voidDBImpl::MaybeScheduleCompaction(){ mutex_.AssertHeld(); if (background_compaction_scheduled_) { // Already scheduled } elseif (shutting_down_.load(std::memory_order_acquire)) { // DB is being deleted; no more background compactions } elseif (!bg_error_.ok()) { // Already got an error; no more changes } elseif (imm_ == nullptr && manual_compaction_ == nullptr && !versions_->NeedsCompaction()) { // 递归结束点,防止无限递归 // No work to be done } else { background_compaction_scheduled_ = true; env_->Schedule(&DBImpl::BGWork, this); } }
voidDBImpl::BackgroundCall(){ MutexLock l(&mutex_); assert(background_compaction_scheduled_); if (shutting_down_.load(std::memory_order_acquire)) { // No more background work when shutting down. } elseif (!bg_error_.ok()) { // No more background work after a background error. } else { BackgroundCompaction(); }
background_compaction_scheduled_ = false;
// Previous compaction may have produced too many files in a level, // so reschedule another compaction if needed. // 递归调用compaction,因为有可能这次compaction产生了过多的sst MaybeScheduleCompaction(); background_work_finished_signal_.SignalAll(); }
// Save the contents of the memtable as a new Table VersionEdit edit; Version* base = versions_->current(); base->Ref(); // 将 数据写入到第0层(实际上不一定是第0层) Status s = WriteLevel0Table(imm_, &edit, base); base->Unref();
if (s.ok() && shutting_down_.load(std::memory_order_acquire)) { s = Status::IOError("Deleting DB during memtable compaction"); }
// Replace immutable memtable with the generated Table if (s.ok()) { edit.SetPrevLogNumber(0); edit.SetLogNumber(logfile_number_); // Earlier logs no longer needed // 应用生成的一个VersionEdit到当前VersionSet s = versions_->LogAndApply(&edit, &mutex_); }
if (s.ok()) { // Commit to the new state // 减少计数,引用计数归0时会delete当前immemtable imm_->Unref(); imm_ = nullptr; has_imm_.store(false, std::memory_order_release); RemoveObsoleteFiles(); } else { RecordBackgroundError(s); } }
// Note that if file_size is zero, the file has been deleted and // should not be added to the manifest. int level = 0; if (s.ok() && meta.file_size > 0) { const Slice min_user_key = meta.smallest.user_key(); const Slice max_user_key = meta.largest.user_key(); if (base != nullptr) { // 2.SSTable 应该写入到哪个level? level = base->PickLevelForMemTableOutput(min_user_key, max_user_key); } // 3. 生成VersionEdit,给后序Manifest做记录 edit->AddFile(level, meta.number, meta.file_size, meta.smallest, meta.largest); }
// Maximum level to which a new compacted memtable is pushed if it // does not create overlap. We try to push to level 2 to avoid the // relatively expensive level 0=>1 compactions and to avoid some // expensive manifest file operations. We do not push all the way to // the largest level since that can generate a lot of wasted disk // space if the same key space is being repeatedly overwritten. staticconstint kMaxMemCompactLevel = 2;
intVersion::PickLevelForMemTableOutput(const Slice& smallest_user_key, const Slice& largest_user_key){ int level = 0; // 如果与level 0有重叠,直接return 0 if (!OverlapInLevel(0, &smallest_user_key, &largest_user_key)) { // Push to next level if there is no overlap in next level, // and the #bytes overlapping in the level after that are limited. InternalKey start(smallest_user_key, kMaxSequenceNumber, kValueTypeForSeek); InternalKey limit(largest_user_key, 0, static_cast<ValueType>(0)); std::vector<FileMetaData*> overlaps; while (level < config::kMaxMemCompactLevel) { // 最高到kMaxMemCompactLevel // 与level+1有重叠 if (OverlapInLevel(level + 1, &smallest_user_key, &largest_user_key)) { break; } if (level + 2 < config::kNumLevels) { // 与祖父level的重叠size过大,则直接break // Check that file does not overlap too many grandparent bytes. GetOverlappingInputs(level + 2, &start, &limit, &overlaps); constint64_t sum = TotalFileSize(overlaps); if (sum > MaxGrandParentOverlapBytes(vset_->options_)) { break; } } level++; } } return level; }
