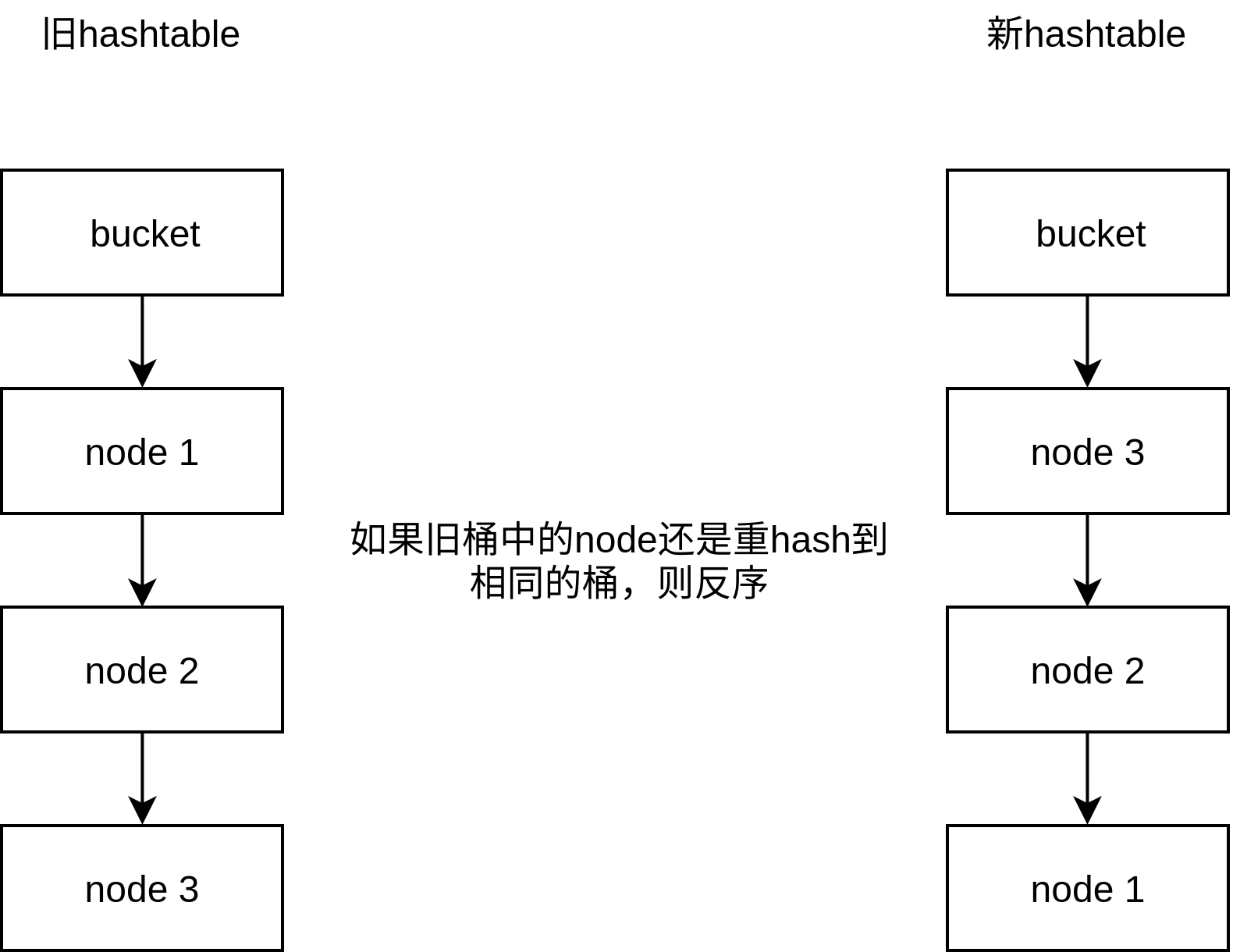
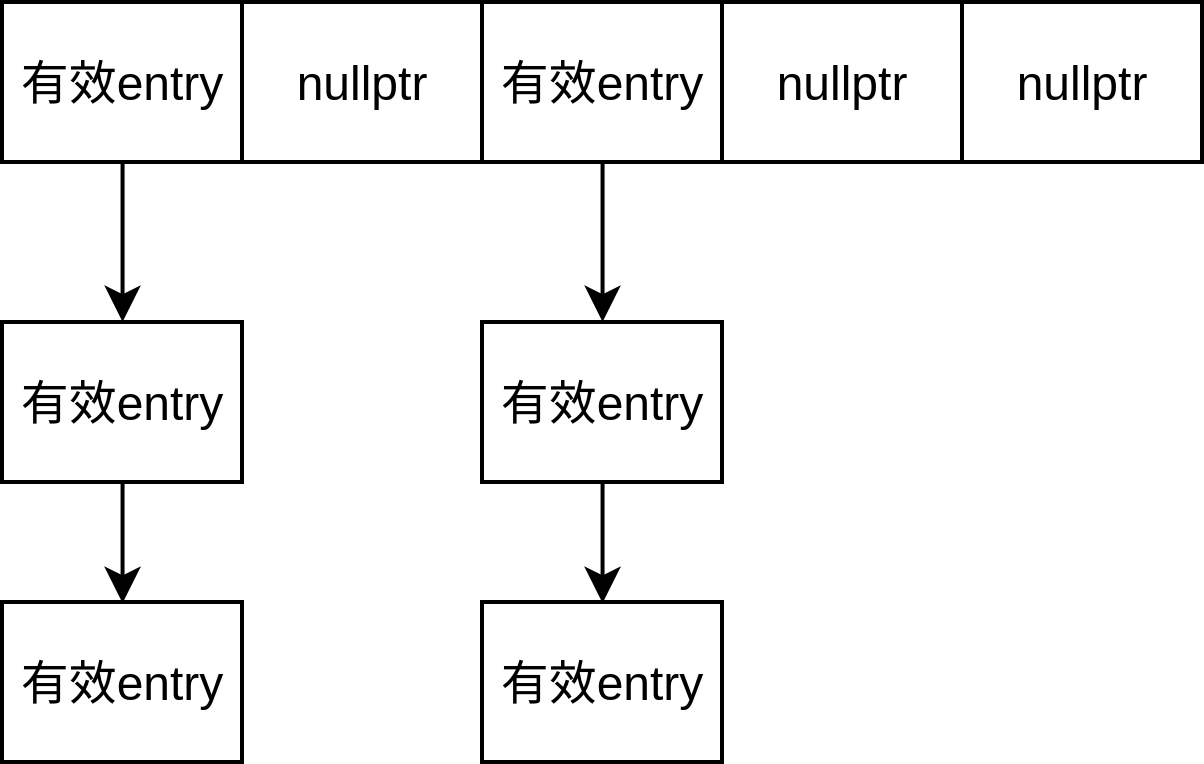
private: // The table consists of an array of buckets where each bucket is // a linked list of cache entries that hash into the bucket. uint32_t length_; // buckets个数 uint32_t elems_; // 当前插入的elem个数 LRUHandle** list_; // 二级指针,每个一级指针指向一个桶
// Return a pointer to slot that points to a cache entry that // matches key/hash. If there is no such cache entry, return a // pointer to the trailing slot in the corresponding linked list. LRUHandle** FindPointer(const Slice& key, uint32_t hash){ LRUHandle** ptr = &list_[hash & (length_ - 1)]; // 二级指针 while (*ptr != nullptr && ((*ptr)->hash != hash || key != (*ptr)->key())) { ptr = &(*ptr)->next_hash; } return ptr; }
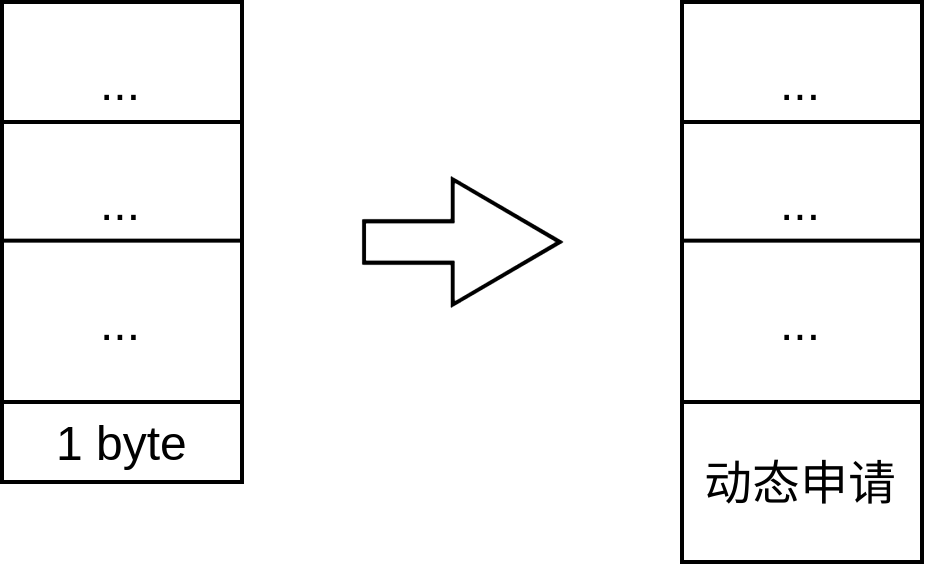
