A ...............................................................页码 B ...............................................................页码 C ...............................................................页码 D ...............................................................页码 E ...............................................................页码 F ...............................................................页码 H |____ a ...............................................................页码 |____ .. ...............................................................页码 |____ u |____ a ...............................................................页码 |____ .. ...............................................................页码 |____ i ...............................................................页码 ...
// Approximate size of user data packed per block. Note that the // block size specified here corresponds to uncompressed data. The // actual size of the unit read from disk may be smaller if // compression is enabled. This parameter can be changed dynamically. size_t block_size = 4 * 1024;
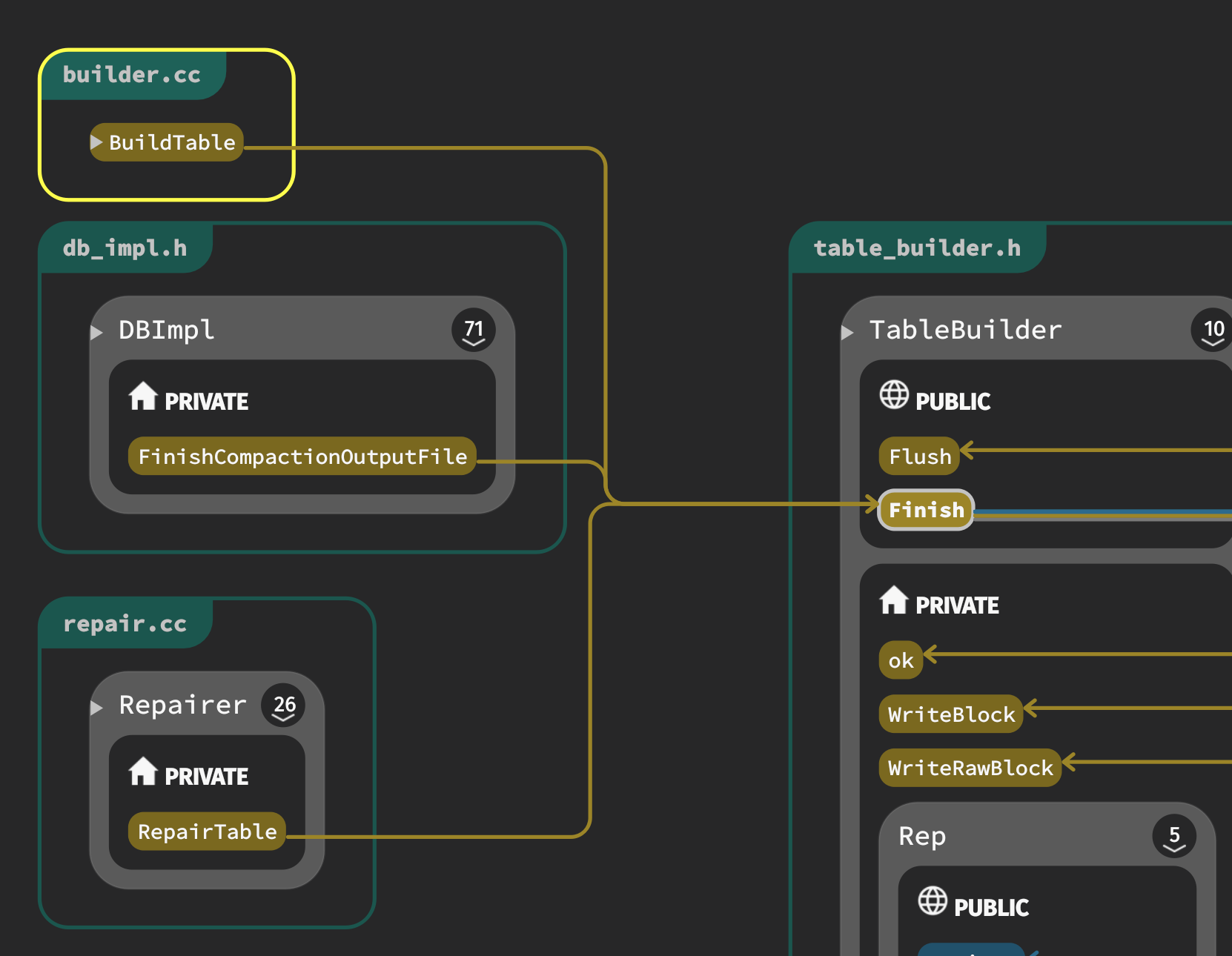
TableBuilder::Flush
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
voidTableBuilder::Flush(){ Rep* r = rep_; assert(!r->closed); if (!ok()) return; if (r->data_block.empty()) return; // r->pending_index_entry is true only if data_block is empty. assert(!r->pending_index_entry); // 实际写入 WriteBlock(&r->data_block, &r->pending_handle); if (ok()) { r->pending_index_entry = true; // 写入成功与否状态 r->status = r->file->Flush(); } if (r->filter_block != nullptr) { // 应用 filter(根据源码来看,目前应该只支持bloom filter) r->filter_block->StartBlock(r->offset); } }
voidTableBuilder::WriteBlock(BlockBuilder* block, BlockHandle* handle){ // File format contains a sequence of blocks where each block has: // block_data: uint8[n] // type: uint8 // crc: uint32 assert(ok()); Rep* r = rep_; Slice raw = block->Finish();