// Add the specified file at the specified number. // REQUIRES: This version has not been saved (see VersionSet::SaveTo) // REQUIRES: "smallest" and "largest" are smallest and largest keys in file voidAddFile(int level, uint64_t file, uint64_t file_size, const InternalKey& smallest, const InternalKey& largest){ FileMetaData f; f.number = file; f.file_size = file_size; f.smallest = smallest; f.largest = largest; new_files_.push_back(std::make_pair(level, f)); }
voidDBImpl::MaybeScheduleCompaction(){ mutex_.AssertHeld(); if (background_compaction_scheduled_) { // Already scheduled } elseif (shutting_down_.load(std::memory_order_acquire)) { // DB is being deleted; no more background compactions } elseif (!bg_error_.ok()) { // Already got an error; no more changes } elseif (imm_ == nullptr && manual_compaction_ == nullptr && !versions_->NeedsCompaction()) { // 递归结束点,防止无限递归 // No work to be done } else { background_compaction_scheduled_ = true; env_->Schedule(&DBImpl::BGWork, this); } }
可以看到,正常情况下只要满足一下3种条件中任何一个都会触发一次compaction:
imm != null, memtable已经转化为immtable,需要及时dump到外存中。
manual_compaction, 手动compaction
versions->NeedCompaction()
前两种都好说,重点看一下第3种:
1 2 3 4 5
// Returns true iff some level needs a compaction. boolNeedsCompaction()const{ Version* v = current_; return (v->compaction_score_ >= 1) || (v->file_to_compact_ != nullptr); }
voidVersionSet::Finalize(Version* v){ // Precomputed best level for next compaction int best_level = -1; double best_score = -1; // 最高level for (int level = 0; level < config::kNumLevels - 1; level++) { double score; if (level == 0) { // We treat level-0 specially by bounding the number of files // instead of number of bytes for two reasons: // // (1) With larger write-buffer sizes, it is nice not to do too // many level-0 compactions. // // (2) The files in level-0 are merged on every read and // therefore we wish to avoid too many files when the individual // file size is small (perhaps because of a small write-buffer // setting, or very high compression ratios, or lots of // overwrites/deletions). score = v->files_[level].size() / static_cast<double>(config::kL0_CompactionTrigger); } else { // Compute the ratio of current size to size limit. constuint64_t level_bytes = TotalFileSize(v->files_[level]); score = static_cast<double>(level_bytes) / MaxBytesForLevel(options_, level); }
else { // Compute the ratio of current size to size limit. constuint64_t level_bytes = TotalFileSize(v->files_[level]); score = static_cast<double>(level_bytes) / MaxBytesForLevel(options_, level); }
1 2 3 4 5 6 7 8 9 10 11 12
staticdoubleMaxBytesForLevel(const Options* options, int level){ // Note: the result for level zero is not really used since we set // the level-0 compaction threshold based on number of files.
// Result for both level-0 and level-1 double result = 10. * 1048576.0; // 默认是10M while (level > 1) { result *= 10; level--; } return result; }
int refs; int allowed_seeks; // !!!Seeks allowed until compaction uint64_t number; uint64_t file_size; // File size in bytes InternalKey smallest; // Smallest internal key served by table InternalKey largest; // Largest internal key served by table };
// Apply all of the edits in *edit to the current state. voidApply(VersionEdit* edit){ // Update compaction pointers for (size_t i = 0; i < edit->compact_pointers_.size(); i++) { constint level = edit->compact_pointers_[i].first; vset_->compact_pointer_[level] = edit->compact_pointers_[i].second.Encode().ToString(); }
// Delete files for (constauto& deleted_file_set_kvp : edit->deleted_files_) { constint level = deleted_file_set_kvp.first; constuint64_t number = deleted_file_set_kvp.second; levels_[level].deleted_files.insert(number); }
// Add new files for (size_t i = 0; i < edit->new_files_.size(); i++) { constint level = edit->new_files_[i].first; FileMetaData* f = newFileMetaData(edit->new_files_[i].second); f->refs = 1;