structLRUHandle { void* value; void (*deleter)(const Slice&, void* value); LRUHandle* next_hash; LRUHandle* next; // 双链表的next LRUHandle* prev; // 双链表的prev size_t charge; // TODO(opt): Only allow uint32_t? size_t key_length; bool in_cache; // Whether entry is in the cache. uint32_t refs; // References, including cache reference, if present. 引用计数 uint32_t hash; // Hash of key(); used for fast sharding and comparisons char key_data[1]; // Beginning of key, !! 占位符,这里放在结构体的最后且只有一个字节是有目的的,后面说到
Slice key()const{ // next_ is only equal to this if the LRU handle is the list head of an // empty list. List heads never have meaningful keys. assert(next != this);
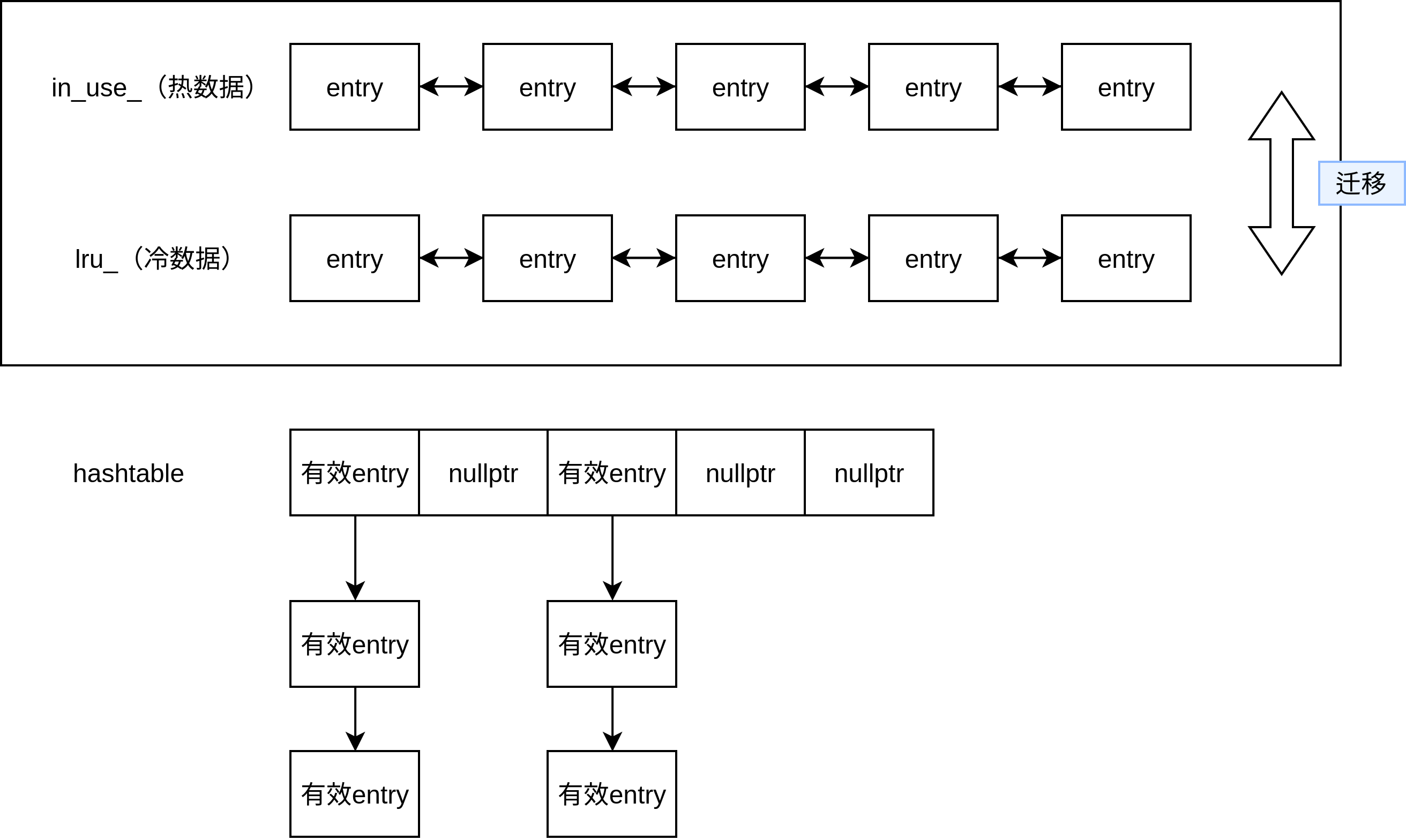
// Dummy head of LRU list. // lru.prev is newest entry, lru.next is oldest entry. // Entries have refs==1 and in_cache==true. LRUHandle lru_ GUARDED_BY(mutex_); // 冷数据
