int refs; int allowed_seeks; // Seeks allowed until compaction,用于基于seek compaction uint64_t number; // 这个number用来唯一标识一个sstable,还记得文件命名中的编号吗? uint64_t file_size; // File size in bytes 文件大小 InternalKey smallest; // Smallest internal key served by table 最小key InternalKey largest; // Largest internal key served by table 最大key };
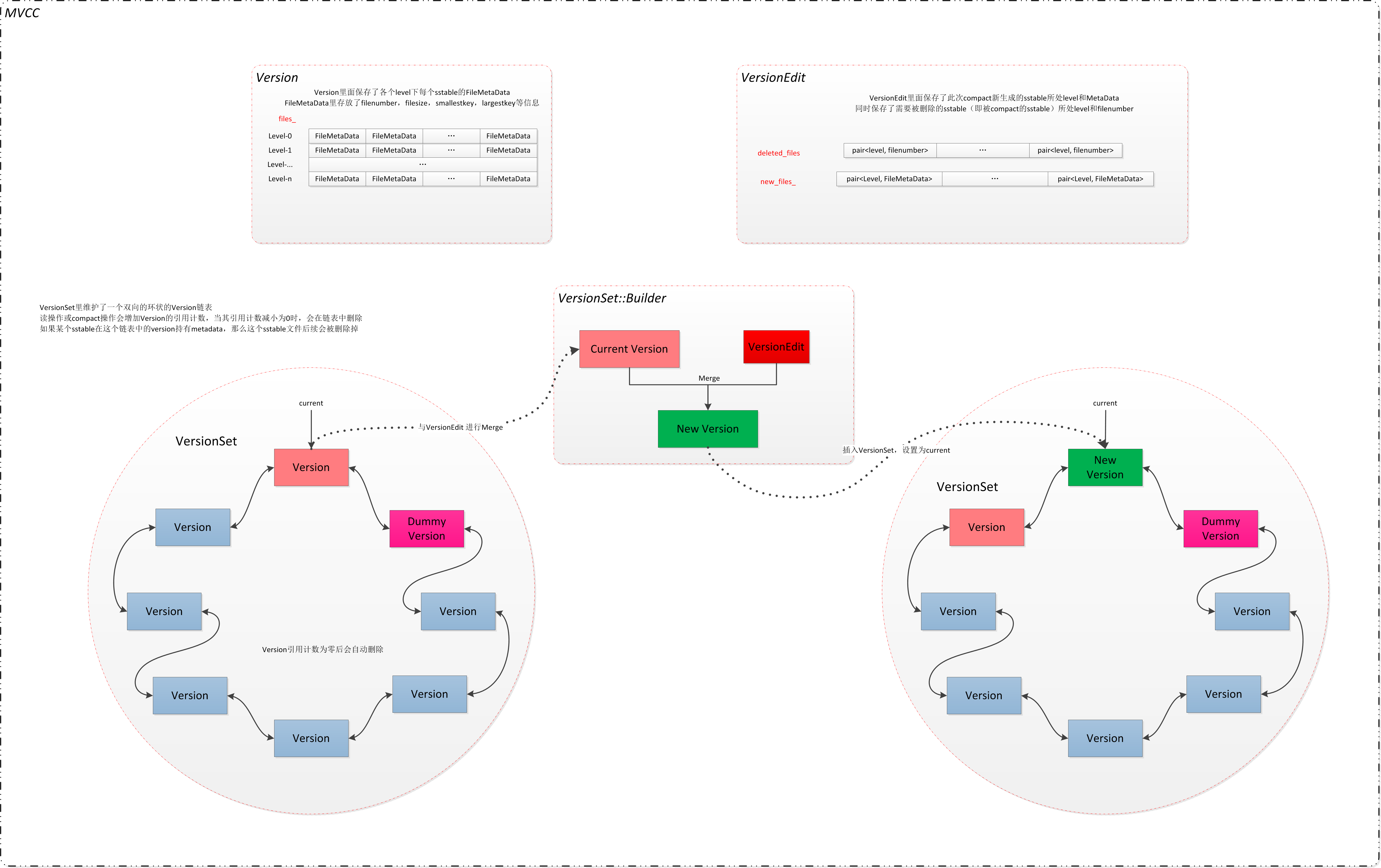
// 这里看出leveldb在系统中维护的version组成一个链表,且系统中可能存在多个VersionSet。每个Set维护一(多)组Version VersionSet* vset_; // VersionSet to which this Version belongs Version* next_; // Next version in linked list Version* prev_; // Previous version in linked list int refs_; // Number of live refs to this version // 引用计数,估计和回收Version相关
// 每层的files, 每个file都是FileMetadata // List of files per level std::vector<FileMetaData*> files_[config::kNumLevels];
// Next file to compact based on seek stats. FileMetaData* file_to_compact_; // compaction过程会用到 int file_to_compact_level_;
// compaction相关,根据compactoin_score_决定是否需要compaction // Level that should be compacted next and its compaction score. // Score < 1 means compaction is not strictly needed. These fields // are initialized by Finalize(). double compaction_score_; int compaction_level_;