// We arrange to automatically compact this file after // a certain number of seeks. Let's assume: // (1) One seek costs 10ms // (2) Writing or reading 1MB costs 10ms (100MB/s) // (3) A compaction of 1MB does 25MB of IO: // 1MB read from this level // 10-12MB read from next level (boundaries may be misaligned) // 10-12MB written to next level // This implies that 25 seeks cost the same as the compaction // of 1MB of data. I.e., one seek costs approximately the // same as the compaction of 40KB of data. We are a little // conservative and allow approximately one seek for every 16KB // of data before triggering a compaction. f->allowed_seeks = static_cast<int>((f->file_size / 16384U)); if (f->allowed_seeks < 100) f->allowed_seeks = 100;
// Pick level and inputs for a new compaction. // Returns nullptr if there is no compaction to be done. // Otherwise returns a pointer to a heap-allocated object that // describes the compaction. Caller should delete the result. Compaction* PickCompaction();
Compaction* VersionSet::PickCompaction(){ Compaction* c; int level;
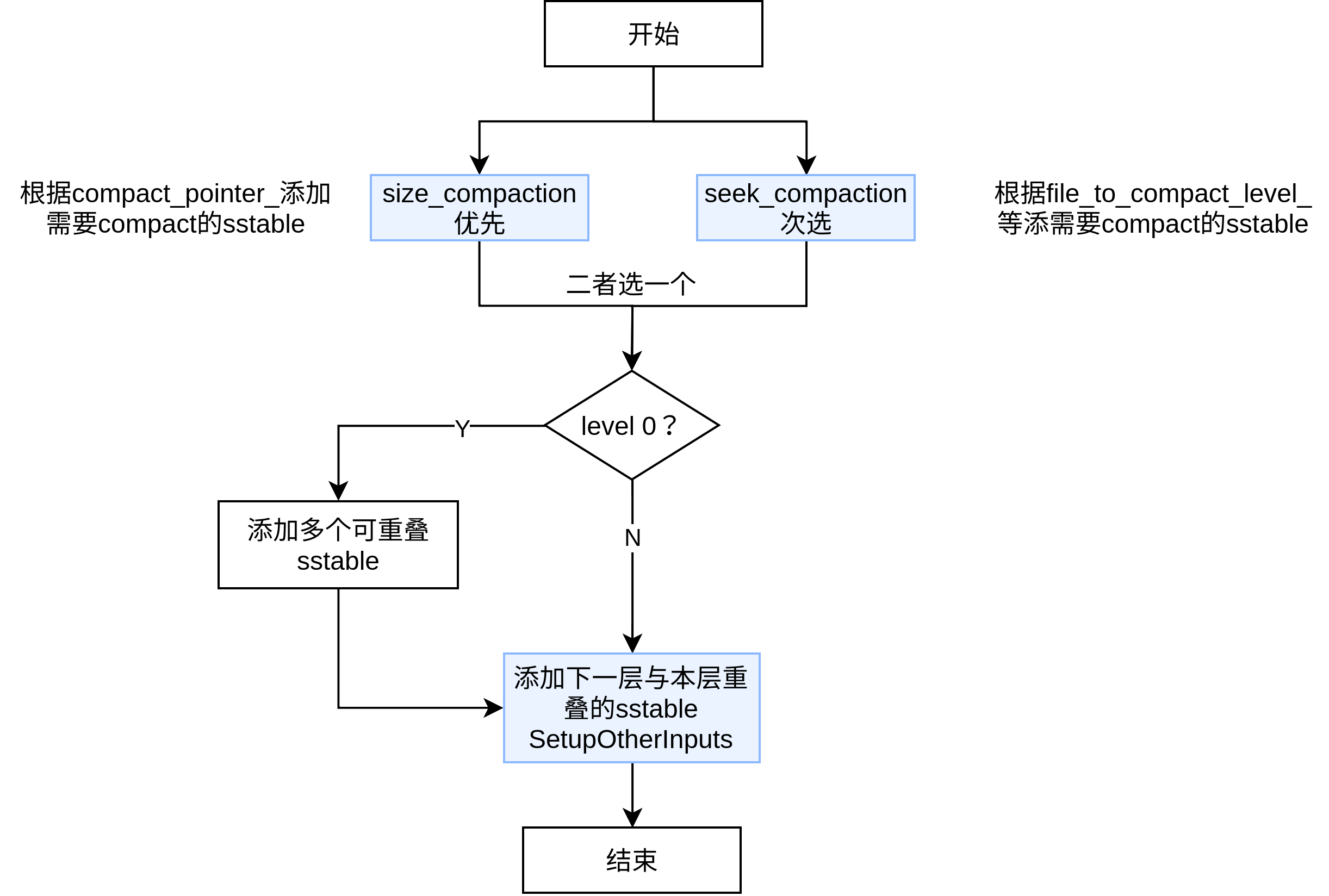
// 优先考虑 size_compaction, 再考虑seek_compaction. // We prefer compactions triggered by too much data in a level over // the compactions triggered by seeks. constbool size_compaction = (current_->compaction_score_ >= 1); constbool seek_compaction = (current_->file_to_compact_ != nullptr); if (size_compaction) { level = current_->compaction_level_; assert(level >= 0); assert(level + 1 < config::kNumLevels); c = newCompaction(options_, level);
// Pick the first file that comes after compact_pointer_[level] for (size_t i = 0; i < current_->files_[level].size(); i++) { FileMetaData* f = current_->files_[level][i]; if (compact_pointer_[level].empty() || icmp_.Compare(f->largest.Encode(), compact_pointer_[level]) > 0) { c->inputs_[0].push_back(f); break; } } if (c->inputs_[0].empty()) { // Wrap-around to the beginning of the key space c->inputs_[0].push_back(current_->files_[level][0]); } } elseif (seek_compaction) { level = current_->file_to_compact_level_; c = newCompaction(options_, level); c->inputs_[0].push_back(current_->file_to_compact_); } else { returnnullptr; }
// Files in level 0 may overlap each other, so pick up all overlapping ones if (level == 0) { InternalKey smallest, largest; GetRange(c->inputs_[0], &smallest, &largest); // Note that the next call will discard the file we placed in // c->inputs_[0] earlier and replace it with an overlapping set // which will include the picked file. current_->GetOverlappingInputs(0, &smallest, &largest, &c->inputs_[0]); assert(!c->inputs_[0].empty()); }
// We prefer compactions triggered by too much data in a level over // the compactions triggered by seeks. constbool size_compaction = (current_->compaction_score_ >= 1); constbool seek_compaction = (current_->file_to_compact_ != nullptr);
if (size_compaction) { level = current_->compaction_level_; assert(level >= 0); assert(level + 1 < config::kNumLevels); c = newCompaction(options_, level);
// Pick the first file that comes after compact_pointer_[level] for (size_t i = 0; i < current_->files_[level].size(); i++) { FileMetaData* f = current_->files_[level][i]; if (compact_pointer_[level].empty() || icmp_.Compare(f->largest.Encode(), compact_pointer_[level]) > 0) { c->inputs_[0].push_back(f); break; } } if (c->inputs_[0].empty()) { // Wrap-around to the beginning of the key space c->inputs_[0].push_back(current_->files_[level][0]); } }
inputs_数组中存放的是输入源。
1 2
// Each compaction reads inputs from "level_" and "level_+1" std::vector<FileMetaData*> inputs_[2]; // The two sets of inputs
// 找到第一个文件,其最大key比 compact_pointer_[level]的key大 // Pick the first file that comes after compact_pointer_[level] for (size_t i = 0; i < current_->files_[level].size(); i++) { FileMetaData* f = current_->files_[level][i]; if (compact_pointer_[level].empty() || icmp_.Compare(f->largest.Encode(), compact_pointer_[level]) > 0) { c->inputs_[0].push_back(f); break; } } // 如果找不到这样的文件,从level头开始(round-robin) if (c->inputs_[0].empty()) { // Wrap-around to the beginning of the key space c->inputs_[0].push_back(current_->files_[level][0]); }
