0. 前言·
本实验为MIT6.s8081的第八个实验,主题和 锁 相关。实验任务有两个:
- 增加内核内存分配器的并发性
- 增加文件系统buffer cache的并发性
本实验是第二个难度较大的实验。很值得一做。
1. 实现·
1. Memory allocator·
原文要求:
The program user/kalloctest stresses xv6’s memory allocator: three processes grow and shrink their address spaces, resulting in many calls to
kallocandkfree.kallocandkfreeobtainkmem.lock. kalloctest prints (as “#fetch-and-add”) the number of loop iterations inacquiredue to attempts to acquire a lock that another core already holds, for thekmemlock and a few other locks. The number of loop iterations inacquireis a rough measure of lock contention. The output ofkalloctestlooks similar to this before you complete the lab:
2
3
4
5
6
7
8
9
10
11
12
13
14
start test1
test1 results:
--- lock kmem/bcache stats
lock: kmem: #fetch-and-add 83375 #acquire() 433015
lock: bcache: #fetch-and-add 0 #acquire() 1260
--- top 5 contended locks:
lock: kmem: #fetch-and-add 83375 #acquire() 433015
lock: proc: #fetch-and-add 23737 #acquire() 130718
lock: virtio_disk: #fetch-and-add 11159 #acquire() 114
lock: proc: #fetch-and-add 5937 #acquire() 130786
lock: proc: #fetch-and-add 4080 #acquire() 130786
tot= 83375
test1 FAIL
acquiremaintains, for each lock, the count of calls toacquirefor that lock, and the number of times the loop inacquiretried but failed to set the lock. kalloctest calls a system call that causes the kernel to print those counts for the kmem and bcache locks (which are the focus of this lab) and for the 5 most contended locks. If there is lock contention the number ofacquireloop iterations will be large. The system call returns the sum of the number of loop iterations for the kmem and bcache locks.For this lab, you must use a dedicated unloaded machine with multiple cores. If you use a machine that is doing other things, the counts that kalloctest prints will be nonsense. You can use a dedicated Athena workstation, or your own laptop, but don’t use a dialup machine.
The root cause of lock contention in kalloctest is that
kalloc()has a single free list, protected by a single lock. To remove lock contention, you will have to redesign the memory allocator to avoid a single lock and list. The basic idea is to maintain a free list per CPU, each list with its own lock. Allocations and frees on different CPUs can run in parallel, because each CPU will operate on a different list. The main challenge will be to deal with the case in which one CPU’s free list is empty, but another CPU’s list has free memory; in that case, the one CPU must “steal” part of the other CPU’s free list. Stealing may introduce lock contention, but that will hopefully be infrequent.Your job is to implement per-CPU freelists, and stealing when a CPU’s free list is empty. You must give all of your locks names that start with “kmem”. That is, you should call
initlockfor each of your locks, and pass a name that starts with “kmem”. Run kalloctest to see if your implementation has reduced lock contention. To check that it can still allocate all of memory, runusertests sbrkmuch. Your output will look similar to that shown below, with much-reduced contention in total on kmem locks, although the specific numbers will differ. Make sure all tests inusertestspass.make gradeshould say that the kalloctests pass.
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
start test1
test1 results:
--- lock kmem/bcache stats
lock: kmem:
lock: kmem:
lock: kmem:
lock: bcache:
--- top 5 contended locks:
lock: proc:
lock: virtio_disk:
lock: proc:
lock: proc:
lock: proc:
tot= 0
test1 OK
start test2
total free number of pages: 32499 (out of 32768)
.....
test2 OK
$ usertests sbrkmuch
usertests starting
test sbrkmuch: OK
ALL TESTS PASSED
$ usertests
...
