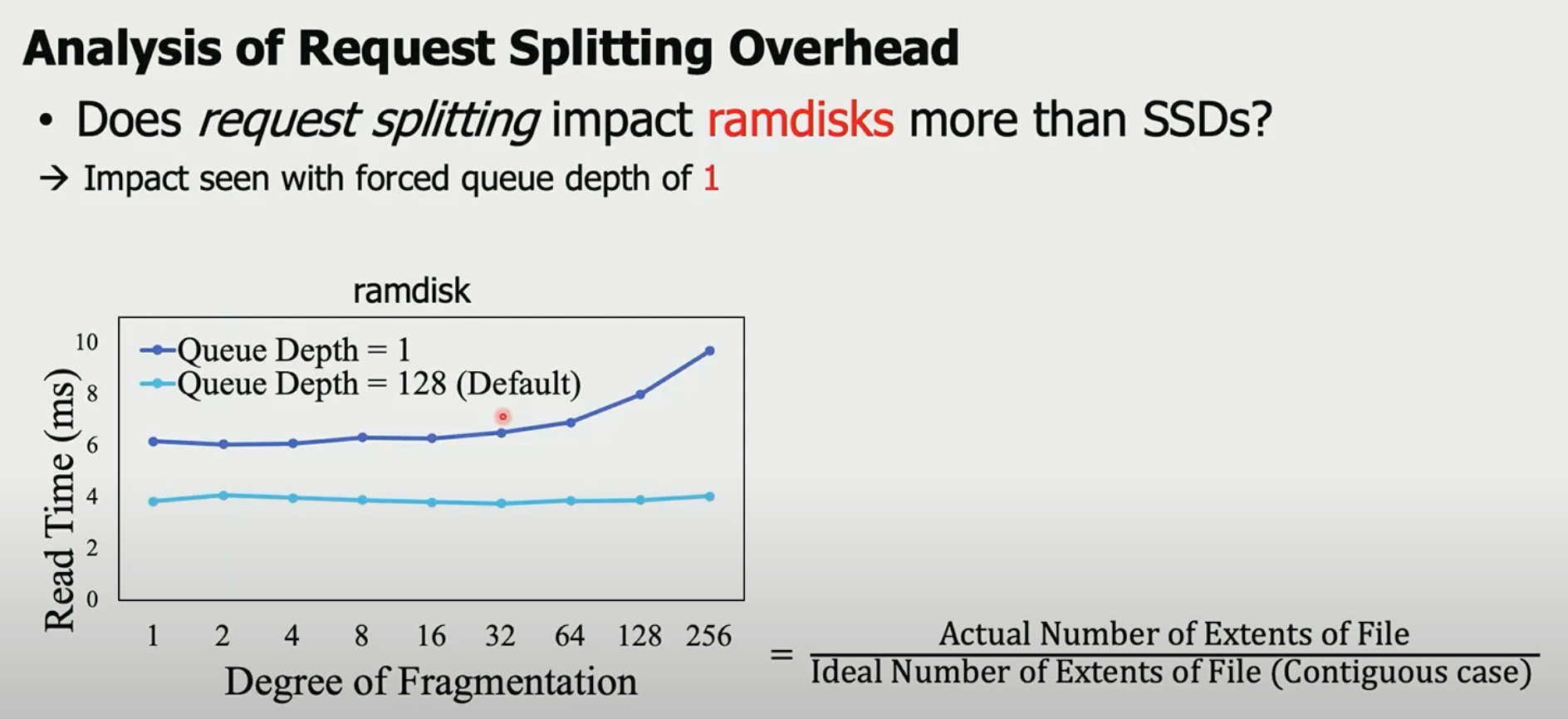
可以发现,在queue depth为1的时候(即盘处理io one by one), 碎片程度越高,cost 时间越长,这个时候受request splitting的影响很大,但是当queue depth为128时,DF对读时延几乎无影响。而现实生活中,ssd都是多depth的。
笔者注: 现实生活中ssd虽然支持多depth,但是实际使用中,depth有多少?印象中是不会太深的。
以下是“豆包”的回答:
SSD 的 IO depth(队列深度)在实际使用中能达到的值因多种因素而异,以下是一些常见的情况:
- 一般消费级 SSD
- 在日常普通应用场景下,比如办公软件使用、网页浏览等,IO depth 通常较低,可能在 1 到 4 左右。因为这些场景下主要是随机的小文件读写操作,系统不会同时发起大量的 I/O 请求。
- 在一些较为复杂的个人应用场景,如视频编辑、游戏等,对存储设备的读写请求会更频繁和复杂,IO depth 可能会上升到 8 到 16。例如在玩大型游戏时,游戏程序需要不断地读取和写入游戏数据、存档等信息,会产生一定数量的 I/O 请求队列。
- 企业级 SSD
- 企业级应用通常对存储系统的性能和并发处理能力有更高的要求。在数据中心、服务器等场景中,多线程、多任务的并发操作很常见,IO depth 可能会更高。一般来说,企业级 SSD 在较为理想的情况下,IO depth 可以达到 32 甚至更高。
- 在高并发的数据库应用中,大量的事务处理和数据查询会产生大量的 I/O 请求,此时 SSD 的 IO depth 可能会保持在较高水平,以满足系统的性能需求。对于一些关键业务系统,为了保证数据的快速读写和响应,会对存储系统进行优化配置,使 SSD 的 IO depth 尽可能地提高。
进一步地,用真实的ssd来验证:
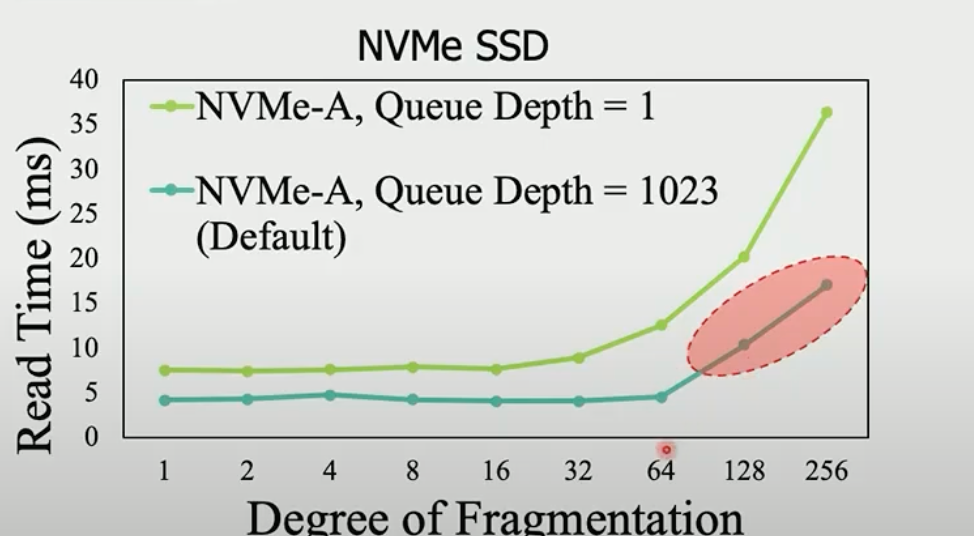