Slice block_contents; CompressionType type = r->options.compression; // TODO(postrelease): Support more compression options: zlib? // 压缩 switch (type) { case kNoCompression: block_contents = raw; break;
case kSnappyCompression: { std::string* compressed = &r->compressed_output; if (port::Snappy_Compress(raw.data(), raw.size(), compressed) && compressed->size() < raw.size() - (raw.size() / 8u)) { block_contents = *compressed; } else { // Snappy not supported, or compressed less than 12.5%, so just // store uncompressed form block_contents = raw; type = kNoCompression; } break; } }
由于在一个data block中存在多个key value paris,且它们相互之间是相互有序的,leveldb为了能够减少冗余存储,使用了key的 前缀压缩机制。假设现在要存储两个key, key1 =“the dog”, key2 = “the world”, 会发现key1和key的前4个字符"the “都是相同的,采用前缀压缩机制,key1继续存储"the dog”,key2只用存储"world"即可。
除此之外,leveldb在每16次共享后,会取消当前的前缀共享机制,重新存储当前完整的key。
16次来自:options::block_restart_interval
1 2 3 4
// Number of keys between restart points for delta encoding of keys. // This parameter can be changed dynamically. Most clients should // leave this parameter alone. int block_restart_interval = 16;
// We do not emit the index entry for a block until we have seen the // first key for the next data block. This allows us to use shorter // keys in the index block. For example, consider a block boundary // between the keys "the quick brown fox" and "the who". We can use // "the r" as the key for the index block entry since it is >= all // entries in the first block and < all entries in subsequent // blocks. // // Invariant: r->pending_index_entry is true only if data_block is empty. bool pending_index_entry;
voidCreateFilter(const Slice* keys, int n, std::string* dst)constoverride{ // Compute bloom filter size (in both bits and bytes) size_t bits = n * bits_per_key_;