size_compation中只用确定一个要输入的 sstable文件。 接着看:
1 2 3 4 5 6 7 8 9 10
// Files in level 0 may overlap each other, so pick up all overlapping ones if (level == 0) { InternalKey smallest, largest; GetRange(c->inputs_[0], &smallest, &largest); // Note that the next call will discard the file we placed in // c->inputs_[0] earlier and replace it with an overlapping set // which will include the picked file. current_->GetOverlappingInputs(0, &smallest, &largest, &c->inputs_[0]); assert(!c->inputs_[0].empty()); }
// Get entire range covered by compaction InternalKey all_start, all_limit; // 计算leveln level n+1的range GetRange2(c->inputs_[0], c->inputs_[1], &all_start, &all_limit);
// See if we can grow the number of inputs in "level" without // changing the number of "level+1" files we pick up. if (!c->inputs_[1].empty()) { std::vector<FileMetaData*> expanded0; current_->GetOverlappingInputs(level, &all_start, &all_limit, &expanded0); AddBoundaryInputs(icmp_, current_->files_[level], &expanded0); constint64_t inputs0_size = TotalFileSize(c->inputs_[0]); constint64_t inputs1_size = TotalFileSize(c->inputs_[1]); constint64_t expanded0_size = TotalFileSize(expanded0); if (expanded0.size() > c->inputs_[0].size() && inputs1_size + expanded0_size < ExpandedCompactionByteSizeLimit(options_)) { InternalKey new_start, new_limit; GetRange(expanded0, &new_start, &new_limit); std::vector<FileMetaData*> expanded1; current_->GetOverlappingInputs(level + 1, &new_start, &new_limit, &expanded1); if (expanded1.size() == c->inputs_[1].size()) { Log(options_->info_log, "Expanding@%d %d+%d (%ld+%ld bytes) to %d+%d (%ld+%ld bytes)\n", level, int(c->inputs_[0].size()), int(c->inputs_[1].size()), long(inputs0_size), long(inputs1_size), int(expanded0.size()), int(expanded1.size()), long(expanded0_size), long(inputs1_size)); smallest = new_start; largest = new_limit; c->inputs_[0] = expanded0; c->inputs_[1] = expanded1; GetRange2(c->inputs_[0], c->inputs_[1], &all_start, &all_limit); } } }
// Compute the set of grandparent files that overlap this compaction // (parent == level+1; grandparent == level+2) if (level + 2 < config::kNumLevels) { current_->GetOverlappingInputs(level + 2, &all_start, &all_limit, &c->grandparents_); }
// Update the place where we will do the next compaction for this level. // We update this immediately instead of waiting for the VersionEdit // to be applied so that if the compaction fails, we will try a different // key range next time. compact_pointer_[level] = largest.Encode().ToString(); c->edit_.SetCompactPointer(level, largest); }
// Maximum number of bytes in all compacted files. We avoid expanding // the lower level file set of a compaction if it would make the // total compaction cover more than this many bytes. staticint64_tExpandedCompactionByteSizeLimit(const Options* options){ return25 * TargetFileSize(options); // 默认是50M }
// Leveldb will write up to this amount of bytes to a file before // switching to a new one. // Most clients should leave this parameter alone. However if your // filesystem is more efficient with larger files, you could // consider increasing the value. The downside will be longer // compactions and hence longer latency/performance hiccups. // Another reason to increase this parameter might be when you are // initially populating a large database. size_t max_file_size = 2 * 1024 * 1024;
// Update the place where we will do the next compaction for this level. // We update this immediately instead of waiting for the VersionEdit // to be applied so that if the compaction fails, we will try a different // key range next time. compact_pointer_[level] = largest.Encode().ToString(); c->edit_.SetCompactPointer(level, largest);
