原文名: What’s the Story in EBS Glory: Evolutions and Lessons in Building Cloud Block Store

Introduction·
EBS1
特点: in-place update 和 VD的独立管理。
缺点: 热点问题、空间放大和性能瓶颈
EBS2:
特点:使用log-structured design和VD的segment分片,添加后台EC和压缩
优点:空间放大减少,从3减少到1.29
缺点:网络放大
EBS3:
特点:在线EC + Fusion Write Engine(FWE) , 聚合多个segment来凑EC条带和压缩。卸载压缩到FPGA
优点: 空间占用继续减少,从1.29减少到0.77。网络放到从4.69降到1.59
EBSX:
特点:使用PM和独立IO线程,减少平均时延和尾时延,尽可能使用用户态计算。
架构演进·
EBS1·
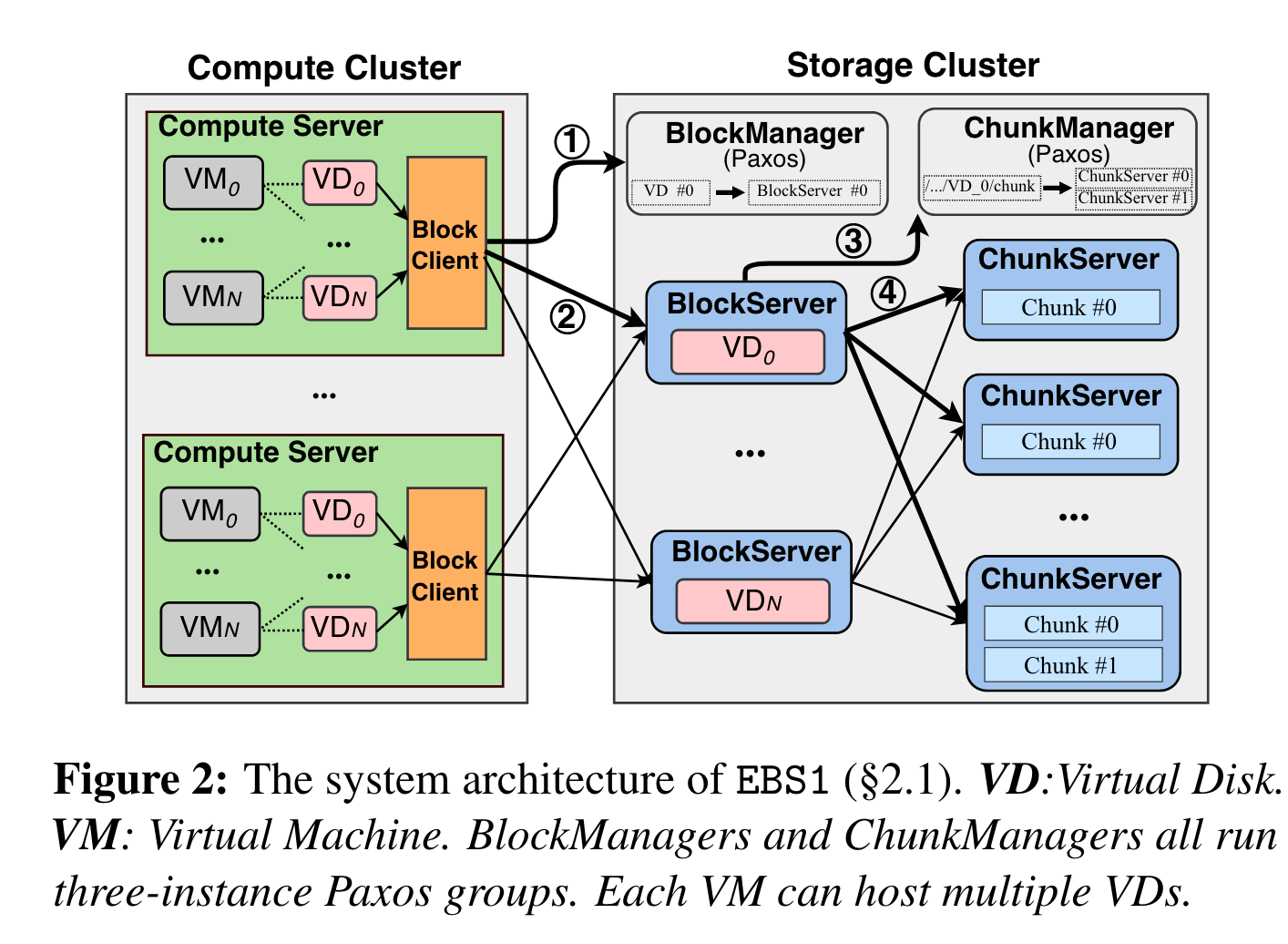
架构:
计算测:每个block client管理多个vd
存储侧:
- block manager,paxos协议+3 nodes,管理VD的元数据,如容量、版本snapshot,为block server分配VD,block server故障时,failover重分配VD到其它block server
- block server,vd io处理终端
- 地址划分:将LBA划分为多个64M组成的chunk
- chunk manager,paxos协议+3 nodes,管理chunk的元数据,每个chunk 3副本
- chunk server,chunk io处理终端, 64M的chunk落盘实际采用64M的ext file。 只在user写数据时,才分配数据。
网络:
- 10Gbps + kernel的TCP/IP stack
数据流: 发起一个vm io的流程如下:
- Block Client 请求BlockManager,询问VD所在的Block Server
- Block Client根据返回的Block Server,访问对应的Block Server,同时缓存VD-> BlockServer 的mapping
- Block Server询问ChunkManager,分配的3个chunk所在的chunk server位置
- Block Server根据返回的location去持久化数据,同时缓存 chunk -> chunkserver的mapping
优点:
- 存算分离
- 简单、直接
缺点:
- 空间放大严重,由于 in-place update的策略,难以做压缩和EC
- N to 1的mapping关系,让一些热点VD所在block server成为性能瓶颈
- HDD + kernel TCP/IP的部署,性能不行。
- 故障域较大,一个blockserver挂了,上面的所有VD都挂了,需要重新拉起新blockserver,或者由blockManager重分配
EBS2·
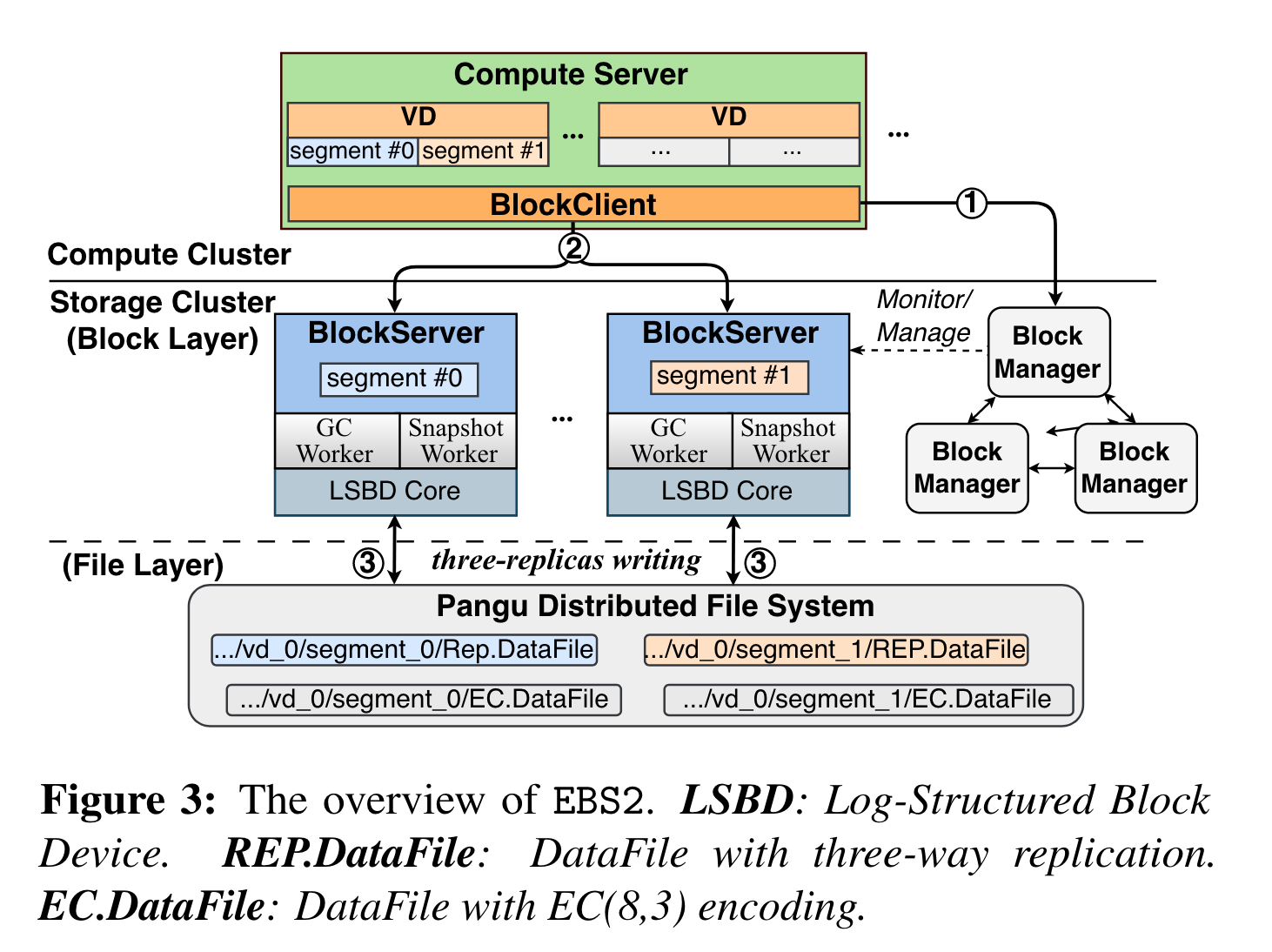
架构:
计算侧:VD下划分多个segment
block storage layer: block server之间不通过共识协议选主,而是通过盘古分布式文件系统提供的分布式lock进行选主。 block manager 管理VD到segment之间的映射。
盘古分布式文件系统: 提供append only的写语义,3副本保证高可用。 append only让做compression和ec都方便了很多。
数据流:
- BlockClient首先从BlockManager中查找VD LBA到segment的地址(图3中的1⃝,可以通过cache跳过)
- 将I/O请求转发到目标BlockServer(2⃝)
- BlockServer 采用Log-Structured Block Device (LSBD) Core 将 I/O 请求转换为盘古 API,然后调用盘古sdk来持久化或获取数据 ( ③)。自 EBS2 起,BlockServer 和盘古的 ChunkServer 虽然位于同一物理服务器上,但在逻辑上是独立的进程,并且依赖后端网络来传输数据(即不强制两组件的部署)。 (笔者注:但是如果是两个都在同一个本地就没必要走网络了吧,共享内存之类的IPC明显快很多,就看这部分io是不是瓶颈了
segment划分:
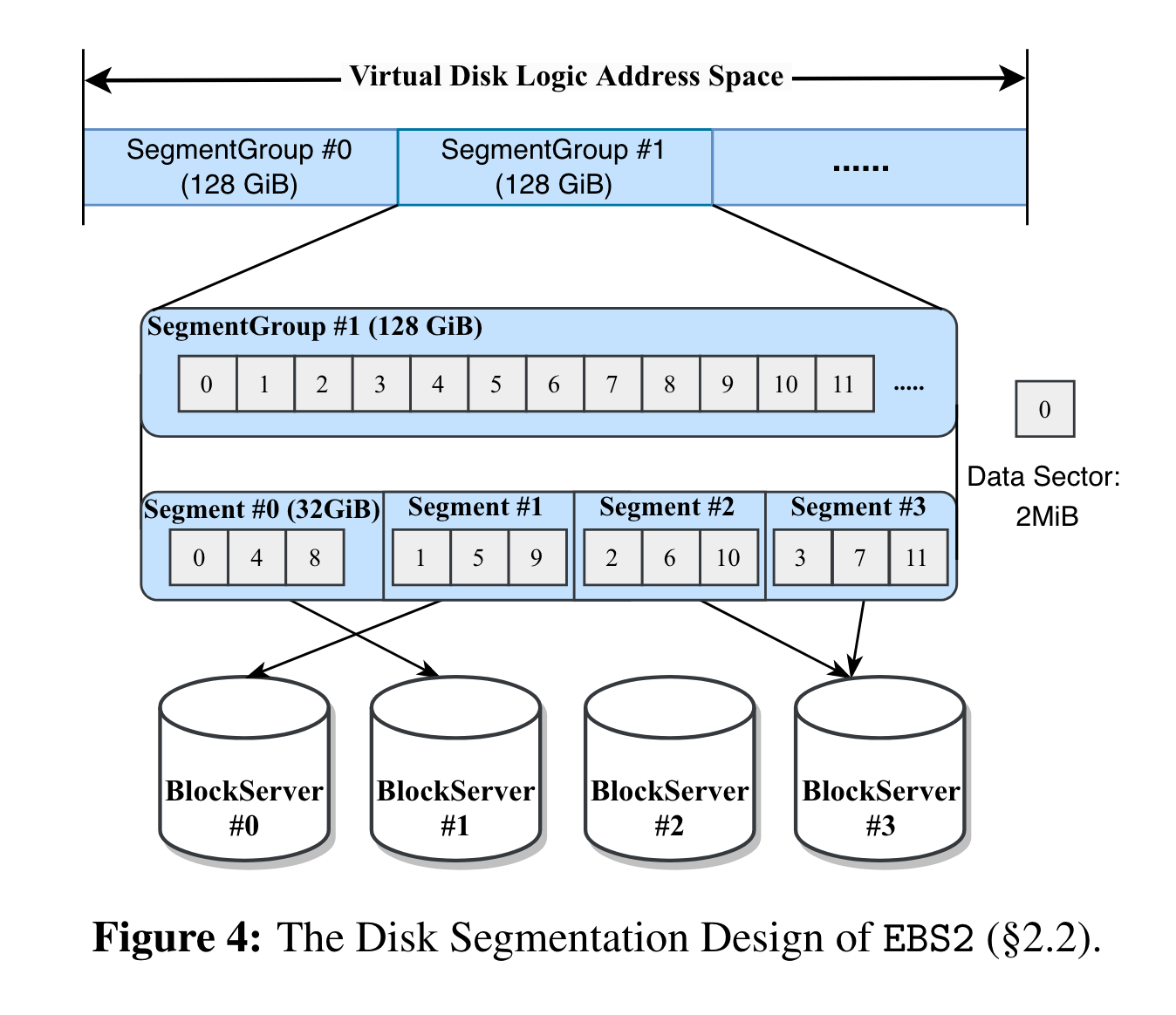
和EBS1不同,VD的逻辑地址划分成了一个个128GB的segment group,每个segment group又重新划分成了多个segment(每个32GB),segment groupt中数据按照 data section(2M) round robin的方式分配到不同的segment中。 最终每个segment底层为多个data file(512M), 用于提升并发。
通过segment划分,解决EBS1中的热点问题,降低了故障域。
LSBD:
LSBD用于将issue来的随机io转变为盘古的append api, 流程如下:
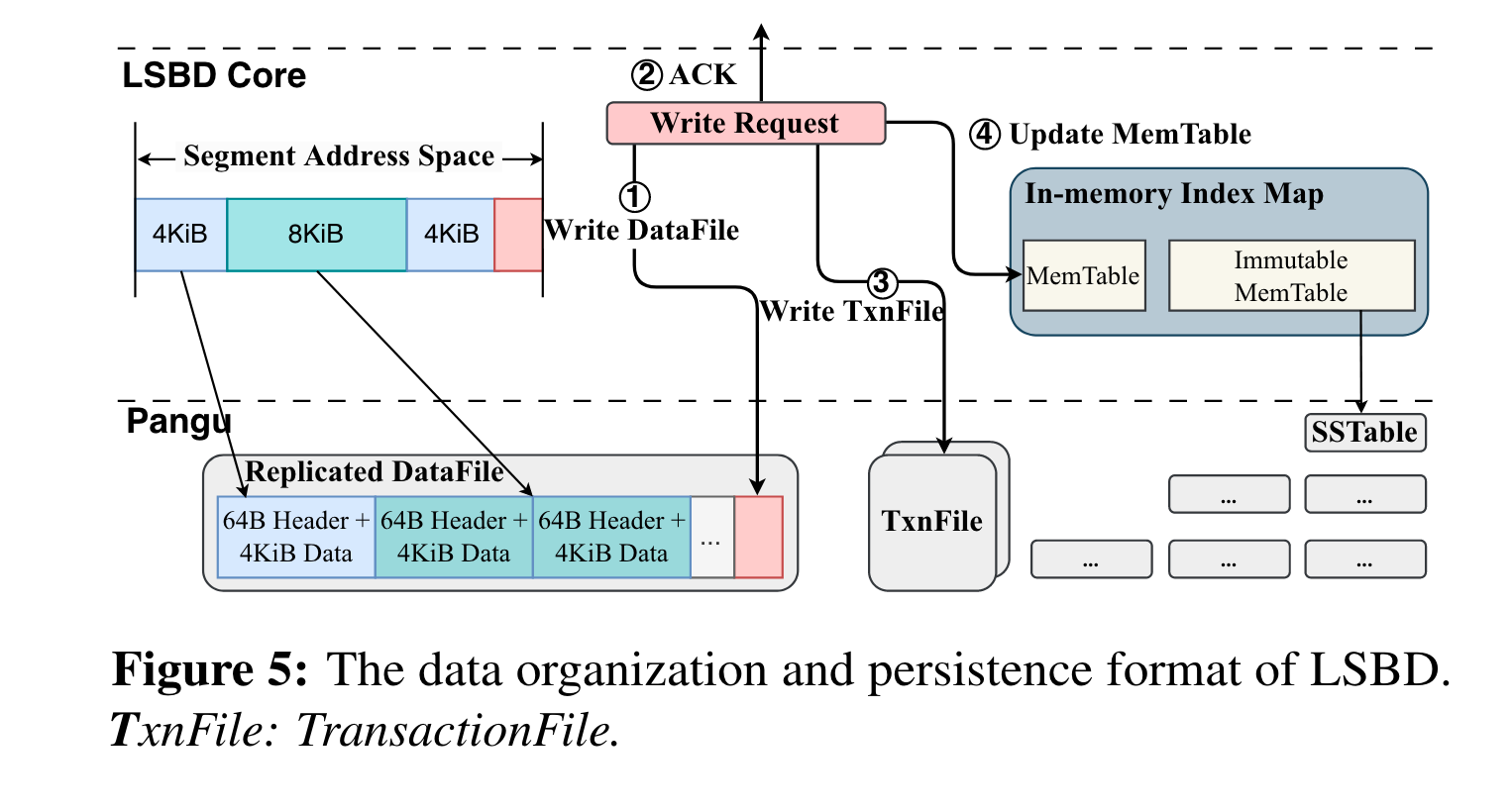
- 将segment 4kb块写入到盘古的data file (每个4kb + 64B的header)。
- 持久化完成后就可以ack到user
- 记录update到txn file。 (这个应该就类似于wal,用于后续恢复index)
- 更新index,记录LBA到data file(file id + offset)的映射,这个index由LSM实现
上述所有文件都在盘古中。
笔者注:本地完全无状态,很容易扩展
GC:
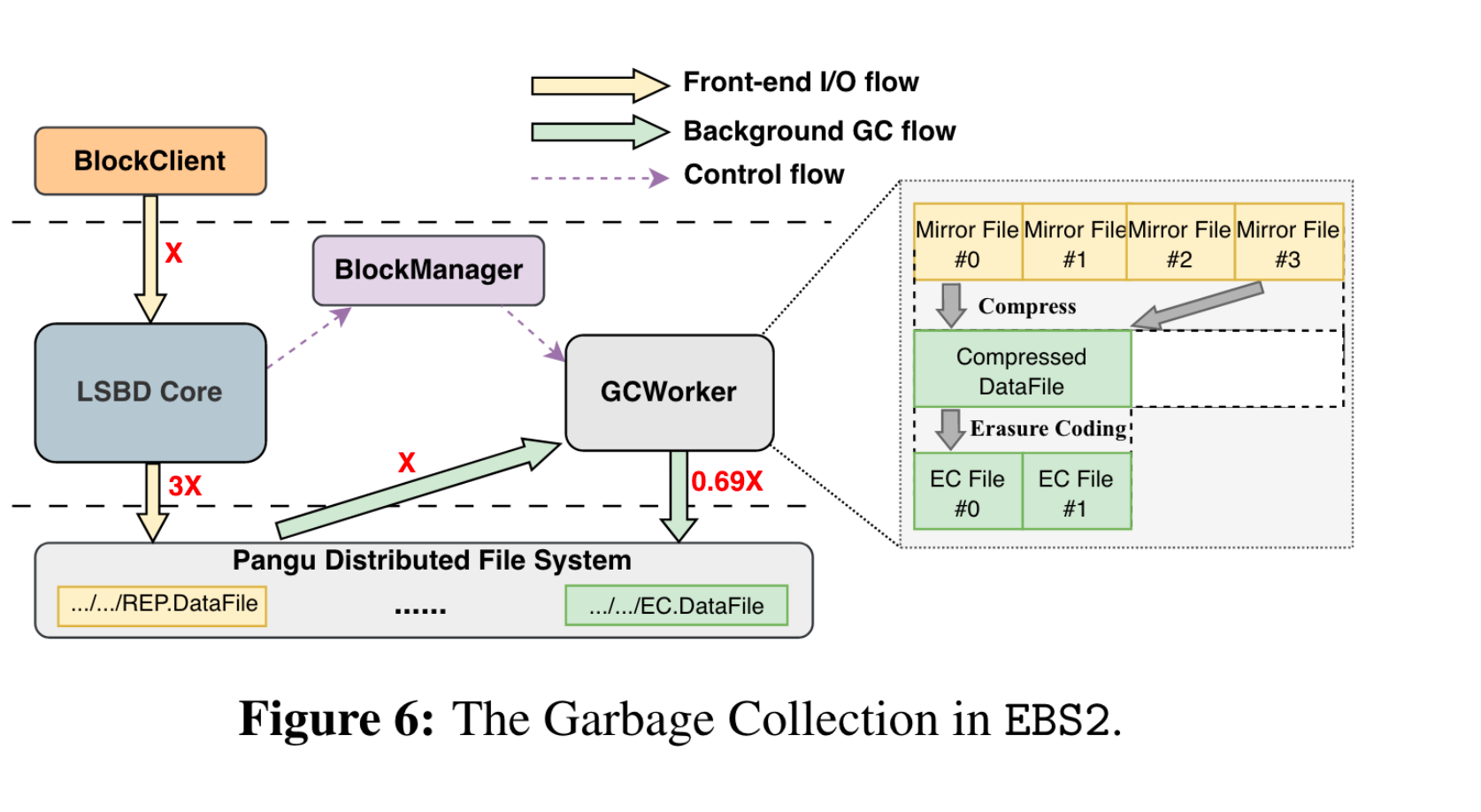
垃圾率到达一定阈值,触发GC,gc以data file为粒度(同一个segment下),gc的提交点为更新txnfile(笔者注:如果gc new file生成,txn file没更新,这个gc生成的new file如何回收?)。 在 gc过程中,将前台写的副本转为EC + lz4 压缩。
data file的组成有三部分:
- header: magic number, version + checksum
- compression blocks: 每个block由header + body组成。 header包括时间戳、压缩算法、data长度和checksum组成。body由压缩数据+metadata组成
- offset table:LBA -> data file location的映射
读取时,先读offset table,根据LBA定位到location即可。目前gc带来的写放大,在大压力集群下小于1.5 (笔者注:相当于垃圾率大于50%的才gc)
block manager的高可用:
由于分布式层+数据都在盘古里,所以block manager可以做到更高可以用,无状态拉起。
网络
对于data path:
前台网络使用 luna (阿里自实现的 user space tcp, 特点是zero copy + rtc(run to complete)), 部署在2X25Gbps的网卡上。
后台采用RDMA
control path不变,仍然使用kernel tcp。
snapshot
out of udpate, snapshot变得更简单。
部署
相比EBS1, EBS2的数据空间占用(用了压缩+ec),从3副本降为了0.69,但是data file也是三副本的,平均下来data占用为1.29 (为什么不是0.69 *3?)