// Dummy head of in-use list. // Entries are in use by clients, and have refs >= 2 and in_cache==true. LRUHandle in_use_ GUARDED_BY(mutex_); // 热数据
HandleTable table_ GUARDED_BY(mutex_); // 之前讲过
注意在lru_链表中, lru.prev代表最新entry,lru.next代表最旧entry。
一个cache entry在上述两条链中的其中一个,通过 Ref() and Unref()调用,一个cache entry在两条链表之间move。
if (capacity_ > 0) { e->refs++; // for the cache's reference. e->in_cache = true; LRU_Append(&in_use_, e); usage_ += charge; FinishErase(table_.Insert(e)); } else { // don't cache. (capacity_==0 is supported and turns off caching.) // next is read by key() in an assert, so it must be initialized e->next = nullptr; } // !!!超过容量,需要剔除旧cache lru_.next存放的是最旧的cache entry while (usage_ > capacity_ && lru_.next != &lru_) { // 移除旧cache entry,直到当前usage 小于等于 capacity。 或者最旧的entry已经是lru_ LRUHandle* old = lru_.next; assert(old->refs == 1); // 从hashtable中移除,从cache中删除。 bool erased = FinishErase(table_.Remove(old->key(), old->hash)); if (!erased) { // to avoid unused variable when compiled NDEBUG assert(erased); } }
// If e != nullptr, finish removing *e from the cache; it has already been // removed from the hash table. Return whether e != nullptr. boolLRUCache::FinishErase(LRUHandle* e){ if (e != nullptr) { assert(e->in_cache); LRU_Remove(e); e->in_cache = false; usage_ -= e->charge; Unref(e); } return e != nullptr; }
LRU evict:
1 2 3 4 5 6 7 8 9 10
// !!!超过容量,需要剔除旧cache lru_.next存放的是最旧的cache entry while (usage_ > capacity_ && lru_.next != &lru_) { // 移除旧cache entry,直到当前usage 小于等于 capacity。 或者最旧的entry已经是lru_头,即cache为空 LRUHandle* old = lru_.next; assert(old->refs == 1); // 从hashtable中移除,从cache中删除。 bool erased = FinishErase(table_.Remove(old->key(), old->hash)); if (!erased) { // to avoid unused variable when compiled NDEBUG assert(erased); } }
LRU是如何体现的?
