// Task Type const ( MapTask WorkerTaskType = 1 << iota ReduceTask WaitTask // special task used when all task have been assigned )
type Task struct { TaskId int TaskType WorkerTaskType PartitionNum int// input file for map should be split into # partitions StartTime int64 FileNames []string TaskState StateType }
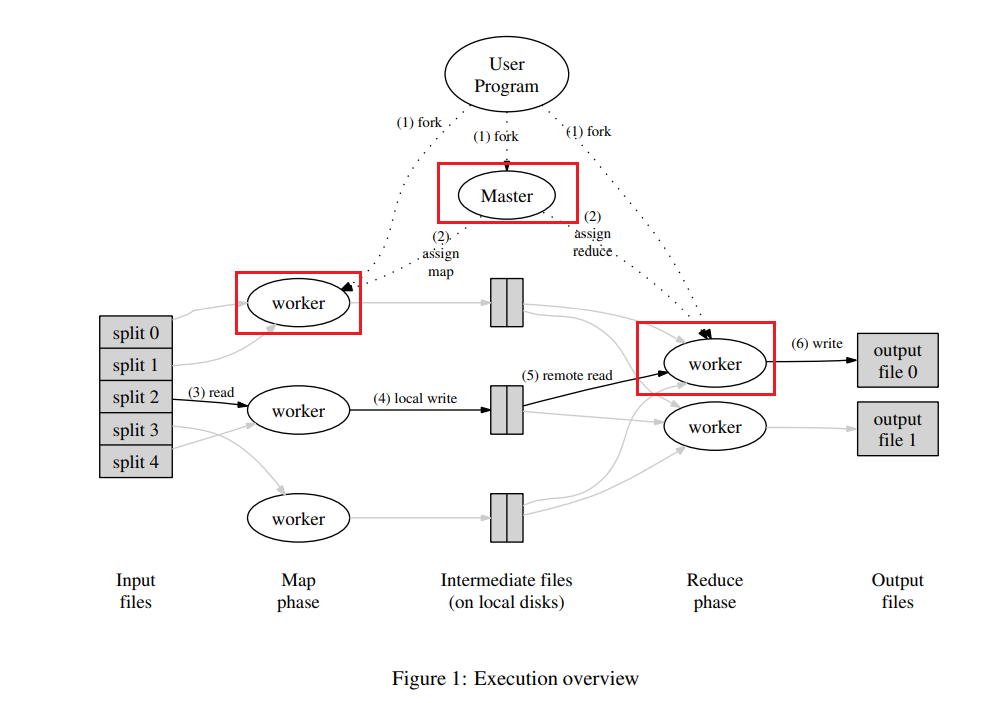
RPC相关:
当worker请求一个task,无需入参,只用master返回一个Task
当worker完成一个task,需要一些入参,这些定义如下
1 2 3 4 5 6 7 8
type MapTaskDoneArg struct { TaskId int IntermediateFileNames []string }
type Master struct { // Your definitions here. mapTasks []Task reduceTasks []Task intermidateFileNames map[int][]string// used for reduce task. key: partition id; value: file names in that partitiion completedMapTaskNum int// should be end with # = len(mapTask). i.e assert(completedMapTaskNum <= len(mapTask)) completedReduceTaskNum int// should be end with # = len(reduceTask). partitionNum int execState ExecStateType mu sync.Mutex }
// Your code here -- RPC handlers for the worker to call. func(m *Master) RequestTask(meaningless *struct{} /* not use */, task *Task) error { m.mu.Lock() defer m.mu.Unlock()
switch m.execState { case MAP_PHASE: *task = m.assignMapTask() case REDUCE_PHASE: *task = m.assignReduceTask() case COMPLETE_ALL: // return error intentionally return fmt.Errorf("all tasks have been completed") } returnnil }
if m.execState != MAP_PHASE { log.Panic("current exec state is not at the map phase, current state is", m.execState) } // check whether the mapper is assumed timeout/die if arg.TaskId >= len(m.mapTasks) || m.mapTasks[arg.TaskId].TaskState != IN_PROGRESS { msg := fmt.Sprintf("task id error or task has wrong task state which should be IN_PROGRESS, task id:%v, task state:%v", arg.TaskId, m.mapTasks[arg.TaskId].TaskState) // log.Panic(msg) log.Println(msg) return fmt.Errorf(msg) }
// Split intermidate FileNames for _, fileName := range arg.IntermediateFileNames { // fileName looks like "map-X-Y", where Y is the partition id if fileName == "" { log.Panic("MapTaskDone: intermediate filename should not be empty") } partitionStr := string(fileName[len(fileName)-1]) // TODO: is there any better way to convert a char to int? partitionId, err := strconv.Atoi(partitionStr) if err != nil { log.Fatalf("convert string %v to int failed", partitionStr) } if m.intermidateFileNames[partitionId] == nil { m.intermidateFileNames[partitionId] = make([]string, 0) } m.intermidateFileNames[partitionId] = append(m.intermidateFileNames[partitionId], fileName) } m.mapTasks[arg.TaskId].TaskState = COMPLETED m.completedMapTaskNum++ if m.completedMapTaskNum == len(m.mapTasks) { // do one more check for debugging for i := 0; i < len(m.mapTasks); i++ { if m.mapTasks[i].TaskState != COMPLETED { log.Panic("completedMapTaskNum is equal to len of mapTasks, but there are some mapTasks still not in the `COMPLETED` state") } } log.Println("all map tasks have been completed") m.execState = REDUCE_PHASE m.createReduceTask() } returnnil }
if m.execState != REDUCE_PHASE { log.Panic("current exec state is not at the reduce phase, current state is", m.execState) } // check whether the reduce is assumed timeout/die taskIdx := -1 for i := 0; i < len(m.reduceTasks); i++ { if m.reduceTasks[i].TaskId == arg.TaskId { if m.reduceTasks[i].TaskState != IN_PROGRESS { msg := fmt.Sprintf("task has wrong task state which should be IN_PROGRESS, task id:%v, task state:%v", arg.TaskId, m.mapTasks[arg.TaskId].TaskState) // log.Panic(msg) log.Println(msg) return fmt.Errorf(msg) } taskIdx = i break } }