ALL TESTS PASSED
$
1. 思路·
现在来说说实现思路。
在xv6的原版实现中,内核内存分配器为一个freelist, 所有CPU共享该freelist:
1 | struct { |
为了线程安全,对于kmem的访问采用了自旋锁来予以保护。但是这样的设计使得同一时刻,只有一个CPU,或者说一个进程能够执行内存分配,降低了分配器的并发性。本task的目的就是想办法提高分配器并发性。
那如何才能提高并发性?一个简单的办法是将freelist分区,每个CPU都有自己专属的freelist,这样就天然避免了data race。不过如果某个CPU上内存分配速率过快,会造成该CPU无空闲内存能够分配,另一些CPU上还有很多内存可分配,对于这样情况,需要实现某种 偷取策略,从其他CPU偷一点内存过来,在偷取的过程中仍存在 data race 的问题。
有了这样的思想,来思考下要实现该方法需要考虑些什么问题:
-
每个CPU的初始内存量该分配为多少?
按照CPU个数均分即可。
-
如何向其他CPU偷取内存?一次偷取多少?
个人采用轮转的方式偷取,一次偷取的内存量为被偷取CPU内存的一半。
2. 实现·
ok,来看实现吧。
首先,将内存划分为NCPU个:
1 | struct |
并完成相应初始化:
1 | /** |
假设CPU一共有4个,物理页编号为 page(i), 则将 page(i)分配给page(i) % 4的 kmem freelist。
接着看看如何释放内存:
1 | // Free the page of physical memory pointed at by v, |
核心代码为:
1 | acquire(&kmem[cid].lock); |
即将需要释放的内存归还到 kmem[cid].freelist中。
另一个要说的是: push_off 和 pop_off代码,这两个代码可以理解为关闭/开启中断。根据官网hint来看:
- The function
cpuidreturns the current core number, but it’s only safe to call it and use its result when interrupts are turned off. You should usepush_off()andpop_off()to turn interrupts off and on.
所以添加了这个两行,但我个人认为是不需要添加这两行的,push_off和 pop_off是为了避免在获取当前进程所处cpuid后,使用cpuid之前,产生了时钟中断,当前进程切换到另一个CPU上运行,那么之前获取的cpuid将不能代表当前进程所处的CPU。然而我们的目的是将内存归还给系统,这里的不变量(invariant)为 所有物理页不会丢失,所以个人认为只要能归还到系统,还到哪个CPU freelist上都无所谓。
最后来看看 内存分配:
1 | // Allocate one 4096-byte page of physical memory. |
找到当前进程cpuid,尝试申请内存,如果当前cpuid所持有的的freelist没有空闲内存,则向其它cpu偷取 steal_mem。 steam_mem返回-1,说明其他cpu也没有内存可用,此时返回0. 如果偷取成功,则重新尝试申请 (goto alloc)。
下面是 steal_mem的代码:
1 | /** |
这里的代码工作为,向后逐个查询其它cpu,如果其他cpu freelist 有空闲内存,则偷取它的一半内存。
有一个注意点:在 steal_mem的第一行中,执行了 release(&kmem[cur_cpuid].lock);即释放了当前cpuid的lock,为什么需要释放?查看下面这张图:

如果同时存在两个cpu在向其它cpu偷取内存,那么可能死锁问题。所以,第一行做了释放操作。
至此,完成本task。
2. Buffer cache·
相比内存分配器,buffer cache会更难一些。
先看原文要求:
If multiple processes use the file system intensively, they will likely contend for
bcache.lock, which protects the disk block cache in kernel/bio.c.bcachetestcreates several processes that repeatedly read different files in order to generate contention onbcache.lock; its output looks like this (before you complete this lab):
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
start test0
test0 results:
--- lock kmem/bcache stats
lock: kmem: #fetch-and-add 0 #acquire() 33035
lock: bcache: #fetch-and-add 16142 #acquire() 65978
--- top 5 contended locks:
lock: virtio_disk: #fetch-and-add 162870 #acquire() 1188
lock: proc: #fetch-and-add 51936 #acquire() 73732
lock: bcache: #fetch-and-add 16142 #acquire() 65978
lock: uart: #fetch-and-add 7505 #acquire() 117
lock: proc: #fetch-and-add 6937 #acquire() 73420
tot= 16142
test0: FAIL
start test1
test1 OKYou will likely see different output, but the number of
acquireloop iterations for thebcachelock will be high. If you look at the code inkernel/bio.c, you’ll see thatbcache.lockprotects the list of cached block buffers, the reference count (b->refcnt) in each block buffer, and the identities of the cached blocks (b->devandb->blockno).Modify the block cache so that the number of
acquireloop iterations for all locks in the bcache is close to zero when runningbcachetest. Ideally the sum of the counts for all locks involved in the block cache should be zero, but it’s OK if the sum is less than 500. Modifybgetandbrelseso that concurrent lookups and releases for different blocks that are in the bcache are unlikely to conflict on locks (e.g., don’t all have to wait forbcache.lock). You must maintain the invariant that at most one copy of each block is cached. When you are done, your output should be similar to that shown below (though not identical). Make sure usertests still passes.make gradeshould pass all tests when you are done.