depth=1可以不关注,ssd不会用depth1的配置,主要看1023的case,可以发现在DF>64时,read cost的确上升了,这验证碎片验证到一定程度后,盘本身的“某种机制”导致了碎片会降低盘性能,而不是request splitting。
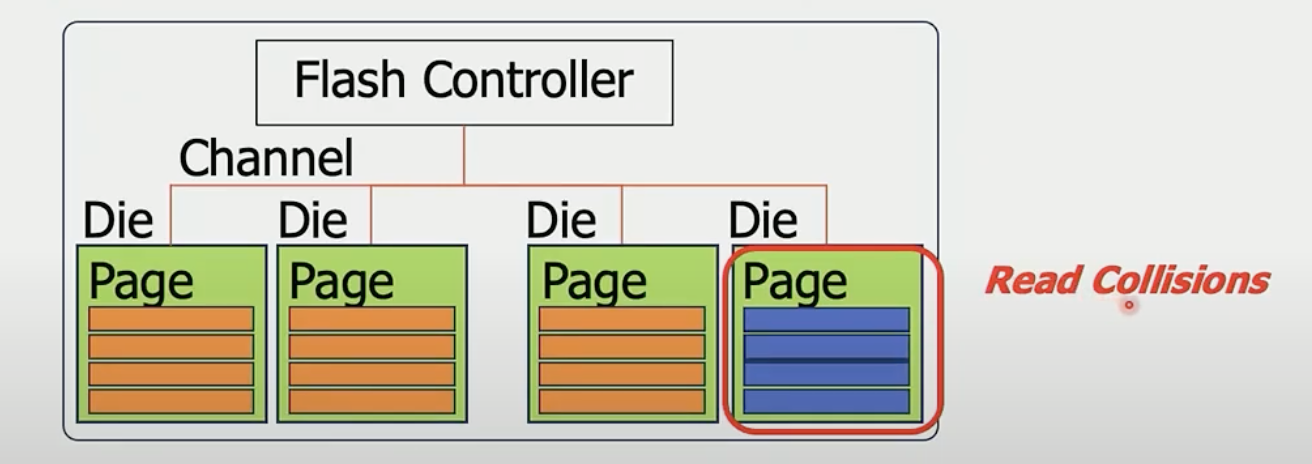
ssd盘的基本架构图·
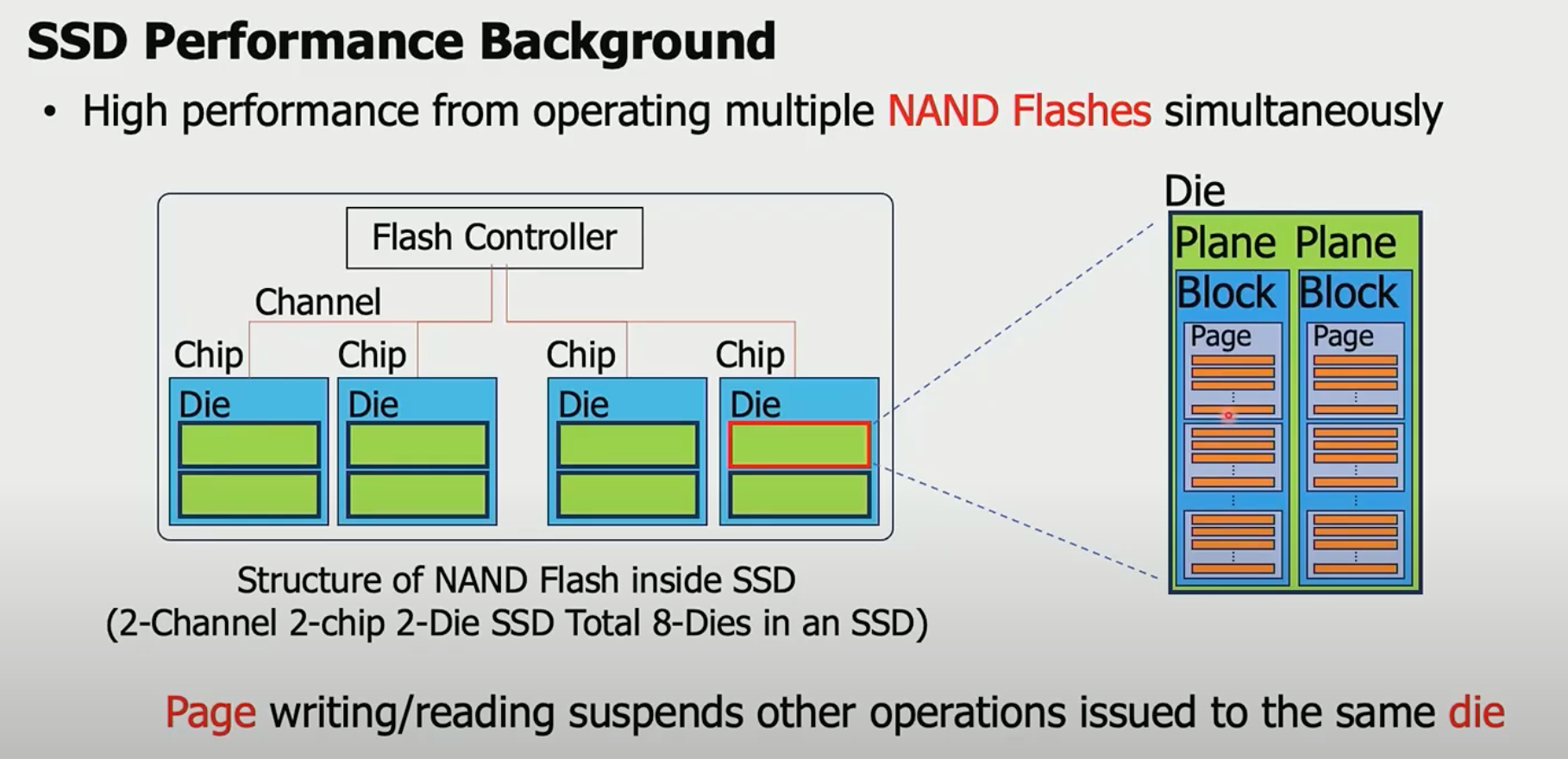
ssd的组成:
Flash 控制器 -> Channel -> Chip -> Die -> Block -> Page