m.reduceTasks[taskIdx].TaskState = COMPLETED m.completedReduceTaskNum++ if m.completedReduceTaskNum == len(m.reduceTasks) { // do one more check for debugging for i := 0; i < len(m.reduceTasks); i++ { if m.reduceTasks[i].TaskState != COMPLETED { log.Panic("completedMapTaskNum is equal to len of reduceTasks, but there are some reduceTasks still not in the `COMPLETED` state") } } log.Println("all reduce tasks have been completed") m.execState = COMPLETE_ALL } returnnil
// // create a Master. // main/mrmaster.go calls this function. // nReduce is the number of reduce tasks to use. // funcMakeMaster(files []string, nReduce int) *Master { m := Master{ mapTasks: make([]Task, 0), reduceTasks: make([]Task, 0), intermidateFileNames: make(map[int][]string), completedMapTaskNum: 0, completedReduceTaskNum: 0, partitionNum: nReduce, execState: MAP_PHASE, } // create mapTasks for i, fileName := range files { task := Task{ TaskId: i, TaskType: MapTask, PartitionNum: nReduce, StartTime: -1, FileNames: []string{fileName}, TaskState: IDLE, } m.mapTasks = append(m.mapTasks, task) // maybe I should use pointer instead to save one copy cost? }
// launch timeout checker go m.taskTimeoutChecker()
funcdoMap(mapf func(string, string) []KeyValue, task *Task) { // read each input file, pass it to Map, accumulate the kvpairs Map output. then sort it kvpairs := []KeyValue{} for _, filename := range task.FileNames { file, err := os.Open(filename) if err != nil { log.Fatalf("cannot open %v", filename) } content, err := ioutil.ReadAll(file) if err != nil { log.Fatalf("cannot read %v", filename) } file.Close() kva := mapf(filename, string(content)) kvpairs = append(kvpairs, kva...) } sort.Sort(ByKey(kvpairs))
// split into tmp files, tmpFile format: tmp-X-Y tmpFileNames := splitKVPairs(kvpairs, task) // rename files intermediateFileNames := make([]string, 0) for fileName, fileHandler := range tmpFileNames { fileHandler.Close() // close first newFileName := strings.Replace(fileName, "tmp", "map", -1) os.Rename(fileName, newFileName) intermediateFileNames = append(intermediateFileNames, newFileName) } // notify master we have done this task finishMapTask(task.TaskId, intermediateFileNames) }
funcdoReduce(reducef func(string, []string)string, task *Task) { // read kv pairs from files rawKVs := []KeyValue{} for _, filename := range task.FileNames { file, err := os.Open(filename) if err != nil { log.Fatalf("cannot open %v", filename) } rawKVs = append(rawKVs, loadKVPairs(file)...) file.Close() } sort.Sort(ByKey(rawKVs)) // apply reduce retKVs := applyReduce(reducef, rawKVs)
// wirte ret kv pairs into tmp file to prevent client will read partial contents in the further for this worker crashed tmpFileName := fmt.Sprintf("tmp-out-%d", task.TaskId) file, err := os.Create(tmpFileName) if err != nil { log.Fatalf("cannot create temp file %v", tmpFileName) } for _, kv := range retKVs { fmt.Fprintf(file, "%v %v\n", kv.Key, kv.Value) } // rename file newFileName := strings.Replace(tmpFileName, "tmp", "mr", -1) os.Rename(tmpFileName, newFileName) // notify master that we have done this task finishReduceTask(task.TaskId) }