问题
网络放大问题, 相比EBS1,EBS2的网络放大从 3 (原来是3副本) 变成了 4.69(3副本+ 1GC读 + 0.69 EC)。为了减缓这个问题,一种方式是用在线EC, 但是 很难在短时间(EBS承诺write lat为100us)攒到16KB(16KB为一个条带)
EBS3·
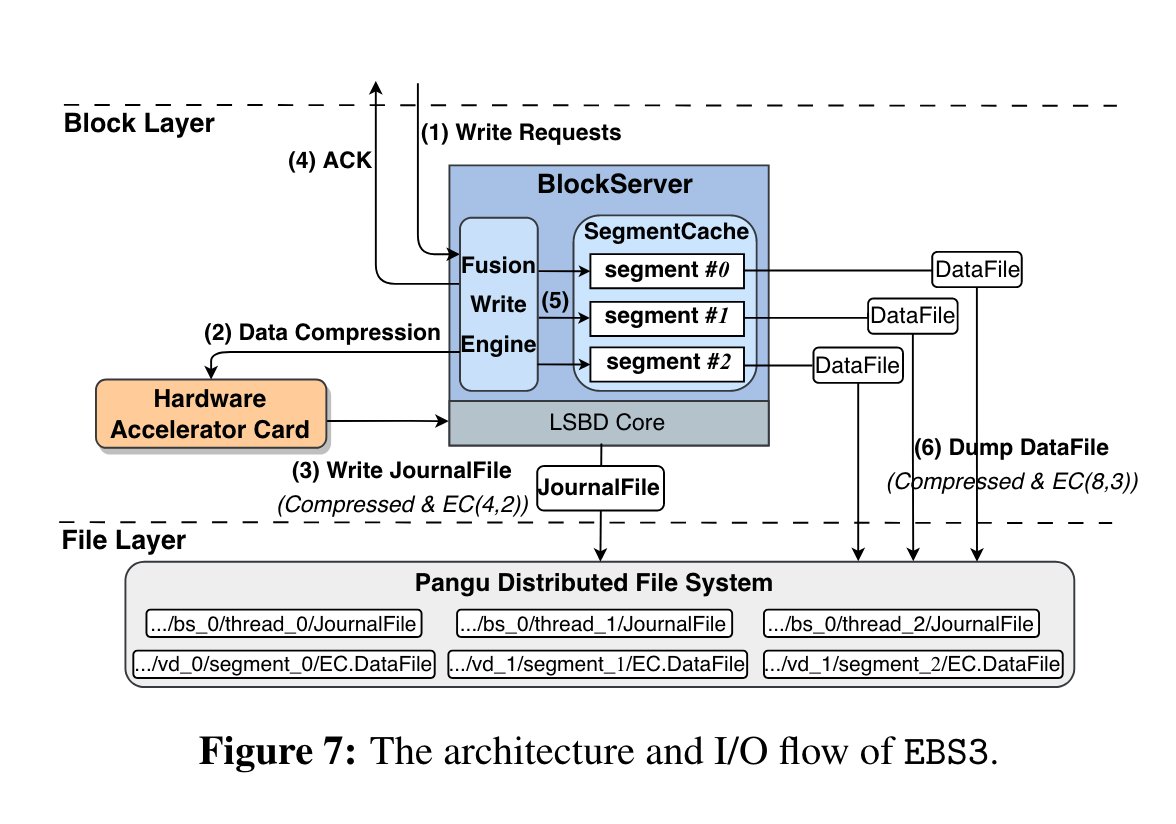
架构 and io flow:
增加FWE (Fusion Write Engine), 聚合多个segment 的write io,用于更好的凑条带。
- 接受write io request, FWE聚合不同VD的不同segment io
- 组合write为data blocks ,并将压缩卸载到FPGA
- 将压缩后的data blocks, 写入到盘古(EC写 4+ 2),(笔者注:相当于WAL)
- ack到user,(笔者注:相比EBS2,EBS3 的write时延怎么保证,以前不用压缩+ec)
- 将未压缩的数据cache住
- 当cache的segment数据容量达到512KB后,压缩这些数据(通过CPU,FPGA只给WAL),用EC(8 + 3) append到盘古,更新txn file,更新index map。
读流程:
- 先读cache,cache不命中,则
- 读index map, 找到对应的DataFile
- DataFile找对应的block