// Opened lazily WritableFile* descriptor_file_; log::Writer* descriptor_log_; Version dummy_versions_; // Head of circular doubly-linked list of versions. 链表head Version* current_; // == dummy_versions_.prev_ 当前version
// 下一次compaction时,每层compaction的开始key // Per-level key at which the next compaction at that level should start. // Either an empty string, or a valid InternalKey. std::string compact_pointer_[config::kNumLevels];
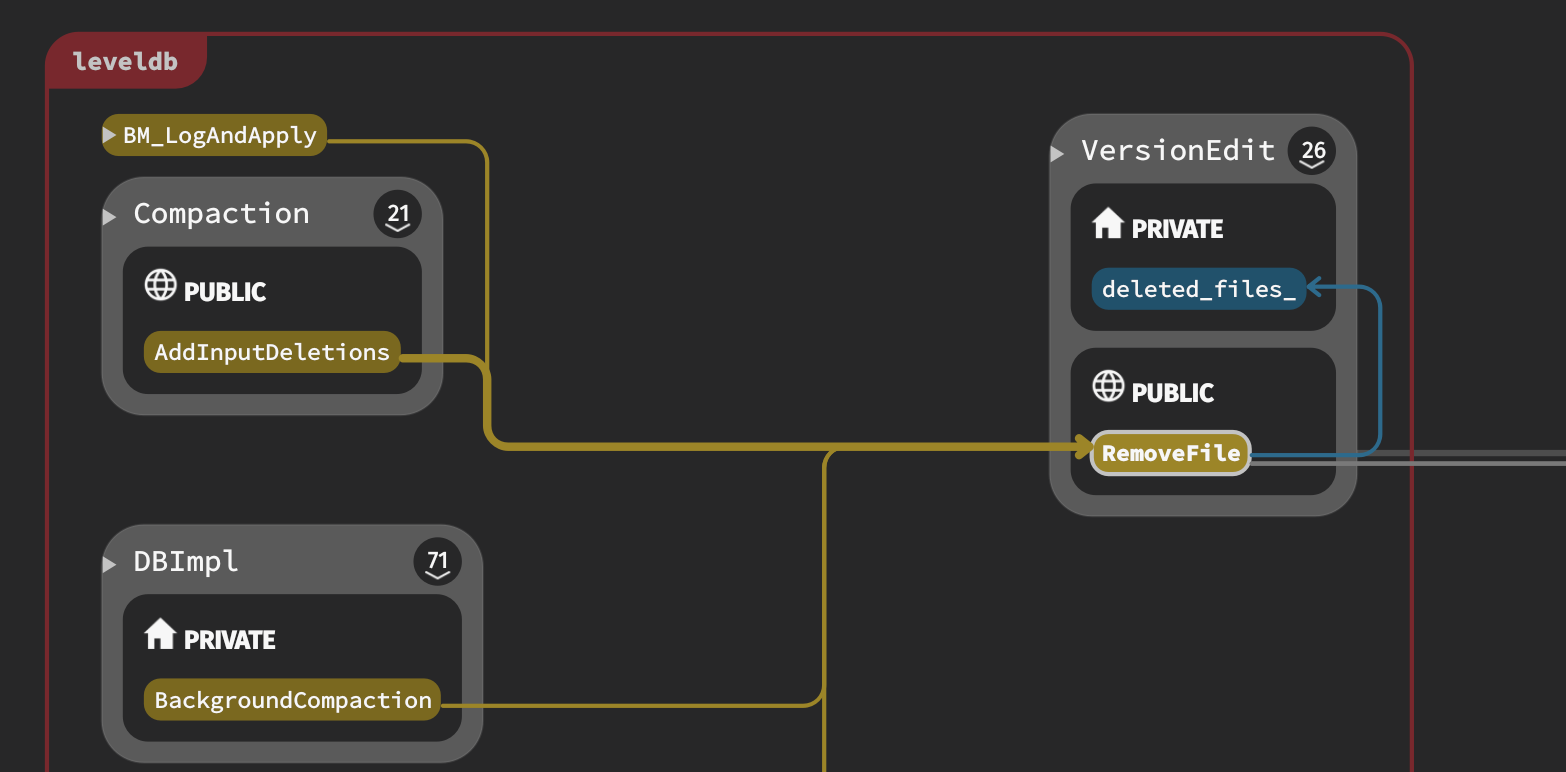
Status status; if (c == nullptr) { // Nothing to do } elseif (!is_manual && c->IsTrivialMove()) { // Move file to next level assert(c->num_input_files(0) == 1); FileMetaData* f = c->input(0, 0); // !!!! c->edit()->RemoveFile(c->level(), f->number); c->edit()->AddFile(c->level() + 1, f->number, f->file_size, f->smallest, f->largest); status = versions_->LogAndApply(c->edit(), &mutex_); if (!status.ok()) { RecordBackgroundError(status); } VersionSet::LevelSummaryStorage tmp; Log(options_.info_log, "Moved #%lld to level-%d %lld bytes %s: %s\n", static_cast<unsignedlonglong>(f->number), c->level() + 1, static_cast<unsignedlonglong>(f->file_size), status.ToString().c_str(), versions_->LevelSummary(&tmp)); }
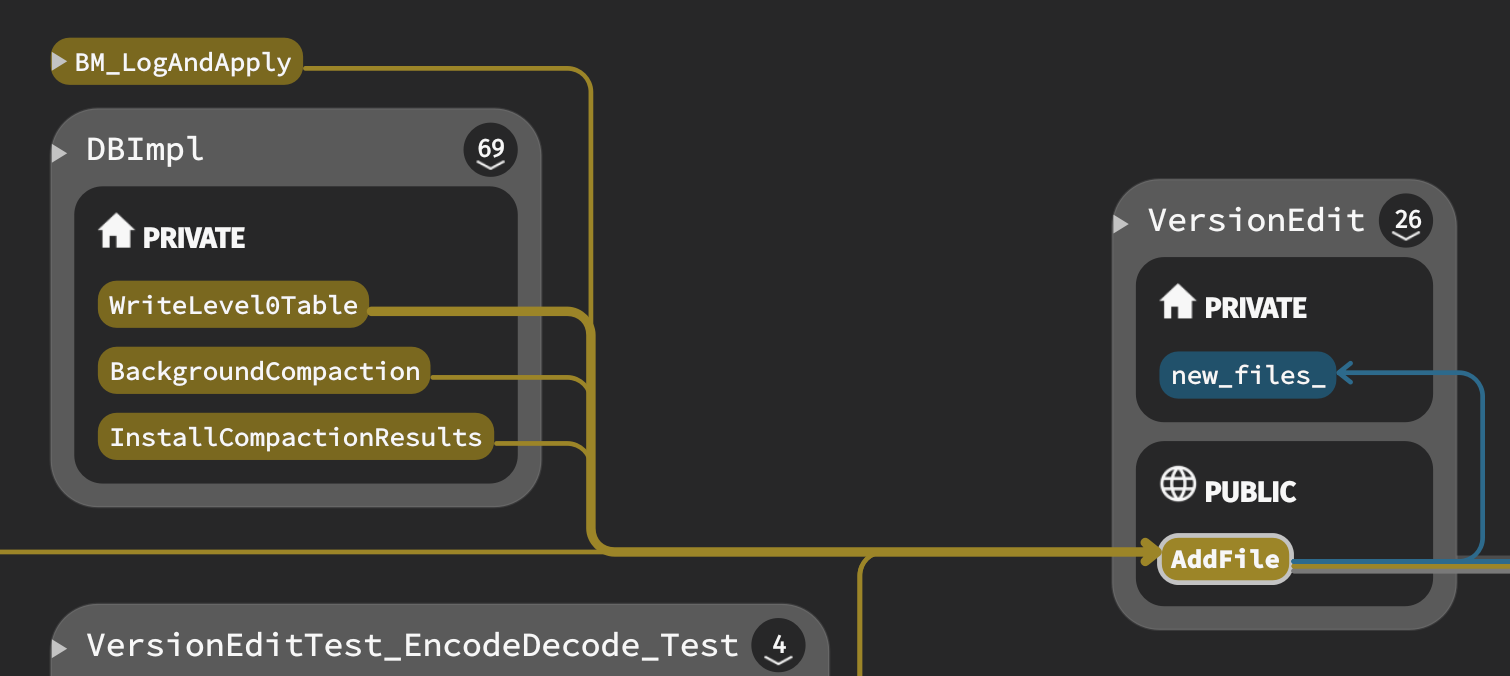
再看==new_files_==
new_files_在==AddFile==中增加:‘