- io并发是以die为粒度的,同一个die只能同时处理一个write/read
- page是最小的可写、可读单元
- block是最小的擦除单元(盘gc)
所以在处理io时, 尽可能让io分散在不同的die,充分利用盘的并发性, 本文的核心。 如果要读的io都在同一个die下,那么只能顺序处理,这被称为read collisions:
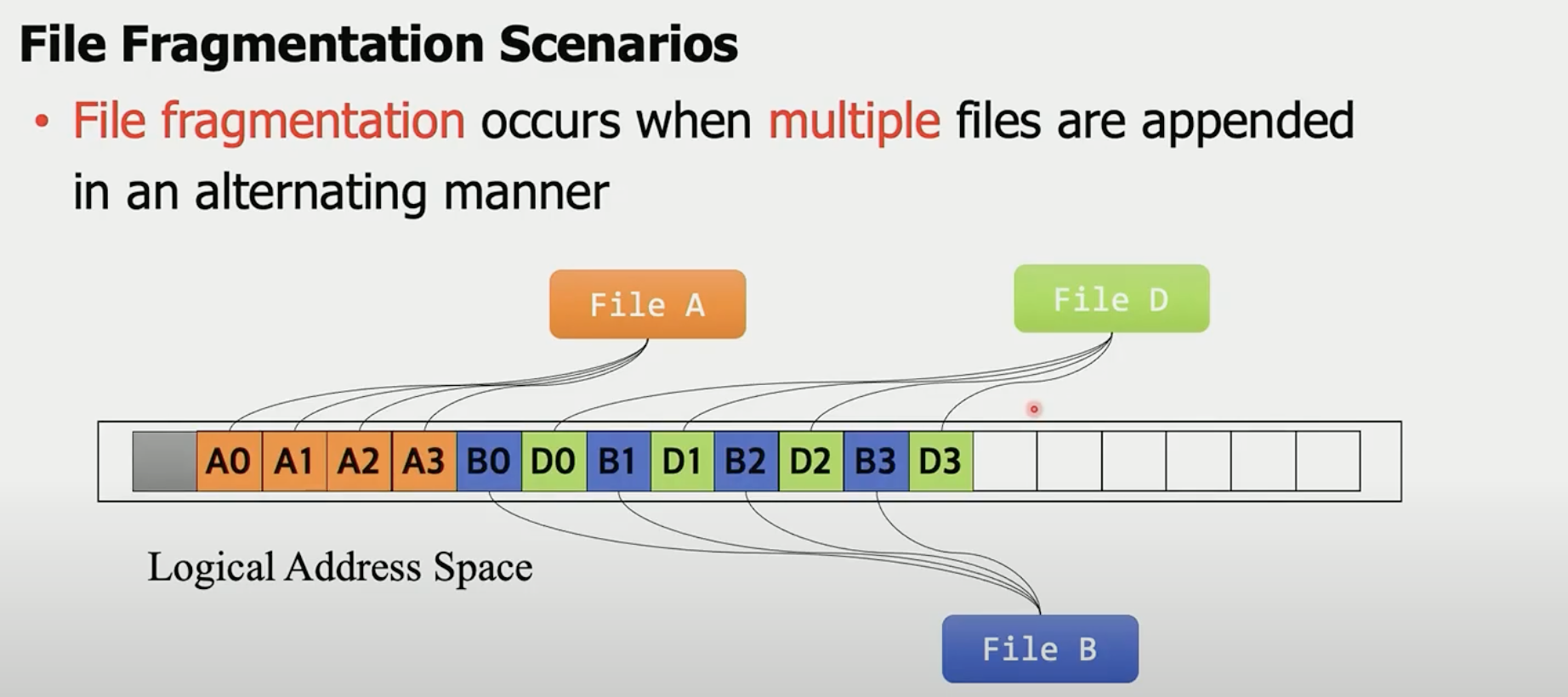
文件碎片产生的场景·
多文件交错使用LBA。如果只有A append,那么LBA地址是连续的。如果B和D同时append,则交替使用LBA,造成文件碎片。