journalFile只用于fail over
笔者注:前台聚合多个segment再组ec,可以借鉴,但是前台写延迟是否有影响? 另外,现在明显内存耗得更多,segment级别攒ec,还是按照单个segment去攒的,如果有很多小segment,内存占用如何解决?攒不好条带怎么解决? 还是说EBS这种业务,512KB级别已经够小,是很好攒的级别了。
FWE: FWE聚合前台写,赞满16KB转为data block交给fpga写,(超时时间设置为8us, 这是NIC的polling时间,相当于没有收到请求的最小间隔是8us)。 另外,对于小写偏多的集群业务,不走ec,直接走副本模式。
FPGA
压缩解压卸载到fpga:
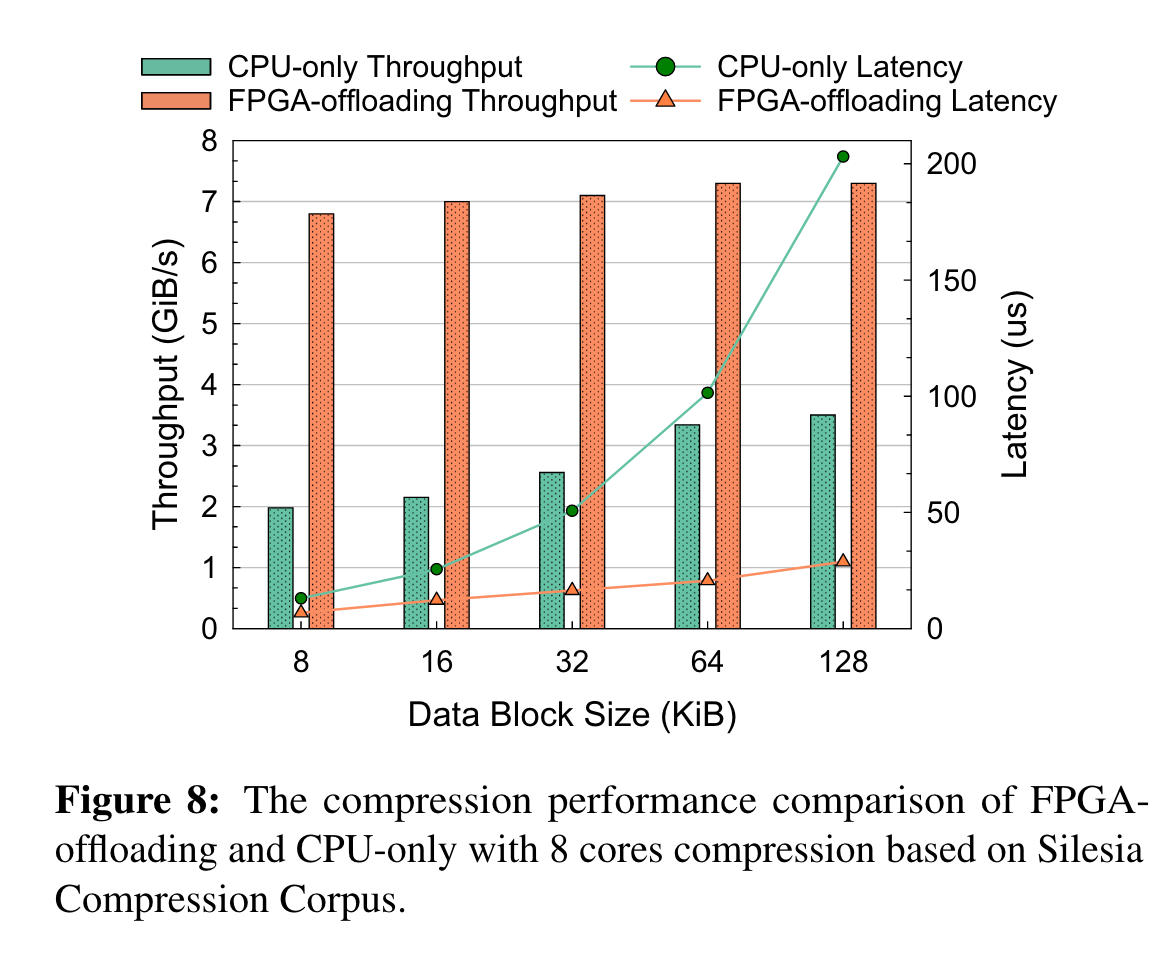
在16KB上,FPGA相比CPU带宽收益最明显,所以FWE的攒阈值为16KB
网络
前后端都采用2 x100Gbsp的网卡, 使用自研的UDP传输协议-Solar。 使用DPU。
By leveraging the hardware offloading on our Data Processing Units (DPUs), Solar can pack each storage data block as a network packet, thereby achieving CPU/PCIe bypassing, easy receive-side buffer management and fast multi-path recovery.