1 2 3 4 5 6 7 8 9 10 11 12 13
// Add the specified file at the specified number. // REQUIRES: This version has not been saved (see VersionSet::SaveTo) // REQUIRES: "smallest" and "largest" are smallest and largest keys in file voidAddFile(int level, uint64_t file, uint64_t file_size, const InternalKey& smallest, const InternalKey& largest){ FileMetaData f; f.number = file; f.file_size = file_size; f.smallest = smallest; f.largest = largest; new_files_.push_back(std::make_pair(level, f)); }
// 下面和Manifest文件相关 // Initialize new descriptor log file if necessary by creating // a temporary file that contains a snapshot of the current version. std::string new_manifest_file; Status s; if (descriptor_log_ == nullptr) { // No reason to unlock *mu here since we only hit this path in the // first call to LogAndApply (when opening the database). assert(descriptor_file_ == nullptr); // new_manifest_file为当前manifest文件路径 new_manifest_file = DescriptorFileName(dbname_, manifest_file_number_); edit->SetNextFile(next_file_number_); // 创建文件 s = env_->NewWritableFile(new_manifest_file, &descriptor_file_); if (s.ok()) { // 创建manifest写者 descriptor_log_ = new log::Writer(descriptor_file_); s = WriteSnapshot(descriptor_log_); } }