// Extracts the largest file b1 from |compaction_files| and then searches for a // b2 in |level_files| for which user_key(u1) = user_key(l2). If it finds such a // file b2 (known as a boundary file) it adds it to |compaction_files| and then // searches again using this new upper bound. // // If there are two blocks, b1=(l1, u1) and b2=(l2, u2) and // user_key(u1) = user_key(l2), and if we compact b1 but not b2 then a // subsequent get operation will yield an incorrect result because it will // return the record from b2 in level i rather than from b1 because it searches // level by level for records matching the supplied user key. // // parameters: // in level_files: List of files to search for boundary files. // in/out compaction_files: List of files to extend by adding boundary files. voidAddBoundaryInputs(const InternalKeyComparator& icmp, const std::vector<FileMetaData*>& level_files, std::vector<FileMetaData*>* compaction_files){ InternalKey largest_key;
// Quick return if compaction_files is empty. if (!FindLargestKey(icmp, *compaction_files, &largest_key)) { return; }
// Search level-0 in order from newest to oldest. // 加入第0层文件 std::vector<FileMetaData*> tmp; tmp.reserve(files_[0].size()); for (uint32_t i = 0; i < files_[0].size(); i++) { FileMetaData* f = files_[0][i]; if (ucmp->Compare(user_key, f->smallest.user_key()) >= 0 && ucmp->Compare(user_key, f->largest.user_key()) <= 0) { tmp.push_back(f); } } if (!tmp.empty()) { // 按照新旧排序,由新到旧 std::sort(tmp.begin(), tmp.end(), NewestFirst); for (uint32_t i = 0; i < tmp.size(); i++) { if (!(*func)(arg, 0, tmp[i])) { // 调用State::Match, 由于第0层无序,所以可能需要多次调用 return; } } }
// Search other levels. for (int level = 1; level < config::kNumLevels; level++) { size_t num_files = files_[level].size(); if (num_files == 0) continue;
// Binary search to find earliest index whose largest key >= internal_key. uint32_t index = FindFile(vset_->icmp_, files_[level], internal_key); if (index < num_files) { FileMetaData* f = files_[level][index]; if (ucmp->Compare(user_key, f->smallest.user_key()) < 0) { // All of "f" is past any data for user_key } else { // 到这里,确定了 internal_key 一定是在 本file的key range中,即overlap if (!(*func)(arg, level, f)) { // 一个level,只会调用 return; } } } } }
staticboolMatch(void* arg, int level, FileMetaData* f){ State* state = reinterpret_cast<State*>(arg);
if (state->stats->seek_file == nullptr && state->last_file_read != nullptr) { // 走到这个分支,说明Match函数至少已经被调用过一次,也就是说至少浪费了一次io // We have had more than one seek for this read. Charge the 1st file. state->stats->seek_file = state->last_file_read; state->stats->seek_file_level = state->last_file_read_level; } state->last_file_read = f; state->last_file_read_level = level;
state->s = state->vset->table_cache_->Get(*state->options, f->number, f->file_size, state->ikey, &state->saver, SaveValue); if (!state->s.ok()) { state->found = true; returnfalse; // 不再search } switch (state->saver.state) { case kNotFound: returntrue; // Keep searching in other files case kFound: state->found = true; returnfalse; // 不再search case kDeleted: returnfalse; // 不再search case kCorrupt: state->s = Status::Corruption("corrupted key for ", state->saver.user_key); state->found = true; returnfalse; }
// Not reached. Added to avoid false compilation warnings of // "control reaches end of non-void function". returnfalse; }
从这个函数中也终于可以找到seek_file被赋值的地方:
1 2 3 4 5 6
if (state->stats->seek_file == nullptr && state->last_file_read != nullptr) { // 走到这个分支,说明Match函数至少已经被调用过一次,也就是说至少浪费了一次io // We have had more than one seek for this read. Charge the 1st file. state->stats->seek_file = state->last_file_read; state->stats->seek_file_level = state->last_file_read_level; }
boolCompaction::IsTrivialMove()const{ const VersionSet* vset = input_version_->vset_; // Avoid a move if there is lots of overlapping grandparent data. // Otherwise, the move could create a parent file that will require // a very expensive merge later on. return (num_input_files(0) == 1 && num_input_files(1) == 0 && TotalFileSize(grandparents_) <= MaxGrandParentOverlapBytes(vset->options_)); }