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
start test0
test0 results:
--- lock kmem/bcache stats
lock: kmem: #fetch-and-add 0 #acquire() 32954
lock: kmem: #fetch-and-add 0 #acquire() 75
lock: kmem: #fetch-and-add 0 #acquire() 73
lock: bcache: #fetch-and-add 0 #acquire() 85
lock: bcache.bucket: #fetch-and-add 0 #acquire() 4159
lock: bcache.bucket: #fetch-and-add 0 #acquire() 2118
lock: bcache.bucket: #fetch-and-add 0 #acquire() 4274
lock: bcache.bucket: #fetch-and-add 0 #acquire() 4326
lock: bcache.bucket: #fetch-and-add 0 #acquire() 6334
lock: bcache.bucket: #fetch-and-add 0 #acquire() 6321
lock: bcache.bucket: #fetch-and-add 0 #acquire() 6704
lock: bcache.bucket: #fetch-and-add 0 #acquire() 6696
lock: bcache.bucket: #fetch-and-add 0 #acquire() 7757
lock: bcache.bucket: #fetch-and-add 0 #acquire() 6199
lock: bcache.bucket: #fetch-and-add 0 #acquire() 4136
lock: bcache.bucket: #fetch-and-add 0 #acquire() 4136
lock: bcache.bucket: #fetch-and-add 0 #acquire() 2123
--- top 5 contended locks:
lock: virtio_disk: #fetch-and-add 158235 #acquire() 1193
lock: proc: #fetch-and-add 117563 #acquire() 3708493
lock: proc: #fetch-and-add 65921 #acquire() 3710254
lock: proc: #fetch-and-add 44090 #acquire() 3708607
lock: proc: #fetch-and-add 43252 #acquire() 3708521
tot= 128
test0: OK
start test1
test1 OK
$ usertests
...
ALL TESTS PASSED
$Please give all of your locks names that start with “bcache”. That is, you should call
initlockfor each of your locks, and pass a name that starts with “bcache”.Reducing contention in the block cache is more tricky than for kalloc, because bcache buffers are truly shared among processes (and thus CPUs). For kalloc, one could eliminate most contention by giving each CPU its own allocator; that won’t work for the block cache. We suggest you look up block numbers in the cache with a hash table that has a lock per hash bucket.
There are some circumstances in which it’s OK if your solution has lock conflicts:
- When two processes concurrently use the same block number.
bcachetesttest0doesn’t ever do this.- When two processes concurrently miss in the cache, and need to find an unused block to replace.
bcachetesttest0doesn’t ever do this.- When two processes concurrently use blocks that conflict in whatever scheme you use to partition the blocks and locks; for example, if two processes use blocks whose block numbers hash to the same slot in a hash table.
bcachetesttest0might do this, depending on your design, but you should try to adjust your scheme’s details to avoid conflicts (e.g., change the size of your hash table).
bcachetest’stest1uses more distinct blocks than there are buffers, and exercises lots of file system code paths.
1. 思路·
在xv6原本的buffer cache实现中,buffer cache在逻辑层面为一个双向链表,物理层面为一个数组,替换策略采用链表式的lru算法。并发方面,仅采用了一个 spinlock 的全局lock,并发度较低。
那么该如何提高并发?