// For small n, we can see a very high false positive rate. Fix it // by enforcing a minimum bloom filter length. if (bits < 64) bits = 64;
size_t bytes = (bits + 7) / 8; bits = bytes * 8;
constsize_t init_size = dst->size(); dst->resize(init_size + bytes, 0); dst->push_back(static_cast<char>(k_)); // Remember # of probes in filter char* array = &(*dst)[init_size]; for (int i = 0; i < n; i++) { // Use double-hashing to generate a sequence of hash values. // See analysis in [Kirsch,Mitzenmacher 2006]. uint32_t h = BloomHash(keys[i]); constuint32_t delta = (h >> 17) | (h << 15); // Rotate right 17 bits for (size_t j = 0; j < k_; j++) { constuint32_t bitpos = h % bits; array[bitpos / 8] |= (1 << (bitpos % 8)); h += delta; } } }
boolKeyMayMatch(const Slice& key, const Slice& bloom_filter)constoverride{ constsize_t len = bloom_filter.size(); if (len < 2) returnfalse;
// Use the encoded k so that we can read filters generated by // bloom filters created using different parameters. constsize_t k = array[len - 1]; if (k > 30) { // Reserved for potentially new encodings for short bloom filters. // Consider it a match. returntrue; }
uint32_t h = BloomHash(key); constuint32_t delta = (h >> 17) | (h << 15); // Rotate right 17 bits for (size_t j = 0; j < k; j++) { constuint32_t bitpos = h % bits; if ((array[bitpos / 8] & (1 << (bitpos % 8))) == 0) returnfalse; h += delta; } returntrue; }
voidCreateFilter(const Slice* keys, int n, std::string* dst)constoverride{ // 1.得到bloom filter用的bit数 // Compute bloom filter size (in both bits and bytes) size_t bits = n * bits_per_key_;
// For small n, we can see a very high false positive rate. Fix it // by enforcing a minimum bloom filter length. if (bits < 64) bits = 64;
size_t bytes = (bits + 7) / 8; bits = bytes * 8;