// Creates a SnapshotImpl and appends it to the end of the list. SnapshotImpl* New(SequenceNumber sequence_number){ assert(empty() || newest()->sequence_number_ <= sequence_number);
// Removes a SnapshotImpl from this list. // // The snapshot must have been created by calling New() on this list. // // The snapshot pointer should not be const, because its memory is // deallocated. However, that would force us to change DB::ReleaseSnapshot(), // which is in the API, and currently takes a const Snapshot. voidDelete(const SnapshotImpl* snapshot){ #if !defined(NDEBUG) assert(snapshot->list_ == this); #endif// !defined(NDEBUG) snapshot->prev_->next_ = snapshot->next_; snapshot->next_->prev_ = snapshot->prev_; delete snapshot; }
private: // Dummy head of doubly-linked list of snapshots SnapshotImpl head_; };
// Release mutex while we're actually doing the compaction work mutex_.Unlock();
input->SeekToFirst(); Status status; ParsedInternalKey ikey; std::string current_user_key; bool has_current_user_key = false; SequenceNumber last_sequence_for_key = kMaxSequenceNumber; while (input->Valid() && !shutting_down_.load(std::memory_order_acquire)) { // Prioritize immutable compaction work // 首先做immtable的dump if (has_imm_.load(std::memory_order_relaxed)) { constuint64_t imm_start = env_->NowMicros(); mutex_.Lock(); if (imm_ != nullptr) { CompactMemTable(); // Wake up MakeRoomForWrite() if necessary. background_work_finished_signal_.SignalAll(); } mutex_.Unlock(); imm_micros += (env_->NowMicros() - imm_start); }
Slice key = input->key(); if (compact->compaction->ShouldStopBefore(key) && compact->builder != nullptr) { //检查当前输出文件是否与level+2层文件有过多冲突,如果是就要完成当前输出文件,并产生新的输出文件 status = FinishCompactionOutputFile(compact, input); if (!status.ok()) { break; } } // 下面这里是关键!! // Handle key/value, add to state, etc. bool drop = false; if (!ParseInternalKey(key, &ikey)) { // Do not hide error keys current_user_key.clear(); has_current_user_key = false; last_sequence_for_key = kMaxSequenceNumber; } else { // 正常情况下走这里 if (!has_current_user_key || user_comparator()->Compare(ikey.user_key, Slice(current_user_key)) != 0) { // 某个user_key第一次出现 // First occurrence of this user key current_user_key.assign(ikey.user_key.data(), ikey.user_key.size()); has_current_user_key = true; // 第一次出现的user_key不允许删除 last_sequence_for_key = kMaxSequenceNumber; }
if (last_sequence_for_key <= compact->smallest_snapshot) { // 前一个key的序列号都小了,本key肯定更小,直接抛弃 // Hidden by an newer entry for same user key drop = true; // (A) } elseif (ikey.type == kTypeDeletion && // 前一个key还在snaphost内,本key虽然是离snapshot最近的key,但是本key是删除节点 ikey.sequence <= compact->smallest_snapshot && compact->compaction->IsBaseLevelForKey(ikey.user_key)) { // 在是删除节点的同时,还必须保证本key一定是"最底层"的key(也就是更底层没有该key),否则删除这个key,更底层的key将被重新激活 // !!!!!! 待完善 // For this user key: // (1) there is no data in higher levels // (2) data in lower levels will have larger sequence numbers // (3) data in layers that are being compacted here and have // smaller sequence numbers will be dropped in the next // few iterations of this loop (by rule (A) above). // Therefore this deletion marker is obsolete and can be dropped. drop = true; }
last_sequence_for_key = ikey.sequence; } // 不需要drop的文件直接写入 if (!drop) { // 不需要删除,则写入到文件 // Open output file if necessary if (compact->builder == nullptr) { status = OpenCompactionOutputFile(compact); if (!status.ok()) { break; } } if (compact->builder->NumEntries() == 0) { compact->current_output()->smallest.DecodeFrom(key); } compact->current_output()->largest.DecodeFrom(key); compact->builder->Add(key, input->value());
// Close output file if it is big enough if (compact->builder->FileSize() >= compact->compaction->MaxOutputFileSize()) { status = FinishCompactionOutputFile(compact, input); if (!status.ok()) { break; } } }
input->Next(); }
if (status.ok() && shutting_down_.load(std::memory_order_acquire)) { status = Status::IOError("Deleting DB during compaction"); } if (status.ok() && compact->builder != nullptr) { status = FinishCompactionOutputFile(compact, input); } if (status.ok()) { status = input->status(); } delete input; input = nullptr;