笔者注:
- 是不是可以通过预留LBA的方式,可以保证一定的连续性?
- LBA连续了,不一定代表盘要连续, 毕竟还有FTL。还是说两者之间有一定的关联。
文件碎片带来read collisions·
在盘层面,写命令是按照die level round robin的:
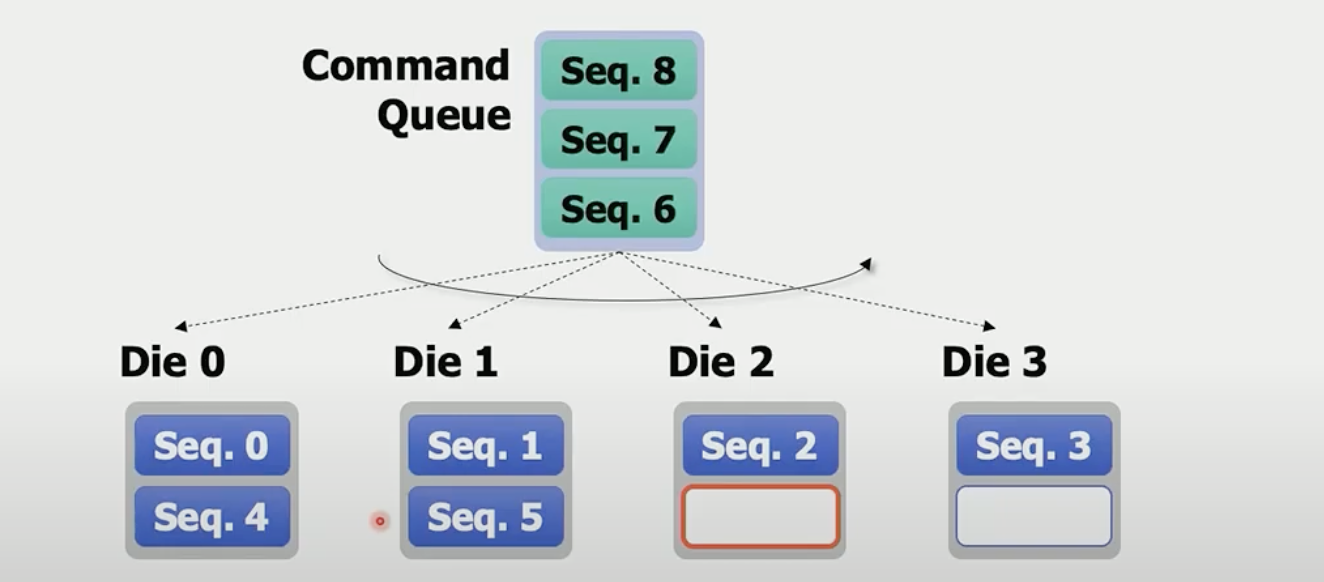
这种机制,会导致文件分片落到了相同的die上,如下图:
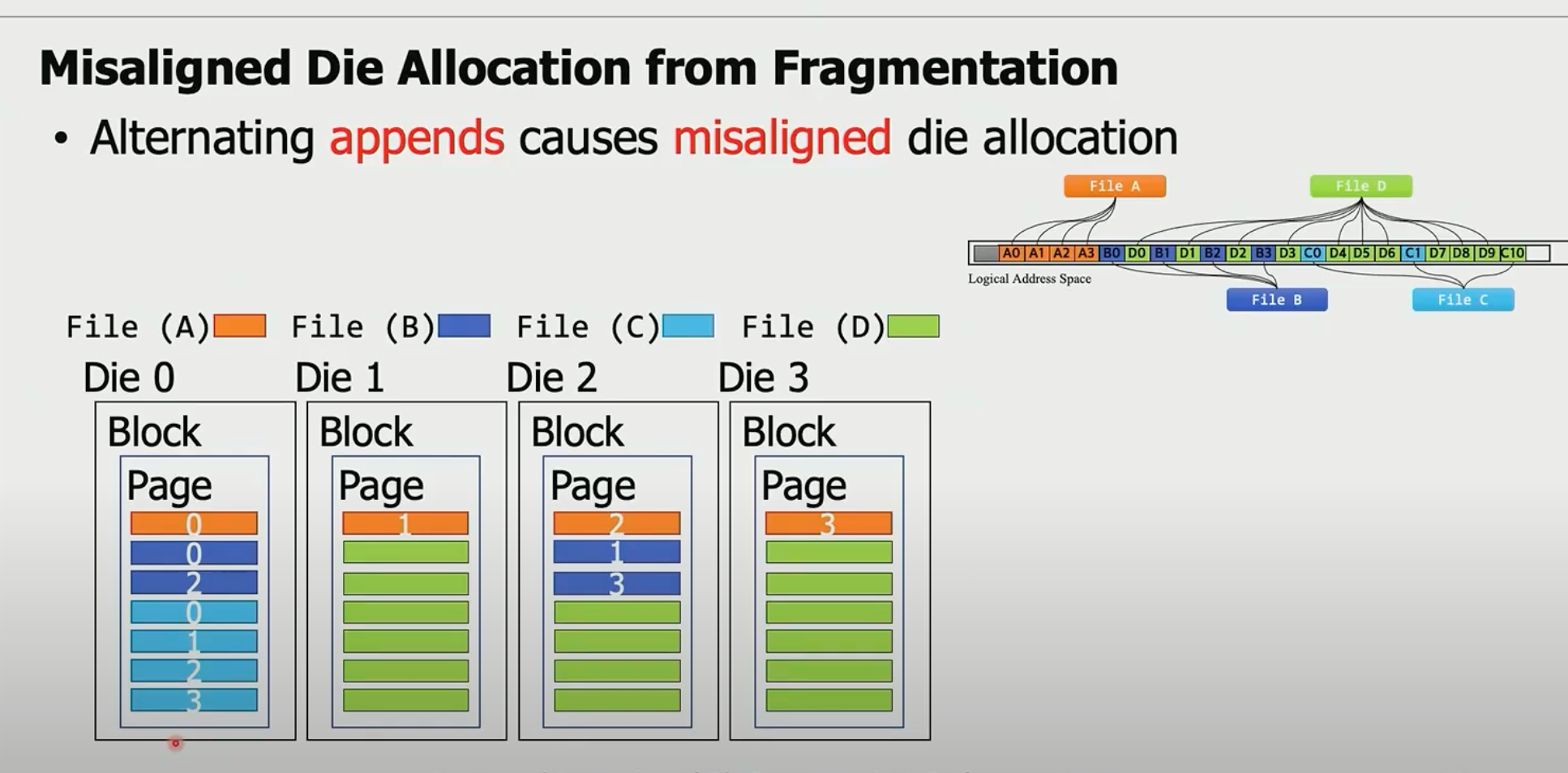
文件碎片会带来read collisions.