constsize_t init_size = dst->size(); dst->resize(init_size + bytes, 0); dst->push_back(static_cast<char>(k_)); // Remember # of probes in filter char* array = &(*dst)[init_size]; for (int i = 0; i < n; i++) { // 外循环计算每个key,n代表key的个数 // Use double-hashing to generate a sequence of hash values. // See analysis in [Kirsch,Mitzenmacher 2006]. uint32_t h = BloomHash(keys[i]); constuint32_t delta = (h >> 17) | (h << 15); // Rotate right 17 bits for (size_t j = 0; j < k_; j++) { // 内循环计算多个hash constuint32_t bitpos = h % bits; array[bitpos / 8] |= (1 << (bitpos % 8)); h += delta; } } }
voidFilterBlockBuilder::GenerateFilter(){ constsize_t num_keys = start_.size(); if (num_keys == 0) { // Fast path if there are no keys for this filter filter_offsets_.push_back(result_.size()); return; } // tmp_keys中存放本轮要进行计算的keys // Make list of keys from flattened key structure start_.push_back(keys_.size()); // Simplify length computation tmp_keys_.resize(num_keys); for (size_t i = 0; i < num_keys; i++) { // keys_中存放了所有key,通过偏移量start[i]和length (start[i+1] - start[i]) 得到一个key constchar* base = keys_.data() + start_[i]; size_t length = start_[i + 1] - start_[i]; tmp_keys_[i] = Slice(base, length); }
// 记录上一轮计算的结果 // Generate filter for current set of keys and append to result_. filter_offsets_.push_back(result_.size()); // 计算本轮keys的filter 位图,并将结果放入到result_中 policy_->CreateFilter(&tmp_keys_[0], static_cast<int>(num_keys), &result_);
// A FilterBlockBuilder is used to construct all of the filters for a // particular Table. It generates a single string which is stored as // a special block in the Table. // // The sequence of calls to FilterBlockBuilder must match the regexp: // (StartBlock AddKey*)* Finish classFilterBlockBuilder { public: explicitFilterBlockBuilder(const FilterPolicy*);
voidFilterBlockBuilder::GenerateFilter(){ // 根据前面说所,可推得start_.size()为当前Add进来的key的个数 constsize_t num_keys = start_.size(); if (num_keys == 0) { // Fast path if there are no keys for this filter // 后续所有的filter的大小都是0, 只用在filter_offset_中记录相同的位置。 filter_offsets_.push_back(result_.size()); return; }