CompactionStats stats; stats.micros = env_->NowMicros() - start_micros - imm_micros; for (int which = 0; which < 2; which++) { for (int i = 0; i < compact->compaction->num_input_files(which); i++) { stats.bytes_read += compact->compaction->input(which, i)->file_size; } } for (size_t i = 0; i < compact->outputs.size(); i++) { stats.bytes_written += compact->outputs[i].file_size; }
// Level-0 files have to be merged together. For other levels, // we will make a concatenating iterator per level. // TODO(opt): use concatenating iterator for level-0 if there is no overlap constint space = (c->level() == 0 ? c->inputs_[0].size() + 1 : 2); // !!! list中的每个iter,都指向了一个即将被compaction的sstable Iterator** list = new Iterator*[space]; int num = 0; for (int which = 0; which < 2; which++) { if (!c->inputs_[which].empty()) { if (c->level() + which == 0) { // 对第0层的files,通过table_cache创建iter const std::vector<FileMetaData*>& files = c->inputs_[which]; for (size_t i = 0; i < files.size(); i++) { list[num++] = table_cache_->NewIterator(options, files[i]->number, files[i]->file_size); } } else { // 非第0层的fiels,使用TwoLevelIterator来迭代(index iter 和 data iter) // Create concatenating iterator for the files from this level list[num++] = NewTwoLevelIterator( new Version::LevelFileNumIterator(icmp_, &c->inputs_[which]), &GetFileIterator, table_cache_, options); } } } assert(num <= space); // 所有需要的compaction file都有一个iter,现在需要归并排序,这通过mergeiteraotr实现 Iterator* result = NewMergingIterator(&icmp_, list, num); delete[] list; return result; }
// 下面这里是关键!! // Handle key/value, add to state, etc. bool drop = false; if (!ParseInternalKey(key, &ikey)) { // Do not hide error keys current_user_key.clear(); has_current_user_key = false; last_sequence_for_key = kMaxSequenceNumber; } else { // 正常情况下走这里 if (!has_current_user_key || user_comparator()->Compare(ikey.user_key, Slice(current_user_key)) != 0) { // 某个user_key第一次出现 // First occurrence of this user key current_user_key.assign(ikey.user_key.data(), ikey.user_key.size()); has_current_user_key = true; // 第一次出现的user_key不允许删除 last_sequence_for_key = kMaxSequenceNumber; }
if (last_sequence_for_key <= compact->smallest_snapshot) { // 前一个key的序列号都小了,本key肯定更小,直接抛弃 // Hidden by an newer entry for same user key drop = true; // (A) } elseif (ikey.type == kTypeDeletion && // 前一个key还在snaphost内,本key虽然是离snapshot最近的key,但是本key是删除节点 ikey.sequence <= compact->smallest_snapshot && compact->compaction->IsBaseLevelForKey(ikey.user_key)) { // 在是删除节点的同时,还必须保证本key一定是"最底层"的key(也就是更底层没有该key),否则删除这个key,更底层的key将被重新激活 // !!!!!! 待完善 // For this user key: // (1) there is no data in higher levels // (2) data in lower levels will have larger sequence numbers // (3) data in layers that are being compacted here and have // smaller sequence numbers will be dropped in the next // few iterations of this loop (by rule (A) above). // Therefore this deletion marker is obsolete and can be dropped. drop = true; }
if (last_sequence_for_key <= compact->smallest_snapshot) { // 前一个key的序列号都小了,本key肯定更小,直接抛弃 // Hidden by an newer entry for same user key drop = true; // (A) }
这个if条件不满足。
last_sequence_for_key 为id=3的key的序列号。
第二次循环:
由于id=2和id=3的key相同,所以直接进入:
1 2 3 4
if (last_sequence_for_key <= compact->smallest_snapshot) { // 前一个key的序列号都小了,本key肯定更小,直接抛弃 // Hidden by an newer entry for same user key drop = true; // (A) }
if (last_sequence_for_key <= compact->smallest_snapshot) { // 前一个key的序列号都小了,本key肯定更小,直接抛弃 // Hidden by an newer entry for same user key drop = true; // (A) }
此时满足,丢弃id=1的key。
ok,到这里,相信你应该可以看到前两个判断了:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