首先想一下是否可以模仿内存分配器task中,将buffer cache按照CPU个数分为多个双向链表? 很遗憾,答案是不行的,因为buffer cache是全processes共享,且一个disk block最多只能在一个buffer cache entry中。如果采用这种策略,假设一个disk block在cpu0的buffer cache中,那么其他cpu上的进程在访问该disk block时,必须访问cpu0的buffer cache,所以按照CPU个数划分并不能起到隔离各buffer cache的作用(不像内存分配器taks中,按照CPU划分后,各个freelist相互隔离,只在steal_mem中会有相互访问的情况)。
那么该如何设计?
对于这种情况,我们要做的是尽可能的降低锁的粒度,原版是对整个buffer cache双链表采用一个大锁,只要能降低该锁粒度,也就能提升并发性。具体而言,采用了链式冲突方案式的hash table来解决。如下图:

如上为一个hash table,采用挂链的方式解决hash冲突的问题,每一个chan上的entry都是一个buffer cache entry。每个hash bucket都有一个lock,这样在访问buffer cache时,首先定位到要访问的buffer cache entry所处的hash table bucket,对该bucket加锁即可。所以锁粒度降到了bucket级别。
如上是大体思路,具体实现需要思考如下问题:
-
每个buffer cache entry属于哪个hash table bucket?
通过要访问的
blockno来计算,即bucketid = blockno % BUCKET_NUM,BUCKET_NUM为hash table的有效bucket个数,为什么说是有效bucket个数,看问题2. -
如何初始化hash table,即最开始的buffer cache entry该如何挂接到hash table上?
最初的buffer cache entry是没有
blockno信息的,如何将最初的 buffer cache entry挂接到hash table上?有两种做法:-
懒挂接,等到上层发起
bread请求时,找到还没有blockno信息的buffer cache entry,挂接到hash table上。 这种做法比较直观,但实现起来容易出现bug。(需要考虑 buffer cache entry的底层分配方式,xv6采用数组的方式分配,所以还要单独考虑对该数组的访问,这样涉及不仅对逻辑层面的hash table访问,还要对物理层面的array访问) -
初始化时直接挂接,由于初始化的时候每个buffer cache entry都没有
blockno信息,不能随意挂接,我采用的trick是,为hash table多分配的一个 bucket, 这个bucket只在初始化的时候使用,用于挂接还没有blockno信息的buffer cache entry.如下图:![hash table-多余一个bucket-2]()
-
-
没有双向链表,如何采用lru?这里改用了 time-stamp 的lru方式。每次释放 buffer cache entry时,更新其当前的 time (或者称为tick)字段为系统的时钟,之后按照tick大小来采用lru算法。 缺点是,每次都需要遍历所有buffer cache entry,时间更长,不过xv6中,buffer cache entry的个数仅为30个,所以速度还是很快的。