// 第一个filter块,使用所有的keys_ // 通过start_和key_将 所有添加的key加入到tmp_keys_中。 // Make list of keys from flattened key structure start_.push_back(keys_.size()); // Simplify length computation tmp_keys_.resize(num_keys); for (size_t i = 0; i < num_keys; i++) { constchar* base = keys_.data() + start_[i]; size_t length = start_[i + 1] - start_[i]; tmp_keys_[i] = Slice(base, length); }
// 为所有添加进来的 keys 生成一个 Filter,并将结果 append到 result_中 // Generate filter for current set of keys and append to result_. filter_offsets_.push_back(result_.size()); // !filter_offsets_.size() +1 policy_->CreateFilter(&tmp_keys_[0], static_cast<int>(num_keys), &result_);
while (filter_index > filter_offsets_.size()) { GenerateFilter(); }
这个循环,仍在继续。而后序的调用会进入到这个分支:
1 2 3 4 5 6 7 8 9 10
voidFilterBlockBuilder::GenerateFilter(){ // 根据前面说所,可推得start_.size()为当前Add进来的key的个数 constsize_t num_keys = start_.size(); if (num_keys == 0) { // 后续所有的filter的大小都是0, 只用在filter_offset_中记录相同的位置。 // Fast path if there are no keys for this filter filter_offsets_.push_back(result_.size()); return; }
// 为所有添加进来的 keys 生成一个 Filter,并将结果 append到 result_中 // Generate filter for current set of keys and append to result_. filter_offsets_.push_back(result_.size()); // !filter_offsets_.size() +1 policy_->CreateFilter(&tmp_keys_[0], static_cast<int>(num_keys), &result_);
第二次:
1 2 3 4 5
if (num_keys == 0) { // Fast path if there are no keys for this filter filter_offsets_.push_back(result_.size()); // 此时第一次调用已经使得result_ size增加, 假设这里增加了9 return; }
第三次:
1 2 3 4 5
if (num_keys == 0) { // Fast path if there are no keys for this filter filter_offsets_.push_back(result_.size()); // 此时result未发生变化,size依然等于9 return; }

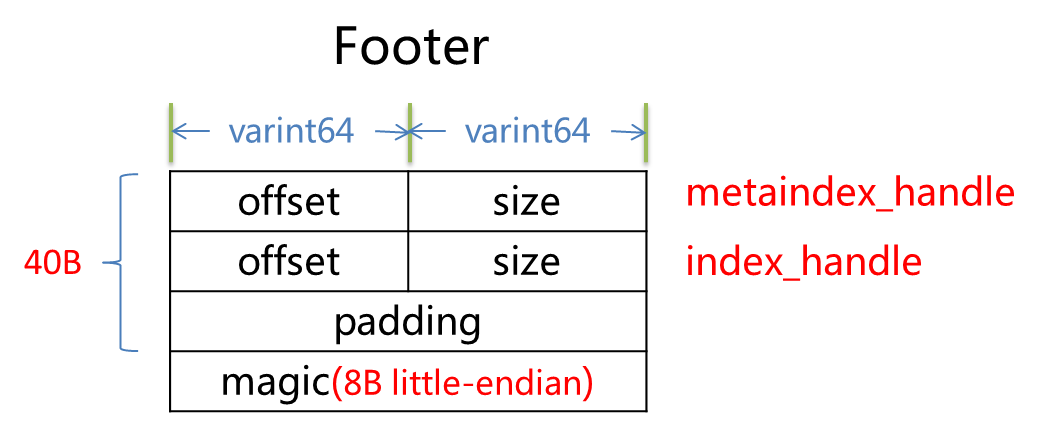

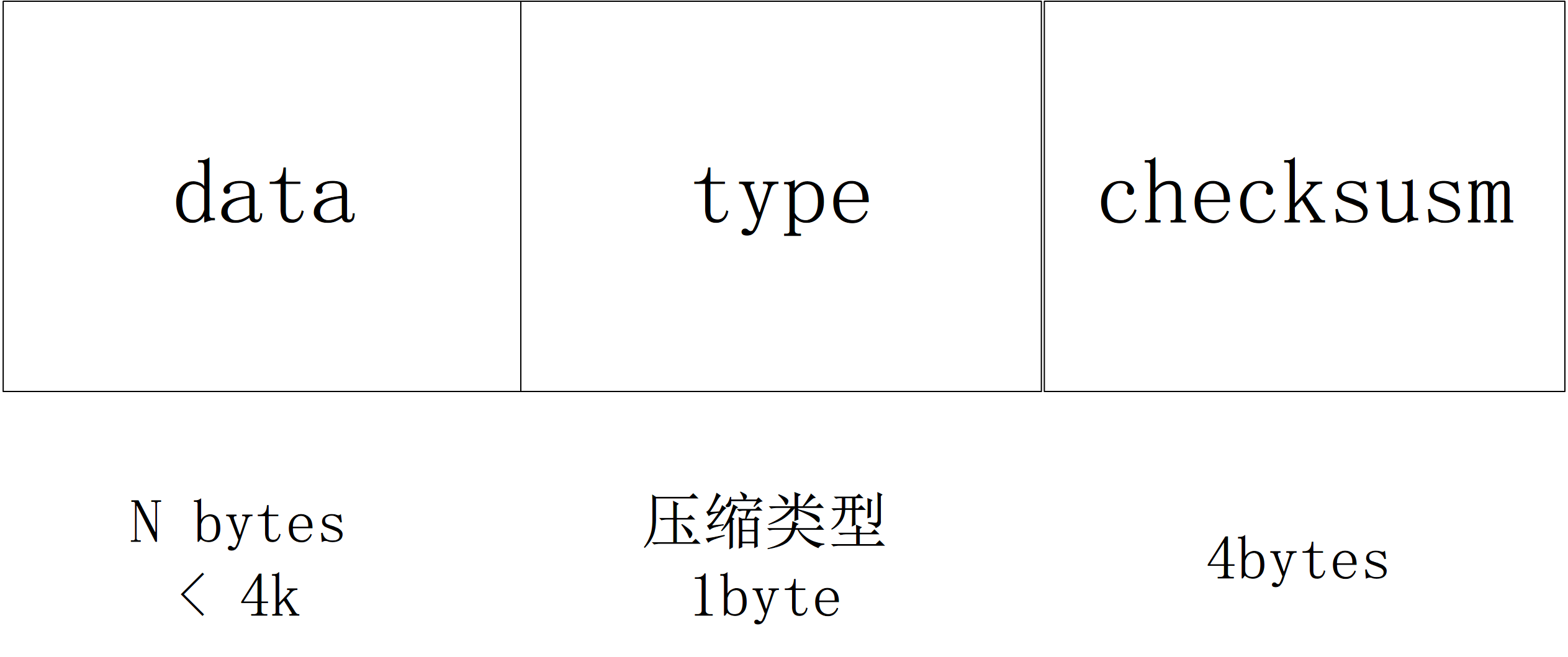


.png)
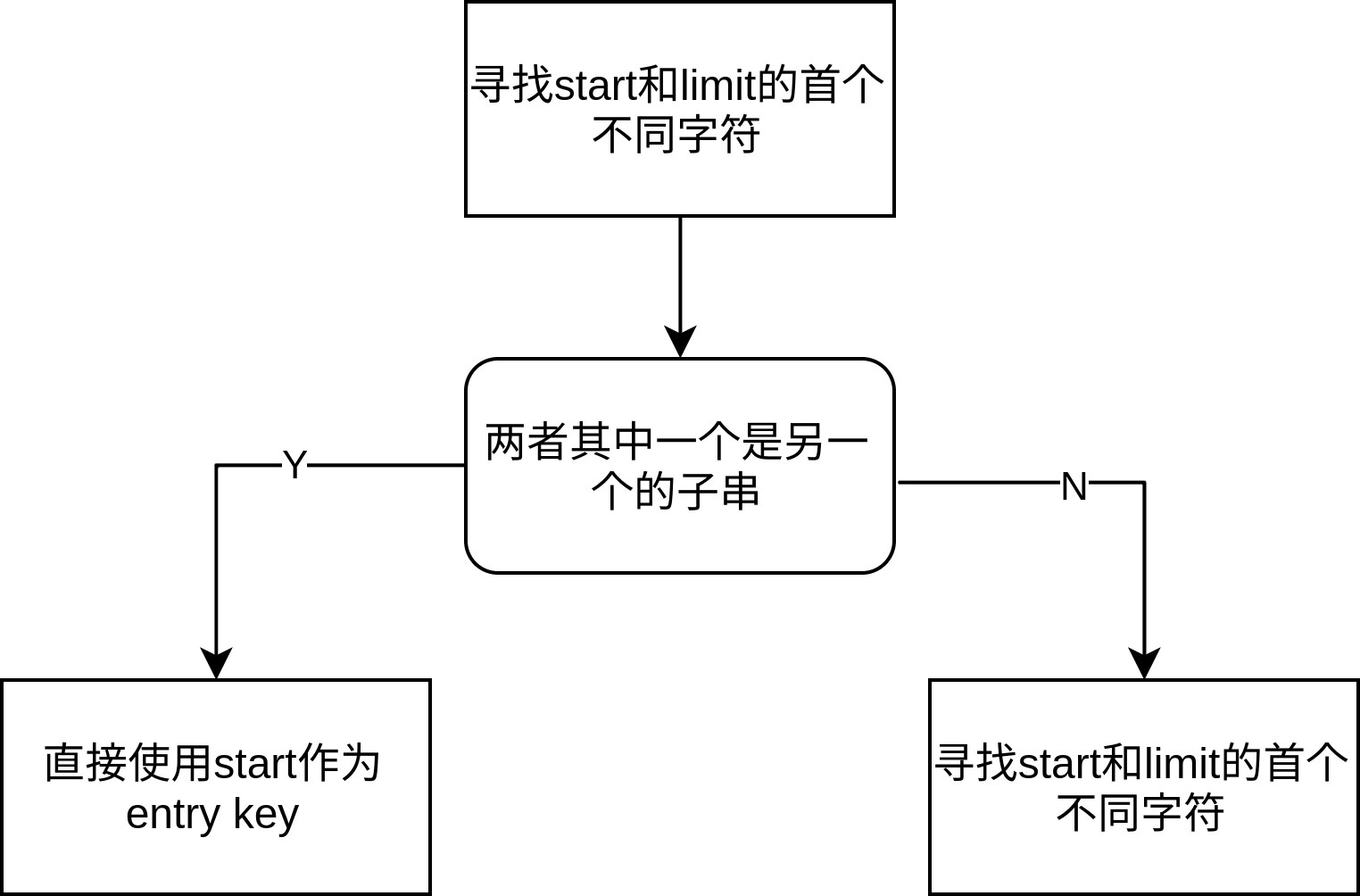
.png)



.png)
.png)