回到插入一个entry到lru_中:
1 2 3 4 5 6 7 8 9
LRU_Append(&lru_, e);
voidLRUCache::LRU_Append(LRUHandle* list, LRUHandle* e){ // Make "e" newest entry by inserting just before *list e->next = list; e->prev = list->prev; e->prev->next = e; e->next->prev = e; }
// Number of open files that can be used by the DB. You may need to // increase this if your database has a large working set (budget // one open file per 2MB of working set). int max_open_files = 1000;
constint kNumNonTableCacheFiles = 10;
staticintTableCacheSize(const Options& sanitized_options){ // Reserve ten files or so for other uses and give the rest to TableCache. return sanitized_options.max_open_files - kNumNonTableCacheFiles; }
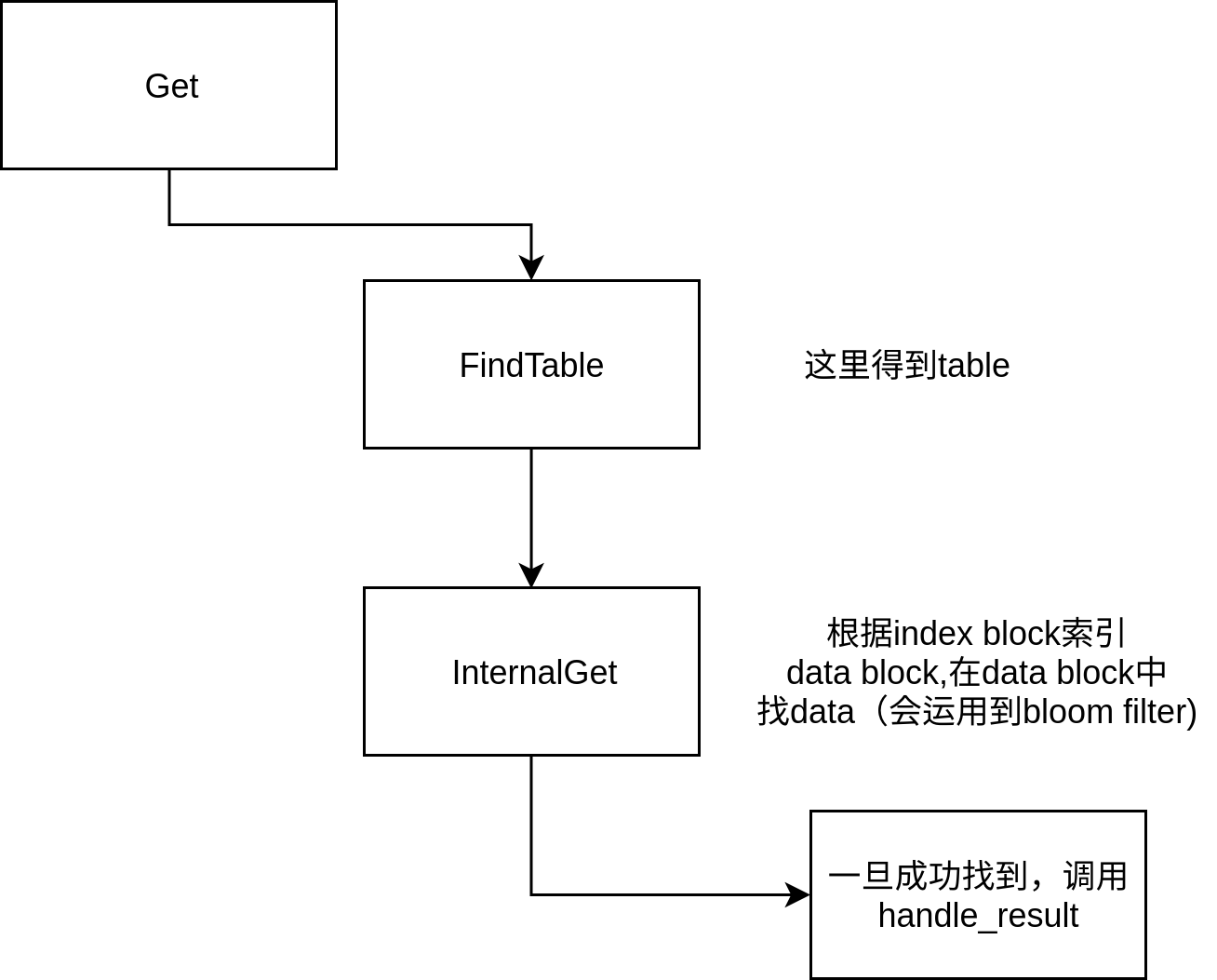
// Return an iterator for the specified file number (the corresponding // file length must be exactly "file_size" bytes). If "tableptr" is // non-null, also sets "*tableptr" to point to the Table object // underlying the returned iterator, or to nullptr if no Table object // underlies the returned iterator. The returned "*tableptr" object is owned // by the cache and should not be deleted, and is valid for as long as the // returned iterator is live. Iterator* NewIterator(const ReadOptions& options, uint64_t file_number, uint64_t file_size, Table** tableptr = nullptr);
// If a seek to internal key "k" in specified file finds an entry, // call (*handle_result)(arg, found_key, found_value). Status Get(const ReadOptions& options, uint64_t file_number, uint64_t file_size, const Slice& k, void* arg, void (*handle_result)(void*, const Slice&, const Slice&));
// Evict any entry for the specified file number voidEvict(uint64_t file_number);
private: Status FindTable(uint64_t file_number, uint64_t file_size, Cache::Handle**);
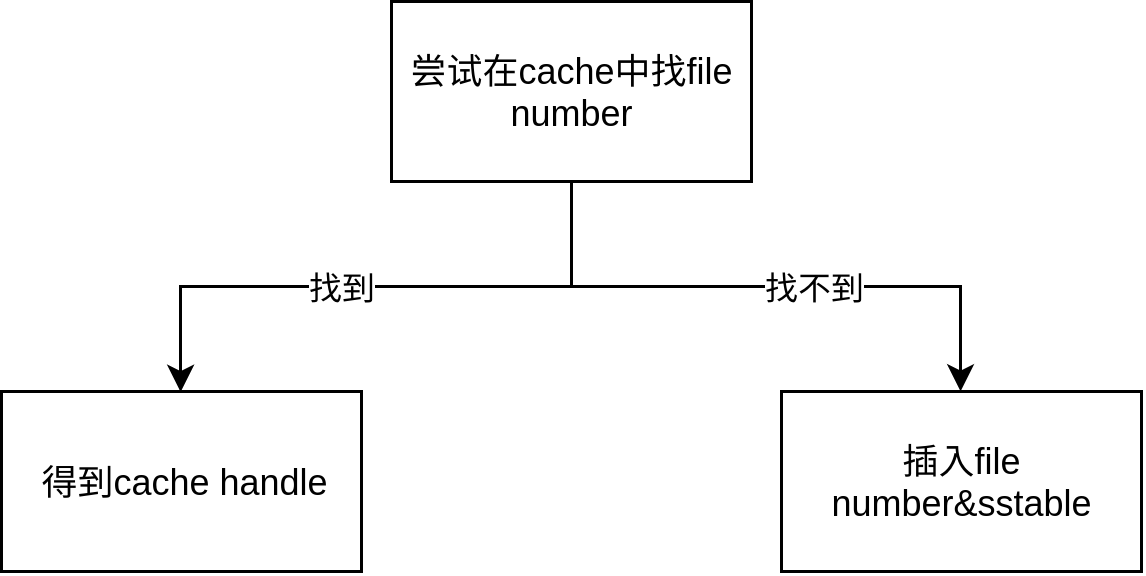