// Unlock during expensive MANIFEST log write { mu->Unlock();
// Write new record to MANIFEST log if (s.ok()) { std::string record; // edit内容编码到record !!, 可以看一下是怎么编码的,这样就知道manifest文件中保存的内容布局了 edit->EncodeTo(&record); // 写入manifest文件 s = descriptor_log_->AddRecord(record); if (s.ok()) { // 刷新到设备上 s = descriptor_file_->Sync(); } if (!s.ok()) { Log(options_->info_log, "MANIFEST write: %s\n", s.ToString().c_str()); } }
// 更新Current指针 // If we just created a new descriptor file, install it by writing a // new CURRENT file that points to it. if (s.ok() && !new_manifest_file.empty()) { s = SetCurrentFile(env_, dbname_, manifest_file_number_); }
mu->Lock(); }
// 插入当前version到VersionSet中 // Install the new version if (s.ok()) { // 插入version,更新current AppendVersion(v); log_number_ = edit->log_number_; prev_log_number_ = edit->prev_log_number_; } else { delete v; if (!new_manifest_file.empty()) { delete descriptor_log_; delete descriptor_file_; descriptor_log_ = nullptr; descriptor_file_ = nullptr; env_->RemoveFile(new_manifest_file); } }
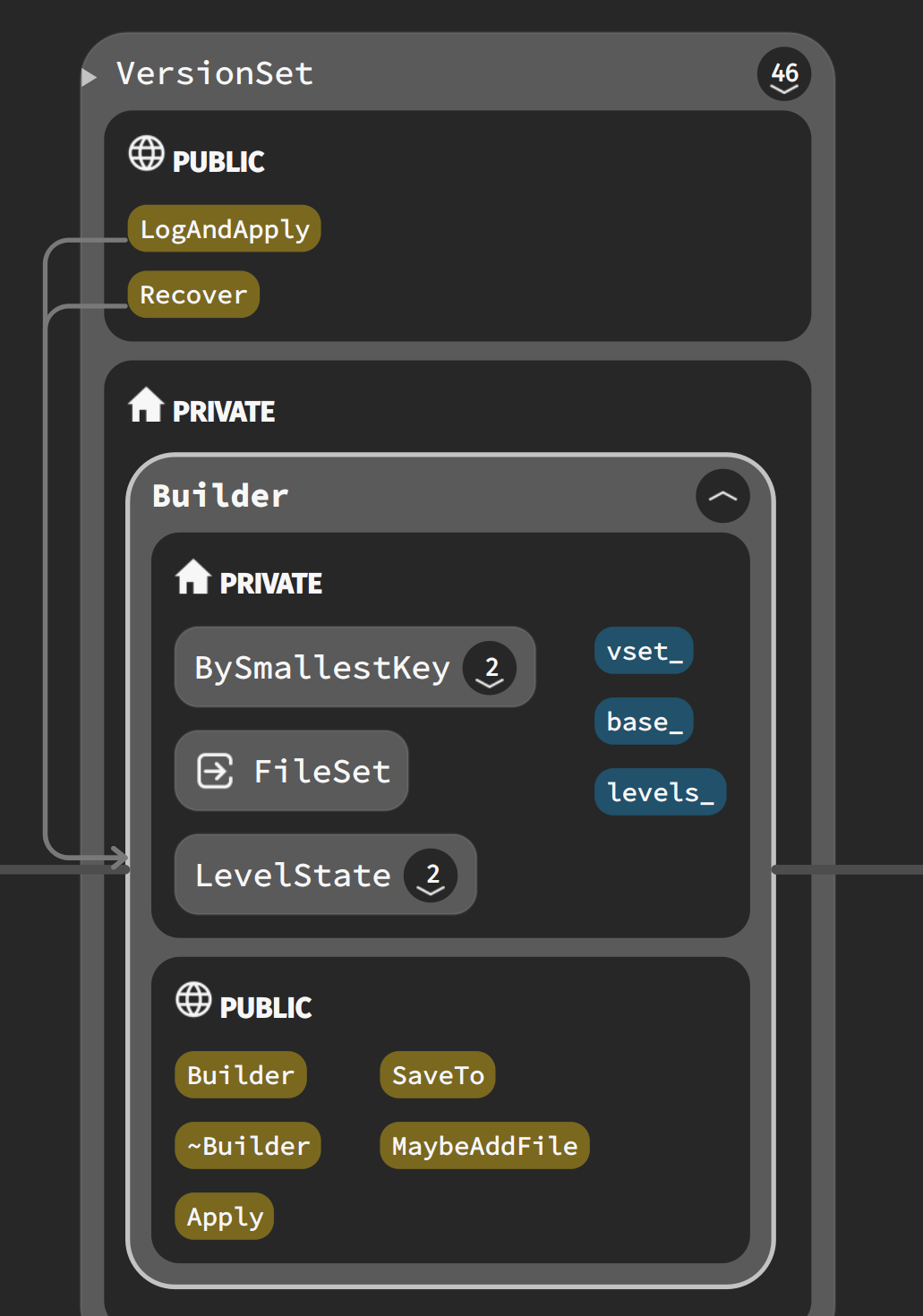