-
bucket内的一个buffer cache entry可能需要移动到另一个bucket中,这个移动必须是原子的。**为什么会出现移动?**因为在lru剔除的时候,可能找到的被剔除的buffer cache entry在bucket0中,但是当前请求的blockno定位到了bucket1中,此时需要将bucket0中的buffer cache entry移动到bucket1中。

好,知道这些后,流程基本就理清了。不过实现起来还需要注意锁的问题,就我个人实现的体验来看,死锁问题很好解决,反倒是一些 invariant 容易忽略。如:
- 任何时刻,一个disk block最多只能出现在一个 buffer cache中
- 移动的原子性
- buffer cache entry的引用计数更新原子性
- …
2. 实现·
首先改造 buf, 不再需要双链表,删除一个指针,增加 tick 用于后续lru实现:
1 | struct buf { |
再来改造 bcache 结构,增加hash table:
1 | struct |
这里对每个bucket都配套了一个lock,同时还有一个全局buckets_lock, 后续会提到为什么需要设计这个全局buckets_lock。
修改 binit初始化函数:
1 | void |
这里将所有buffer cache entry插入到了 hash table的最后一个bucket。
现在来明确一个规则,对于 buf.refcnt 和 tick 的更新或访问,一定需要加上buf所在的bucket lock. 有了这条规则,修改 brelse函数:
1 |
|
再来修改两个简单函数 bpin和 bunpni:
1 |
|
最复杂的当属 bget函数,几乎全部重构:
1 | // Look through buffer cache for block on device dev. |
ok,我们来分段查看这个函数:
1 | int nbkt_id = blockno % BUCKET_NUM; |
首先查看blockno对应的bucket中,是否存在指定要查询的buffer cache entry, 如果有,增加refcnt并返回。
否则:
1 | // Not cached. |
根据lru找到一个空闲的buffer cache entry和对应的bucket id(free_bkt_id)。 注意 find_free_buf返回的buf是不带锁的,所以获取到该buf entry后,需要再加一次锁,并检查 b->refcnt != 0 ,为什么需要做再次检查?因为 find_free_buf返回后, 该buf不带锁,这个过程可能其他CPU也用到了这个buffer entry,导致 对一个free buffer cache entry来说,其refcnt必须等于0 这个invariant失效,所以必须再次做检查,如果检查失败,则重试。
来看看find_free_buf的实现:
1 | // find free buf using tick-lru |
这里的实现很简单,遍历全bucket,找到refcnt=0,且具有最小的tick buffer cache entry作为free buf返回即可。