部署收益
空间放大从 1.29(EBS2) 降到 0.77 (直接存了EC,不用先副本再转)。 使用FPGA,压缩的速度也更快,带宽更大。 网络带宽放大从4.69降到了1.59。
整个EBS3,引入了FPGA的成本,但是空间放大降低了,网络放大只要不是瓶颈,个人觉得还好,(不过得看集群空间利用率,才能看到具体的收益)。
评估·
FIO测随机读写:
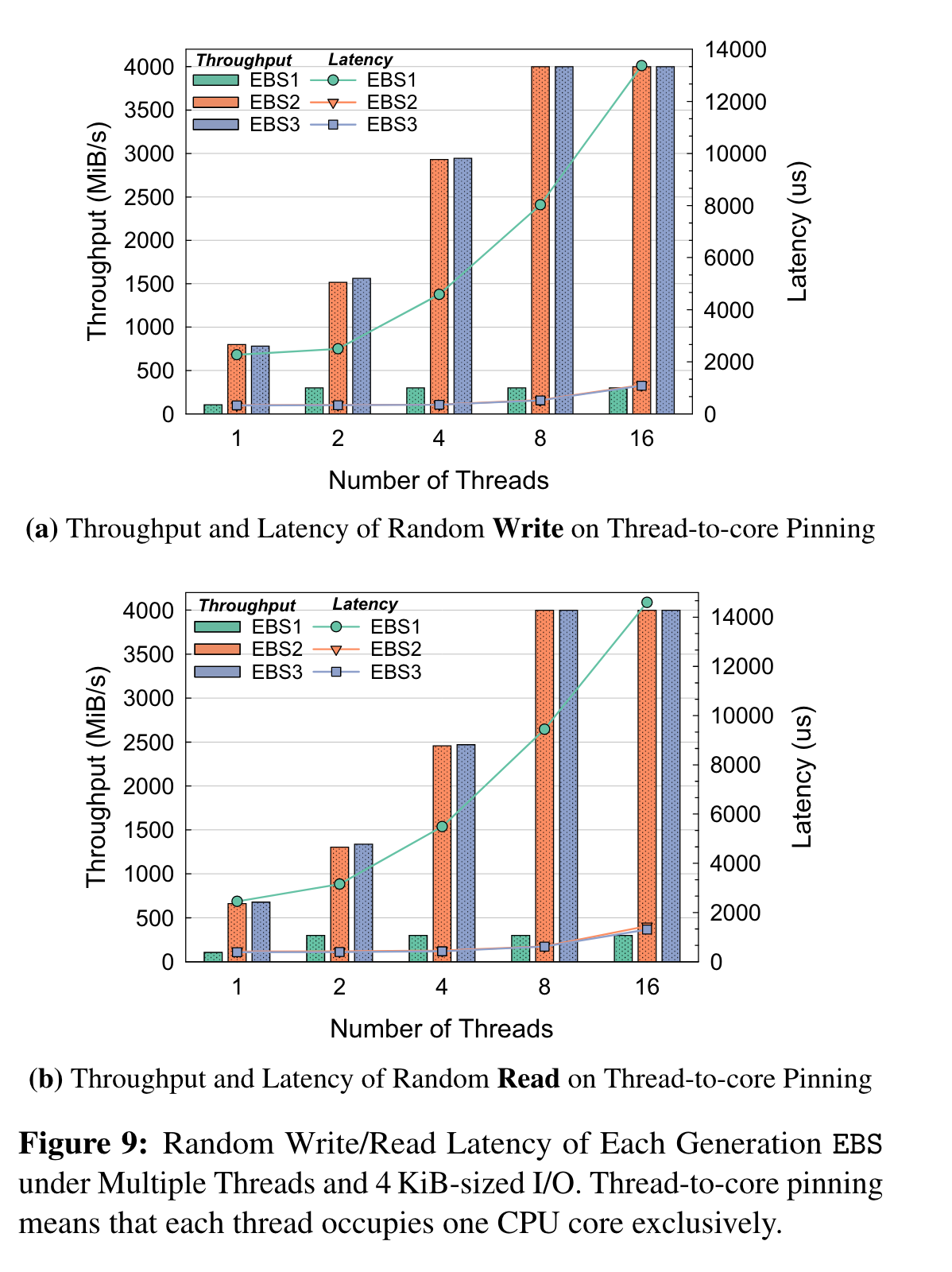
rocksdb + YCSB , mysql + sysbench
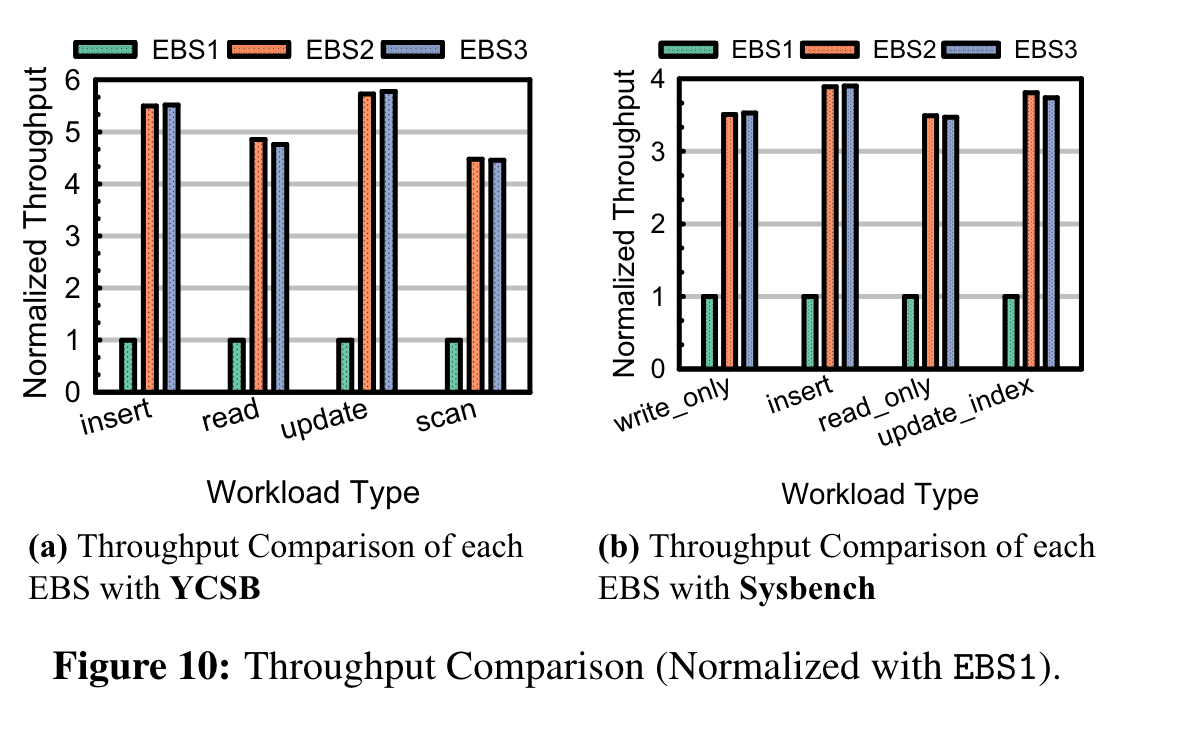
EBS2和EBS3性能相当,相比EBS1有很大收益。
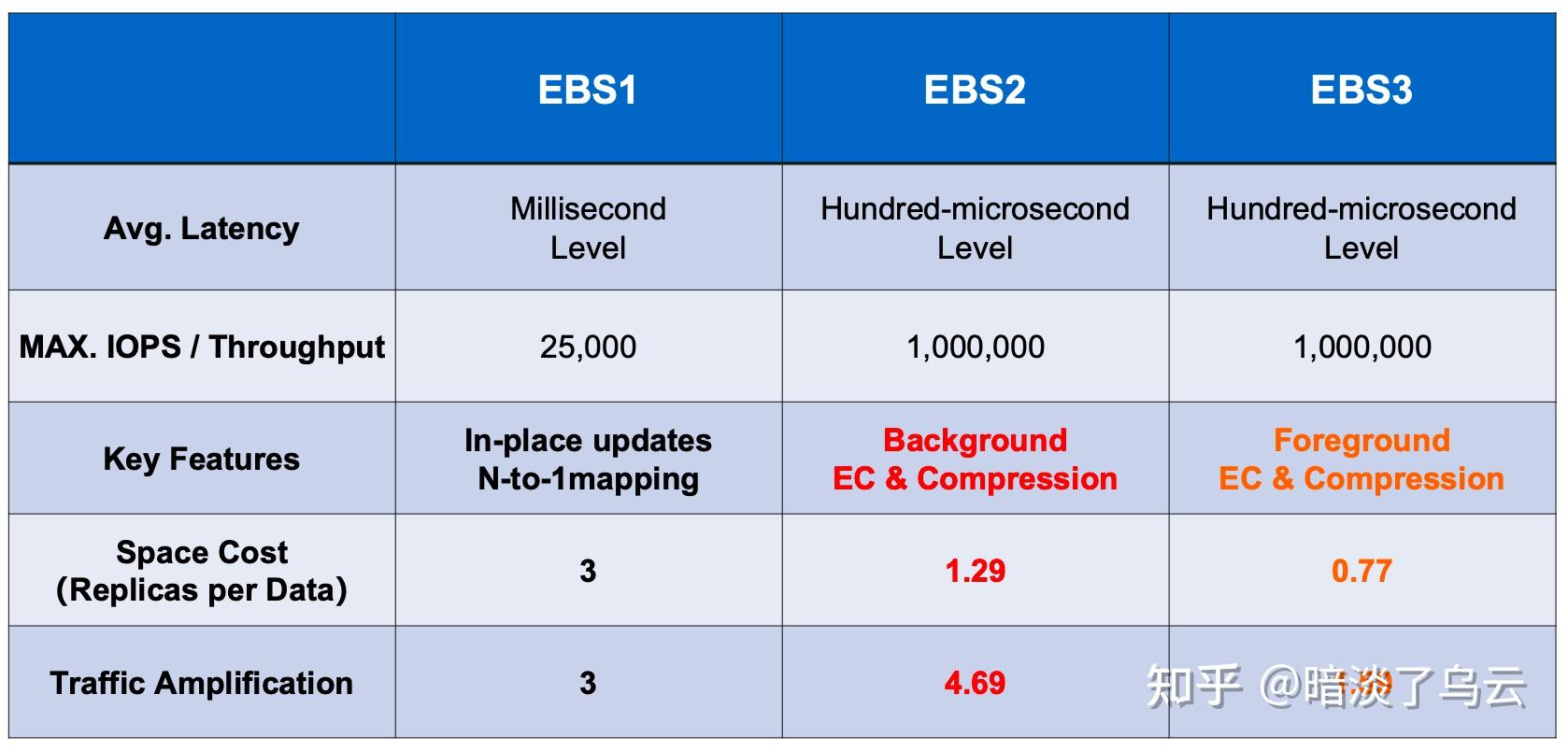
各架构指标总结:
弹性·
延迟·
延迟受的影响主要看io路径。EBS受限:
- 两跳网络, BlockClient到BlockServer, BlockServer到ChunkServer
- 软件栈
- SSD/HDD IO时间
平均时延:
测试方法, 8KB随机读写。
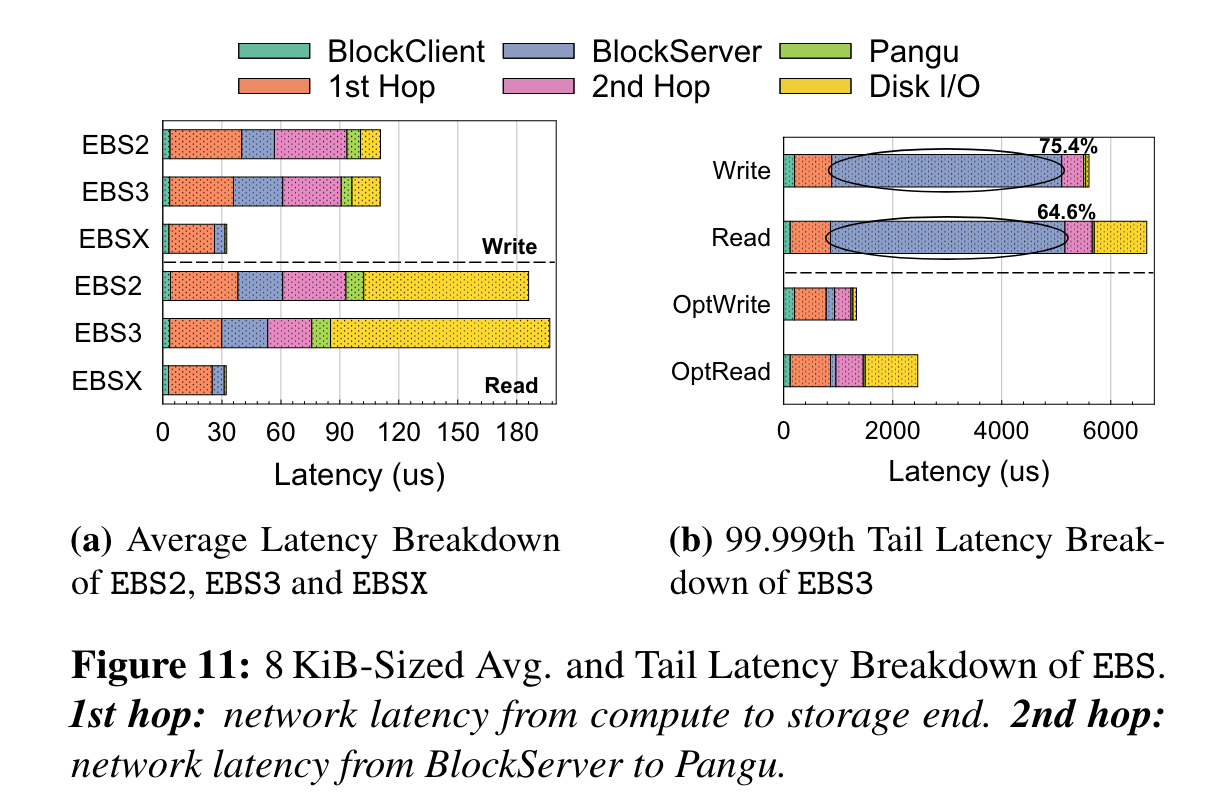
左图为平均时延:
- 两跳网络开展最大