// 构造函数 // Initialize a builder with the files from *base and other info from *vset Builder(VersionSet* vset, Version* base) : vset_(vset), base_(base) { base_->Ref(); BySmallestKey cmp; cmp.internal_comparator = &vset_->icmp_; for (int level = 0; level < config::kNumLevels; level++) { levels_[level].added_files = newFileSet(cmp); } }
这里只是完成了一些初始化工作。 这里使用了一个BySmallestKey比较器,简单看下实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14
// Helper to sort by v->files_[file_number].smallest structBySmallestKey { const InternalKeyComparator* internal_comparator;
booloperator()(FileMetaData* f1, FileMetaData* f2)const{ int r = internal_comparator->Compare(f1->smallest, f2->smallest); // 按照smallest key比较 if (r != 0) { return (r < 0); // 按照最小key升序 } else { // Break ties by file number return (f1->number < f2->number); // 按照文件序列升序,由于文件序列号越小,文件越旧,所以这里是按照文件从旧到新 } } };
// Apply all of the edits in *edit to the current state. voidApply(VersionEdit* edit){ // Update compaction pointers for (size_t i = 0; i < edit->compact_pointers_.size(); i++) { constint level = edit->compact_pointers_[i].first; // first为 level vset_->compact_pointer_[level] = edit->compact_pointers_[i].second.Encode().ToString(); // second 为 这一level开始compaction的key }
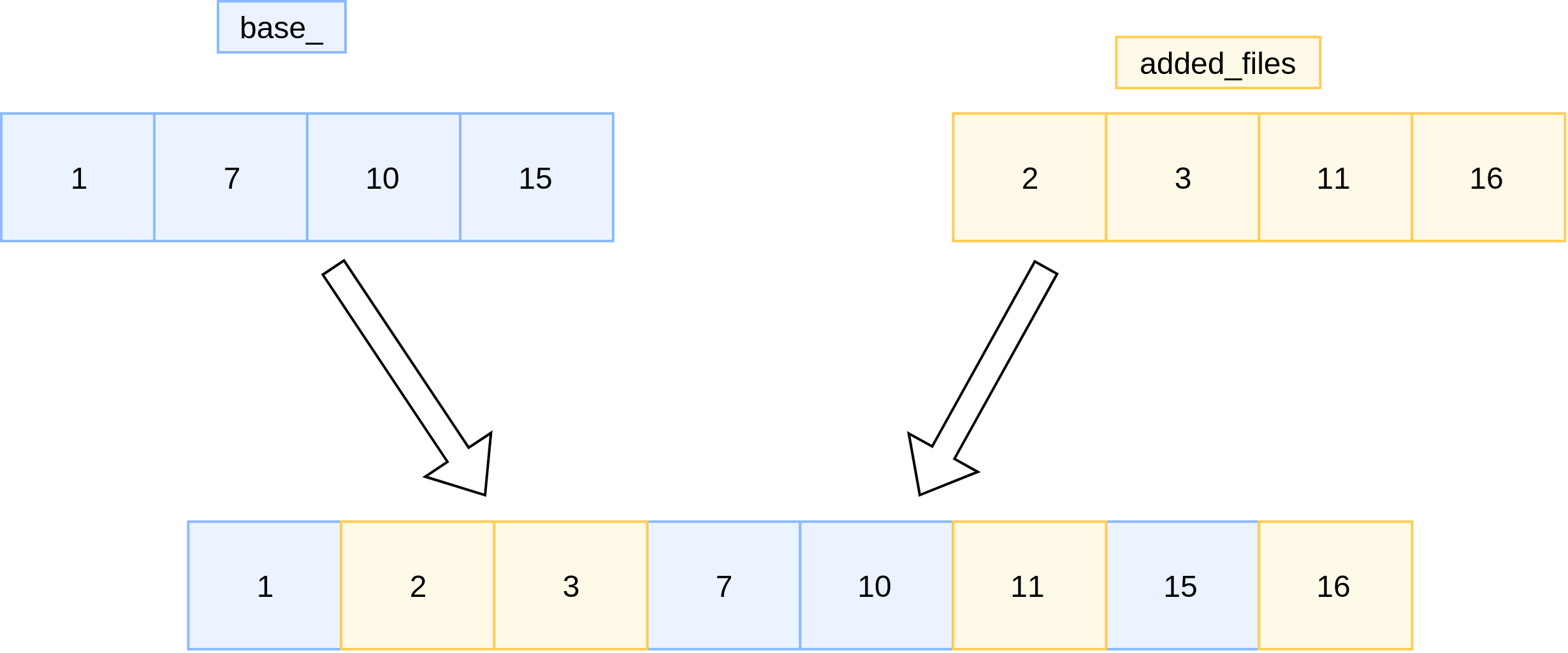