Status TableCache::FindTable(uint64_t file_number, uint64_t file_size, Cache::Handle** handle){ Status s; char buf[sizeof(file_number)]; EncodeFixed64(buf, file_number); Slice key(buf, sizeof(buf)); // 在cache寻找key对应的handle *handle = cache_->Lookup(key); if (*handle == nullptr) { // 找不到 std::string fname = TableFileName(dbname_, file_number); RandomAccessFile* file = nullptr; Table* table = nullptr; // 根据fname打开file s = env_->NewRandomAccessFile(fname, &file); if (!s.ok()) { std::string old_fname = SSTTableFileName(dbname_, file_number); if (env_->NewRandomAccessFile(old_fname, &file).ok()) { s = Status::OK(); } } if (s.ok()) { // 根据file打开table s = Table::Open(options_, file, file_size, &table); }
if (!s.ok()) { assert(table == nullptr); delete file; // We do not cache error results so that if the error is transient, // or somebody repairs the file, we recover automatically. } else { // 插入到cache中 TableAndFile* tf = new TableAndFile; tf->file = file; tf->table = table; *handle = cache_->Insert(key, tf, 1, &DeleteEntry); } } return s; }
// Convert an index iterator value (i.e., an encoded BlockHandle) // into an iterator over the contents of the corresponding block. Iterator* Table::BlockReader(void* arg, const ReadOptions& options, const Slice& index_value){ Table* table = reinterpret_cast<Table*>(arg); // 获取 block_cache Cache* block_cache = table->rep_->options.block_cache; Block* block = nullptr; Cache::Handle* cache_handle = nullptr;
BlockHandle handle; Slice input = index_value; Status s = handle.DecodeFrom(&input); // We intentionally allow extra stuff in index_value so that we // can add more features in the future.