- EBS3的block server比EBS2的block server耗时更多, 因为EBS3需要做前台EC+压缩
- EBS3的第二跳网络比EBS2时延低,因为EBS3做了前台EC+压缩,网络数据量变小了
- 最后是Disk IO,EBS3的Disk IO比EBS2耗时更长,因为EBS3用的QLC SSD,EBS3用的TLC
很明显,延迟受硬件的影响更大(网络和disk)。
阿里为此研发了EBSX,直接在blockserver旁架了一个PM,用3副本的方式将前台写入PM,用作持久化缓存,然后后台转EC + compression。图中显示PM的读写性能(全缓存的场景)都明显好于EBS2和EBS3.
笔者注:在PM被intel放弃的今天,这种架构还能长期演进吗?毕竟软件优化是有极限的。
尾时延
尾时延体现在软件栈上了,blockserver耗时过长,优化方法:
- 网络慢io,换节点读写。
- 尾延迟主要是IO和后台任务之间的竞争导致,EBS3把io和后台线程分离,得到了上图右边optXXX的结果
吞吐和iops·
优化两个组件:
- Block Client: EBS2用了LUNA(用户态TCP协议栈), EBS3卸载io处理到FPGA
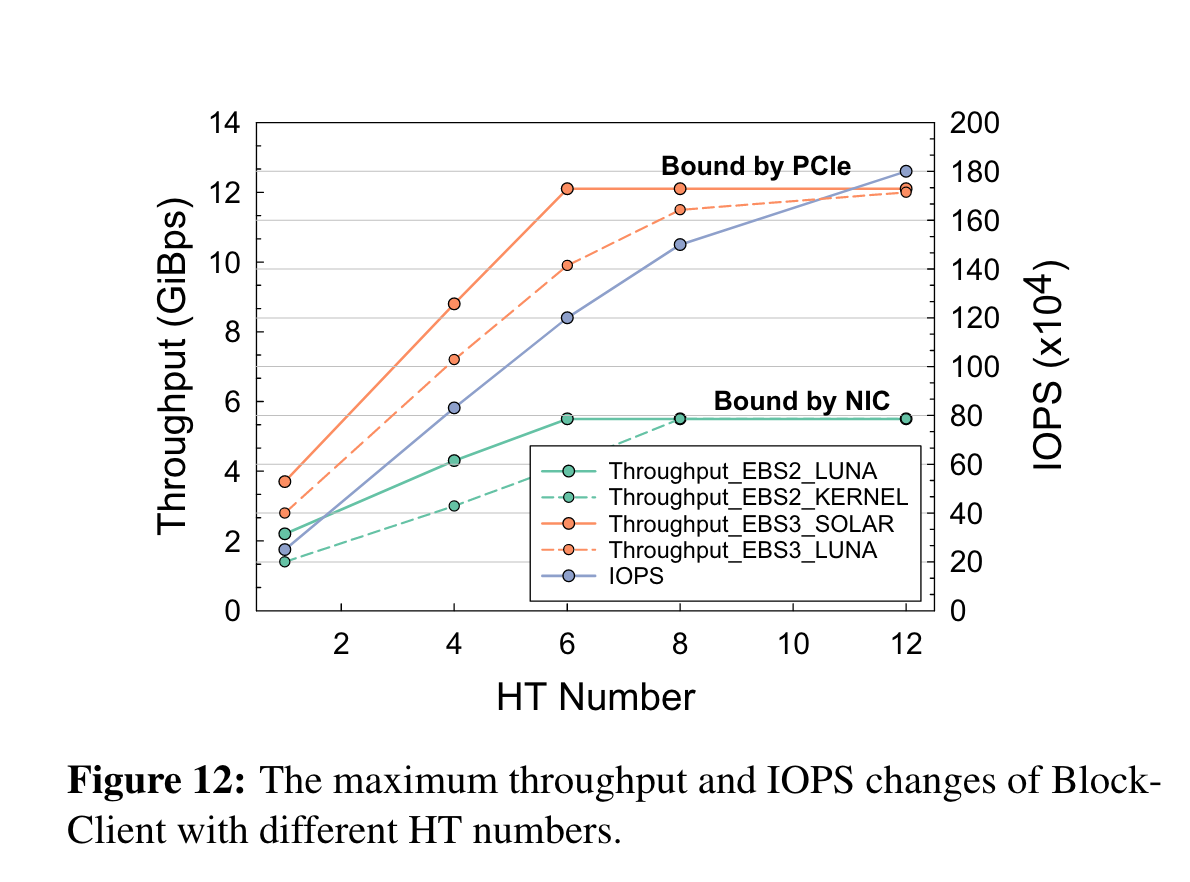
EBS3的带宽上线受PCIe带宽影响。EBS2受NIC影响。
笔者注:Block Client 具体会做什么?sdk的计算负载会很重吗?还需要卸载到FPGA?