// Save the current state in *v. voidSaveTo(Version* v){ BySmallestKey cmp; // 按照smallestkey比较,如果key相同,按照file number比较。 cmp.internal_comparator = &vset_->icmp_; for (int level = 0; level < config::kNumLevels; level++) { // 一层层的合并 // Merge the set of added files with the set of pre-existing files. // Drop any deleted files. Store the result in *v. const std::vector<FileMetaData*>& base_files = base_->files_[level]; std::vector<FileMetaData*>::const_iterator base_iter = base_files.begin(); std::vector<FileMetaData*>::const_iterator base_end = base_files.end(); const FileSet* added_files = levels_[level].added_files; v->files_[level].reserve(base_files.size() + added_files->size()); // 小于added_files的key 的 当前版本中的文件,全部加入新版本中 for (constauto& added_file : *added_files) { // Add all smaller files listed in base_
voidVersionSet::Finalize(Version* v){ // Precomputed best level for next compaction int best_level = -1; double best_score = -1;
for (int level = 0; level < config::kNumLevels - 1; level++) { double score; if (level == 0) { // level0 单独处理,文件数量 超过kL0_CompactionTrigger时,就trigger compaction // We treat level-0 specially by bounding the number of files // instead of number of bytes for two reasons: // // (1) With larger write-buffer sizes, it is nice not to do too // many level-0 compactions. // // (2) The files in