if (s.ok()) { BlockContents contents; if (block_cache != nullptr) { char cache_key_buffer[16]; EncodeFixed64(cache_key_buffer, table->rep_->cache_id); EncodeFixed64(cache_key_buffer + 8, handle.offset()); Slice key(cache_key_buffer, sizeof(cache_key_buffer)); cache_handle = block_cache->Lookup(key); if (cache_handle != nullptr) { block = reinterpret_cast<Block*>(block_cache->Value(cache_handle)); } else { s = ReadBlock(table->rep_->file, options, handle, &contents); if (s.ok()) { block = newBlock(contents); if (contents.cachable && options.fill_cache) { cache_handle = block_cache->Insert(key, block, block->size(), &DeleteCachedBlock); } } } } else { s = ReadBlock(table->rep_->file, options, handle, &contents); if (s.ok()) { block = newBlock(contents); } } }
// 读取完整的data block // Read the block contents as well as the type/crc footer. // See table_builder.cc for the code that built this structure. size_t n = static_cast<size_t>(handle.size()); char* buf = newchar[n + kBlockTrailerSize]; Slice contents; Status s = file->Read(handle.offset(), n + kBlockTrailerSize, &contents, buf); if (!s.ok()) { delete[] buf; return s; } if (contents.size() != n + kBlockTrailerSize) { delete[] buf; return Status::Corruption("truncated block read"); }
// crc校验 // Check the crc of the type and the block contents constchar* data = contents.data(); // Pointer to where Read put the data if (options.verify_checksums) { constuint32_t crc = crc32c::Unmask(DecodeFixed32(data + n + 1)); constuint32_t actual = crc32c::Value(data, n + 1); if (actual != crc) { delete[] buf; s = Status::Corruption("block checksum mismatch"); return s; } }
// 查看是否需要解压,如果需要解压,则解压数据 switch (data[n]) { case kNoCompression: if (data != buf) { // File implementation gave us pointer to some other data. // Use it directly under the assumption that it will be live // while the file is open. delete[] buf; result->data = Slice(data, n); result->heap_allocated = false; result->cachable = false; // Do not double-cache } else { result->data = Slice(buf, n); result->heap_allocated = true; result->cachable = true; }