笔者注:现在各个优化技术,都是尽量把内核做的事情挪到用户态,减少内核开销。 感觉”微内核“才是趋势。
- Block Server: server侧的iops和吞吐主要看server的并行度,EBS2引入了 segment group, segment, data sector的拆分粒度来提高并发度。 另外对于 "brust io"的处理添加了三种策略:1.基于优先级的拥塞控制,brust io基于当前剩余空闲的可用资源来分配。 2. 前台抢占后台资源。3.热点迁移。
可用性·
主要关注爆炸半径:
- 全局(集群范围内),如block manager crash,影响所有VD
- regional, 如一个block server crash,block server管理的VD失效
- 独立,如一块盘,segment故障
solution:
for 全局:减少cluster的size,管理更少的VD,收到的影响自然更小。
for regional, 由于引入segmnet group,每个block server管理的VD,EBS2和EBS3相比EBS1更多,所以一个block server收到影响,将有更多VD收到影响。 segment 迁移可能会引起”雪崩“,如一个坏的segment导致一个block server挂掉,然后控制面复制segment到其它节点,结果其它block server也挂掉,直到出现集群维度的fault。
控制面·
为了解决问题,将block manager所管理的VD再做拆分成多个partition(有点类似于大集群拆小集群,Multi-Raft的感觉)。然后在BlockManager上层再架一个高可用的node,拆分后的BlockManager管理的VD小了,故障率也减小了,上层的CentralManager只用管理BlockManager,负载是很轻的。
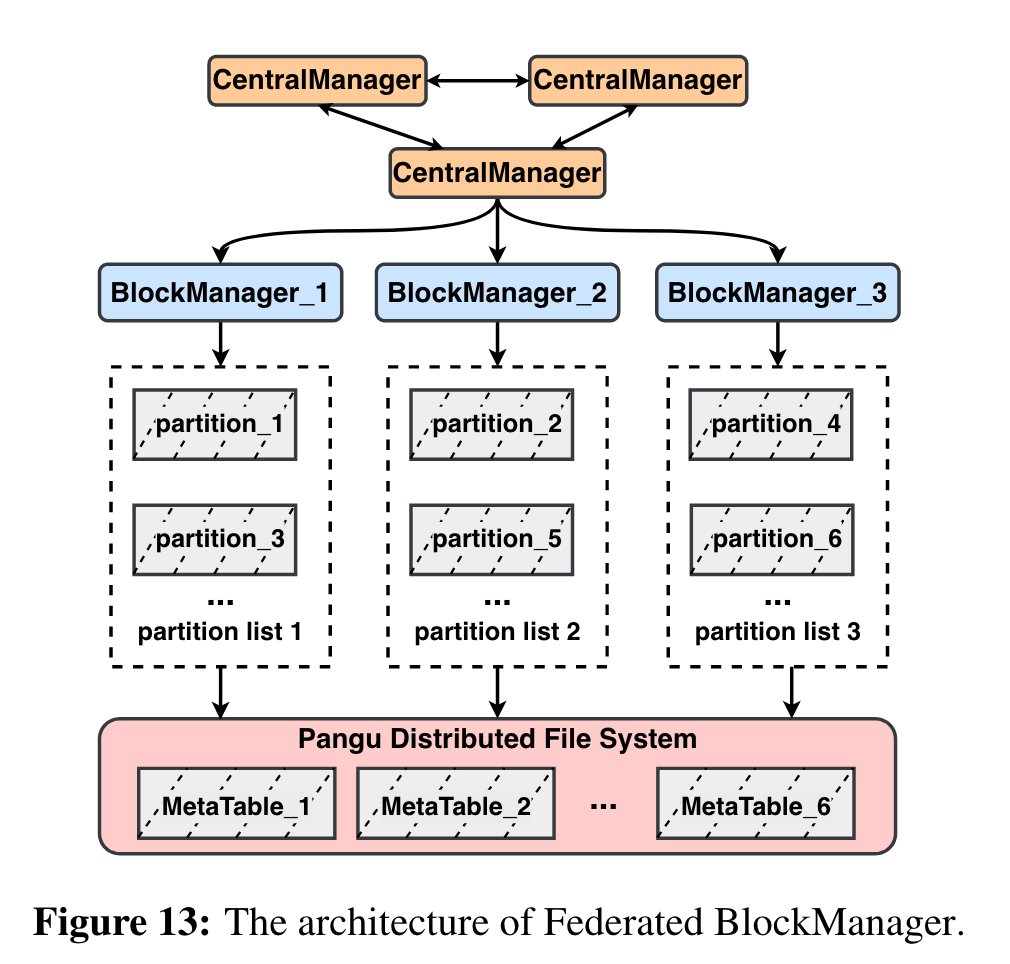
另外,BlockManager不用3 node来保证高可用,只用一个节点就行,即使一个block manager crash,CentralManager可以立马调度这个partition到其他blockmanager(调度过程实际上就是把metadata从盘古中load出来,通常只用几百ms)
数据面·
添加逻辑故障域的概念,为了避免一个corrupted的segment 不断迁移/复制到其它block server,从而引起集群故障。
方法:为每个segment 增加一个token bucket,每次复制/迁移均需获取token,token目前最大为3,每30min填充一次。这样就限制了segment迁移的频率,同时每个segment预设了可迁移的block server,进而限制了segment迁移的range。
笔者注:个人觉得一个corrupt的segment为什么会引起整个block server的进程crash,理论上软件编码做得好,只需要本地隔离,然后等着迁移就行了,或许是担心segment多,迁移引起雪崩,占用大量资源,进而影响前台io。
只是这样依然不行,因为可能存在大量segment corrupt,这些segment的故障域可能覆盖整个集群,所以如果存在超过1个segment corrupt了,将第一个segment的故障域设置为全局故障域,之后那些token为0的segment的故障域全部绑定到这个故障域中,这样就限定多segment故障最多影响3个block server,而不是集群维度的。
笔者注:这样限定了segment迁移的带宽,而且ebs架构每个segment在block server层是单副本的,如果不能快速恢复,不会影响io吗?
应该不会,因为每个segment有3次机会复制到其它block server。
一些Lesson·
SDK侧:
SDK侧受限于部署环境(sdk是在VM中),限制了CPU利用,所以需要做计算offloading,
FPGA offloading计算转AISC-based offloading,因为FPGA的故障率过高。 AISC-based比FPGA的故障率低一个数量级。
两者区别:
https://www.asicnorth.com/blog/asic-vs-fpga-difference/
简单说,AISC 不可重编程,FPGA可重编程,AISC成本更低,FPGA成本更高。
Server侧:
也不再使用FPGA,因为FPGA故障率高,且不够灵活,比如换一个压缩算法,FPGA需要重编程,这对集群部署、演进升级来说是expensive的。 Server转用multi-core的cpu(这些cpu可能带了专门用于压缩的芯片),如 Yitian 710 ARM, kunpeng 920 ARM。
What If?·
不采用log-structured的设计?·
问题主要在不好做前台ECh和压缩,因为大部分写流量都是小于16KB的小写, in-place update也让压缩难做。
其余question没啥营养,不做记录了。
总结:一些值得学习的点·
- log structured 的持久化层,这个是主流云存储都在采用的方案
- 数据切片(segment化),这个也是主流方案
- 复合多个segment做前台EC, 后台EC存在写放大问题
- 逻辑故障域和Federated BlockManager提升可用性
- 平均时延受硬件、架构影响,比如少一跳网络的设计,加cache等。尾延迟主要受软件栈的影响,可用绑核、user stack tcp,协程等方式。(笔者注:感觉存储卷到最后的技术都差不多。。。)