文章方案·
方案非常简单,“尽可能让不同文件的分配在不同的die”:
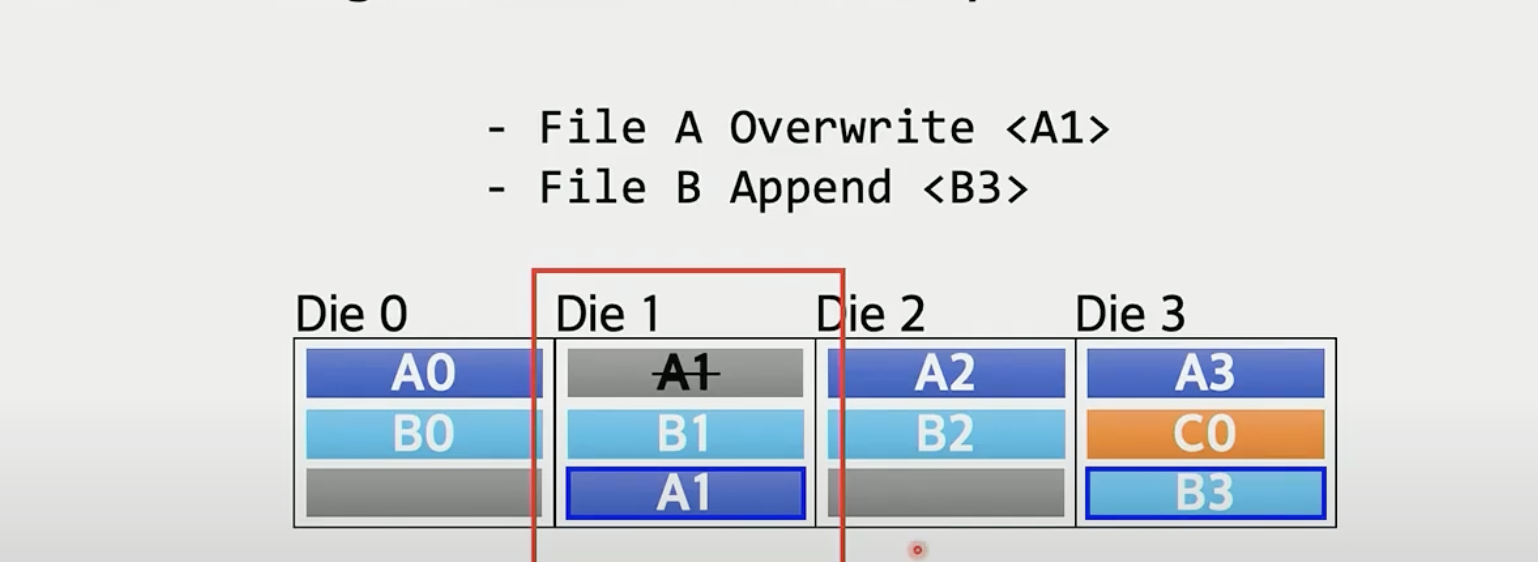
如上图的A1覆盖写,还是分配在A1. 新增B3,由于B0 B1 B2已经占据了Die 0 Die 1 和Die 2, 所以直接分配在Die 3。
笔者注: 所以他们是改了盘控制器?另外如果有热点问题如何处理?盘控制器复杂度提升后,是否影响iops?die粒度控制感觉很粗。
方法,打通文件系统到盘之间的通道,然盘感知写入命令是写的哪个文件,特别的:
- 对于overwrite操作,直接写到上次写的die上
- 对于append操作,写到和上一次写相邻的下一个die上。
评估·
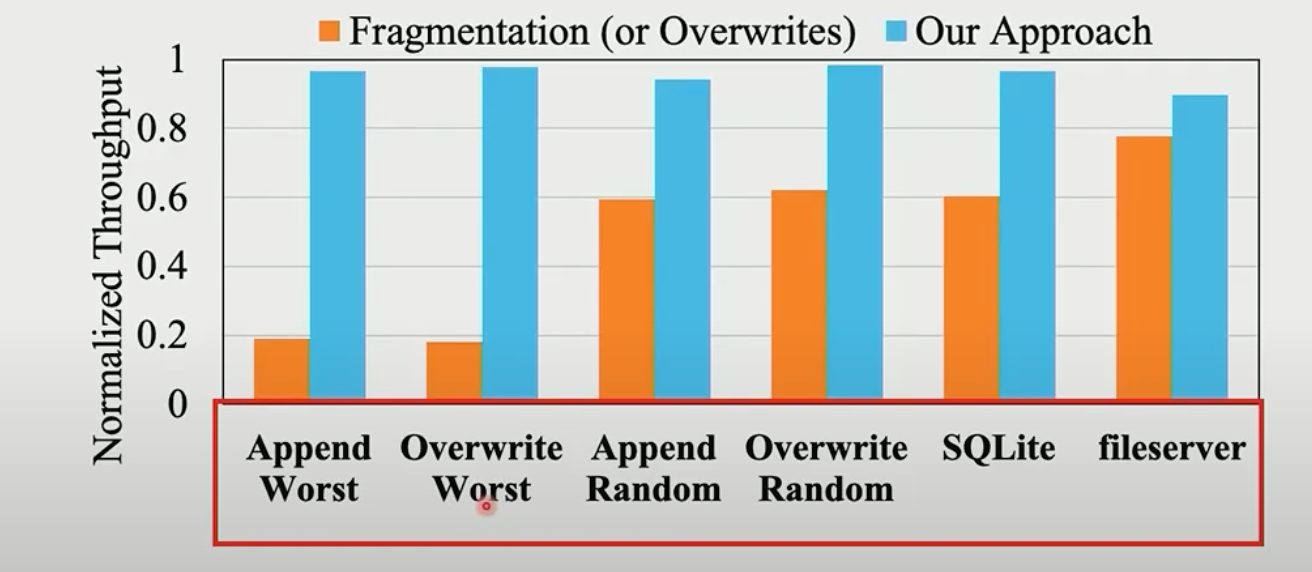
一些结论·
盘的性能应该从两方面考虑: iops和带宽。
SOSP 21和本文其实都是在关注iops。
SOSP 21说是由于request splitting 导致的盘性能衰减,这是因为文件碎片程度高,拆分多个io,耗费了更多盘iops,从而导致了iops瓶颈。
本文其实也是类似的,由于die level冲突,导致无法达到盘的峰值iops,所以要尽可能的提高并发(类似软件开发中,尽可能做到免锁)。
文件碎片造成SSD性能退化,其实有3个原因:(1)io size变小,io number增加,IO在内核拆分和合并开销;(2)die-level conllisions造成相同IO size下,iops性能的退化(3)io size变小,导致SSD iops到达上限,无法跑满带宽。
参考·
- youtube视频: https://www.youtube.com/watch?v=BV23FOP1nFU
- 知乎文章: https://zhuanlan.zhihu.com/p/693732364