bool drop = false; if (!ParseInternalKey(key, &ikey)) { // Do not hide error keys current_user_key.clear(); has_current_user_key = false; last_sequence_for_key = kMaxSequenceNumber; } else { // 正常情况下走这里 if (!has_current_user_key || user_comparator()->Compare(ikey.user_key, Slice(current_user_key)) != 0) { // 某个user_key第一次出现 // First occurrence of this user key current_user_key.assign(ikey.user_key.data(), ikey.user_key.size()); has_current_user_key = true; // 第一次出现的user_key不允许删除 last_sequence_for_key = kMaxSequenceNumber; }
那还剩下一个判断:
1 2 3 4 5 6 7 8 9 10 11 12 13
elseif (ikey.type == kTypeDeletion && // 前一个key还在snaphost内,本key虽然是离snapshot最近的key,但是本key是删除节点 ikey.sequence <= compact->smallest_snapshot && compact->compaction->IsBaseLevelForKey(ikey.user_key)) { // 在是删除节点的同时,还必须保证本key一定是"最底层"的key(也就是更底层没有该key),否则删除这个key,更底层的key将被重新激活 // !!!!!! 待完善 // For this user key: // (1) there is no data in higher levels // (2) data in lower levels will have larger sequence numbers // (3) data in layers that are being compacted here and have // smaller sequence numbers will be dropped in the next // few iterations of this loop (by rule (A) above). // Therefore this deletion marker is obsolete and can be dropped. drop = true; }
if (!drop) { // Open output file if necessary if (compact->builder == nullptr) { // builder为空,则打开 status = OpenCompactionOutputFile(compact); if (!status.ok()) { break; } } if (compact->builder->NumEntries() == 0) { compact->current_output()->smallest.DecodeFrom(key); } compact->current_output()->largest.DecodeFrom(key); compact->builder->Add(key, input->value());
// Close output file if it is big enough if (compact->builder->FileSize() >= compact->compaction->MaxOutputFileSize()) { status = FinishCompactionOutputFile(compact, input); if (!status.ok()) { break; } } }
// Make the output file std::string fname = TableFileName(dbname_, file_number); Status s = env_->NewWritableFile(fname, &compact->outfile); if (s.ok()) { compact->builder = newTableBuilder(options_, compact->outfile); } return s; }
这里有两个点要注意:
pending_outputs_, 我们来看的定义:
1 2 3
// Set of table files to protect from deletion because they are // part of ongoing compactions. std::set<uint64_t> pending_outputs_ GUARDED_BY(mutex_);
if (s.ok()) { // Commit to the new state imm_->Unref(); imm_ = nullptr; has_imm_.store(false, std::memory_order_release); // 这里会删除 RemoveObsoleteFiles(); } else { RecordBackgroundError(s); }
RemoveObsoleteFiles中使用到了pending_outputs_,因为在合并过程中,刚生成的sstable还不是“live”的,通过pending_outputs_将它们当成 live 的就不会被删除了。
将需要保存的kv,放在compact->outputs中。
1 2
// 加入到outputs compact->outputs.push_back(out);
第二步,记录最小key和最大key,同时并将要保存的kv加入到builder中。
1 2 3 4 5
if (compact->builder->NumEntries() == 0) { compact->current_output()->smallest.DecodeFrom(key); } compact->current_output()->largest.DecodeFrom(key); compact->builder->Add(key, input->value());
第三步,如果当前table已经过大,则输出:
1 2 3 4 5 6 7 8
// Close output file if it is big enough if (compact->builder->FileSize() >= compact->compaction->MaxOutputFileSize()) { status = FinishCompactionOutputFile(compact, input); if (!status.ok()) { break; } }
// Check for iterator errors Status s = input->status(); constuint64_t current_entries = compact->builder->NumEntries(); if (s.ok()) {/ // 构建sstable s = compact->builder->Finish(); } else { compact->builder->Abandon(); } // 统计sstable的大小 constuint64_t current_bytes = compact->builder->FileSize(); compact->current_output()->file_size = current_bytes; compact->total_bytes += current_bytes; delete compact->builder; compact->builder = nullptr;
// Finish and check for file errors if (s.ok()) { // 写入sstable s = compact->outfile->Sync(); } if (s.ok()) { s = compact->outfile->Close(); } delete compact->outfile; compact->outfile = nullptr;
if (s.ok() && current_entries > 0) { // 验证table是否有效 // Verify that the table is usable Iterator* iter = table_cache_->NewIterator(ReadOptions(), output_number, current_bytes); s = iter->status(); delete iter; if (s.ok()) { Log(options_.info_log, "Generated table #%llu@%d: %lld keys, %lld bytes", (unsignedlonglong)output_number, compact->compaction->level(), (unsignedlonglong)current_entries, (unsignedlonglong)current_bytes); } } return s; }