关于retry:
其实可以不要retry,在
find_free_buf时,找到的buf,不要释放锁即可。具体来说,可以采用类似B+树的crab-latching方案。 只有加了一个具有更小tick的buf entry lock后,才可以释放之前buf entry的lock。
回到,bget函数:
1 | // lock current bucket |
free_bkt_id为找到的free buf所在bucket id, nbkt_id为目标blockno所对应的bucket id。所以加了if以避免重复加锁。接着又做了一次检查,这是因为在bget开始的搜索中,在未找到目标buffer cache entry后,会释放nbkt_id的lock, 这时其他进程获取该lock并插入目标buffer cache entry。 如果当前进程不做检查,又插入一个具有相同dev和blockno的buffer cache entry,会造成同一份disk block在buffer cache中有两份缓存。这违背了前面提到的invariant:一个disk block在buffer cache中只有一份。
一个示意图如下:

到这里,持有了三个lock:
- 全局hash table lock
- free buf lock
- 目标lock
可以执行移动操作了:
1 | b->dev = dev; |
如果 free_bkt_id 等于 nbkt_id, 代表当前free buf和目标buf在同一个bucket,不需要移动。只用赋值即可。否则需要移动:
1 | // NOTE: bucket[obkt_id].lock nad bucket[nbkt_id].lock must be held |
这是hash table的常规插入删除操作,不用细说(虽然我最开始连这个都实现错了,主要是忘了删除后,将buf->next置为0)。
最后说一下为什么一个 bucket lock 的全局大锁,以及该锁是否有必要。
该锁只有一个作用,保证同一时刻,只有一个进程在执行buffer cache entry从一个bucket移动到另一个bucket。否则可能会有死锁问题。
如下图:

P1持有红色bucket的锁,尝试获取黄色bucket的锁,以将红色buffer cache entry移动到黄色bucket中。
P2相反,持有黄色bucket锁,尝试获取红色bucket锁,以将黄色buffer cache entry移动到红色bucket中。
这样的场景导致了死锁。
所以加上bucket 大锁,保证不出现这个场景。
但是大锁又再次降低了并发。 在实际开发中,采用 try_lock 和retry策略是个更好的做法,这样移动操作也可以并发执行,进一步提升并发。
至此,完成所有task,测试结果如下:
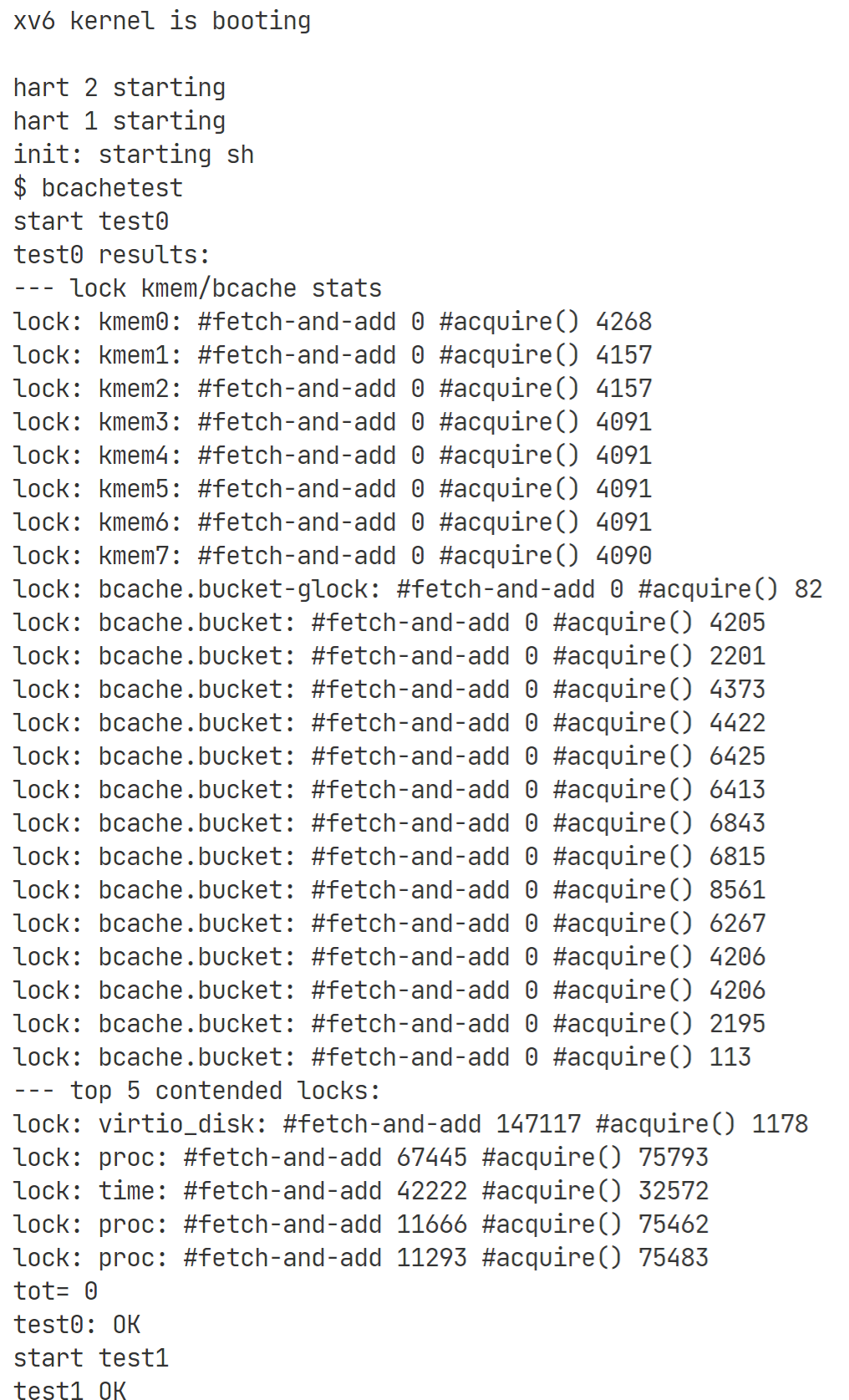
注意,除了bcachetest以外,还需要通过usertests测试
2. 总结·
并发实验果然会难上不少,不过用处也更大,体会到多线程debug的痛苦,增加了调试的经验,多线程编程建议从大锁到小锁,低并发(比如用2个CPU)到高并发量。对于不确定线程安全与否的函数,先加大锁尝试,逐渐减少临界区范围,确定出现问题的临界区,再尝试修改。如果确实无法debug出来,尝试重构也是个好办法。