level-0 are merged on every read and // therefore we wish to avoid too many files when the individual // file size is small (perhaps because of a small write-buffer // setting, or very high compression ratios, or lots of // overwrites/deletions). score = v->files_[level].size() / static_cast<double>(config::kL0_CompactionTrigger); // static const int kL0_CompactionTrigger = 4; } else { // 其余level 用文件size来比较 // Compute the ratio of current size to size limit. constuint64_t level_bytes = TotalFileSize(v->files_[level]); score = static_cast<double>(level_bytes) / MaxBytesForLevel(options_, level); }
// 下面和Manifest文件相关 // Initialize new descriptor log file if necessary by creating // a temporary file that contains a snapshot of the current version. std::string new_manifest_file; Status s; // 创建manifest writer if (descriptor_log_ == nullptr) { // 首次进入,创建manifest writer // No reason to unlock *mu here since we only hit this path in the // first call to LogAndApply (when opening the database). assert(descriptor_file_ == nullptr); // new_manifest_file为当前manifest文件路径 new_manifest_file = DescriptorFileName(dbname_, manifest_file_number_); edit->SetNextFile(next_file_number_); // 创建文件 s = env_->NewWritableFile(new_manifest_file, &descriptor_file_); if (s.ok()) { // 创建manifest写者,从本质上来看,manifest和log文件的布局完全相同 descriptor_log_ = new log::Writer(descriptor_file_); // 保存一次当前系统的快照内容到manifest中 s = WriteSnapshot(descriptor_log_); } }
// Unlock during expensive MANIFEST log write { mu->Unlock();
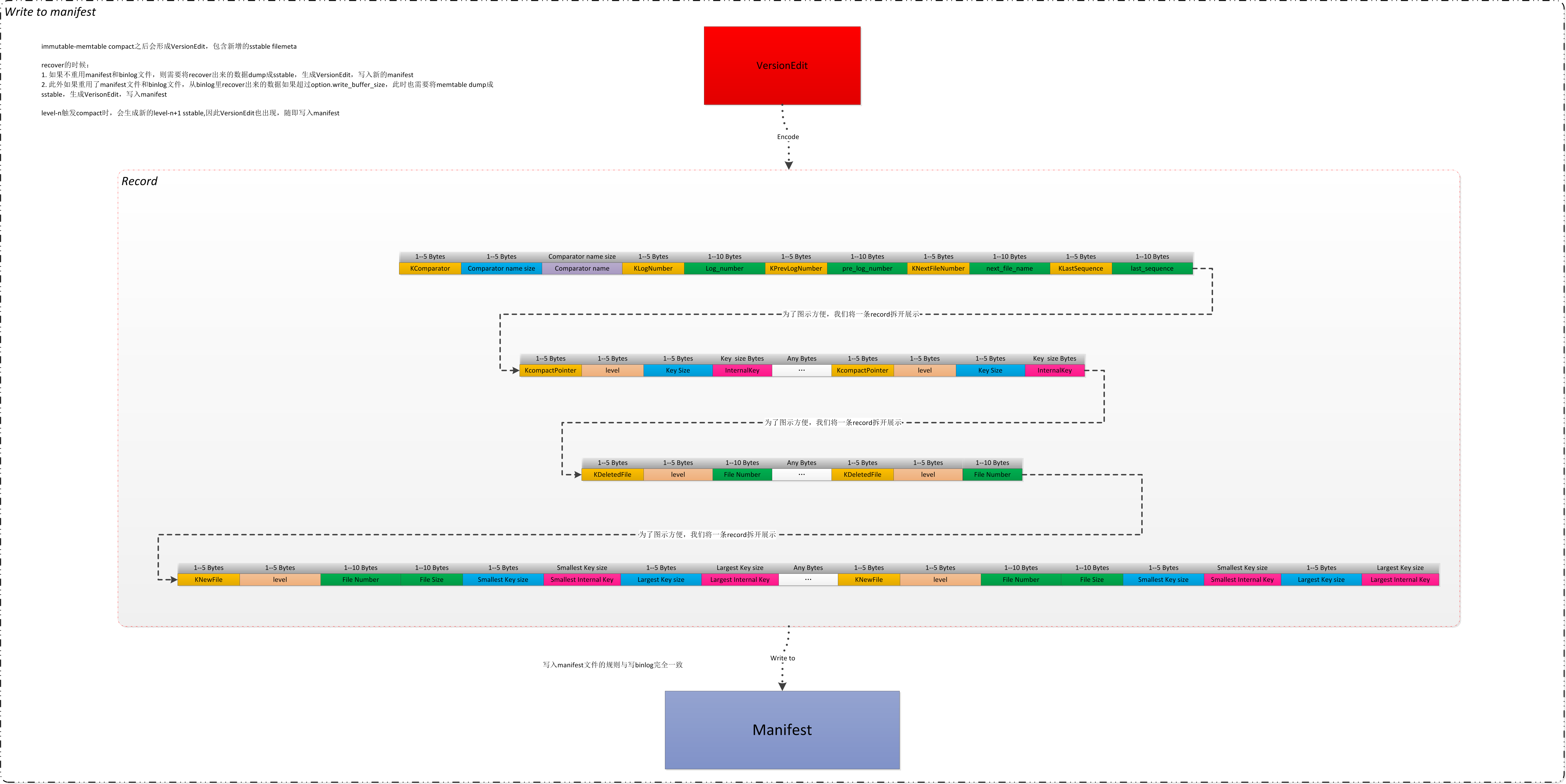
// 将当前edit内容编码成一条recored,添加到manifest中 // Write new record to MANIFEST log if (s.ok()) { std::string record; // edit内容编码到record !!, 可以看一下是怎么编码的,这样就知道manifest文件中保存的内容布局了 edit->EncodeTo(&record); // 写入manifest文件 s = descriptor_log_->AddRecord(record); if (s.ok()) { // 刷新到设备上 s = descriptor_file_->Sync(); } if (!s.ok()) { Log(options_->info_log, "MANIFEST write: %s\n", s.ToString().c_str()); } }
// 更新Current指针 // If we just created a new descriptor file, install it by writing a // new CURRENT file that points to it. if (s.ok() && !new_manifest_file.empty()) { s = SetCurrentFile(env_, dbname_, manifest_file_number_); }
// Tag numbers for serialized VersionEdit. These numbers are written to // disk and should not be changed. enumTag { kComparator = 1, kLogNumber = 2, kNextFileNumber = 3, kLastSequence = 4, kCompactPointer = 5, kDeletedFile = 6, kNewFile = 7, // 8 was used for large value refs kPrevLogNumber = 9 };