// Raft role for each raft server const ( FOLLOWER RaftRole = 1 << iota CANDIDATE LEADER )
// log entry contains command and term information type LogEntry struct { // NOTE: may be modified in next labs Term int// term when entry was received by leader Command interface{} }
// // A Go object implementing a single Raft peer. // type Raft struct { mu sync.Mutex // Lock to protect shared access to this peer's state roleChangeCond *sync.Cond // used for election thread, wait role be changed to `FOLLOWER` or 'CANDIDATE` peers []*labrpc.ClientEnd // RPC end points of all peers persister *Persister // Object to hold this peer's persisted state me int// this peer's index into peers[] dead int32// set by Kill() role RaftRole // who am i?
// Persistent states currentTerm int votedFor int// vote for which candidate? (represent in `candidateId`), -1 means no vote before log []LogEntry
// Volatile states // on all servers commitIndex int// index of hightest log entry that known to be committed lastAppliedIndex int// index of highest log entry applied to state machine
// on leaders nextIndex []int// for peers, index of the next log entry to send to that server matchIndex []int// for peers, index of highest og entry known to be replicated on server. NOTE: "2022-2-21: 目前认为是每次心跳replica log后,peer ack后的确定id"
// timer settings electionTimeout int// ms, changed in `Candidate`(send request and reset timer), `Followers when receive heartbeat, or grant vote for candidate in "RequestVote RCP"` }
for { ... rf.mu.Lock() for rf.role == LEADER && !rf.killed() { rf.roleChangeCond.Wait() } if rf.killed() { rf.mu.Unlock() break } ... }
除此外,这里还加入了 killed后,退出routine的逻辑。
第三个问题是,如何随机化时间?
我采用如下公式来随机化:
1
The real electiontimeout = baseElectionTimeout + rand.Int(minRandDis, maxRandDis)
具体参数设定如下:
1 2 3 4
const baseElectionTimeout = 80// ms, this this as network latency // random Disturbance for election timeout. const minRandDis = 400 const maxRandDis = 700
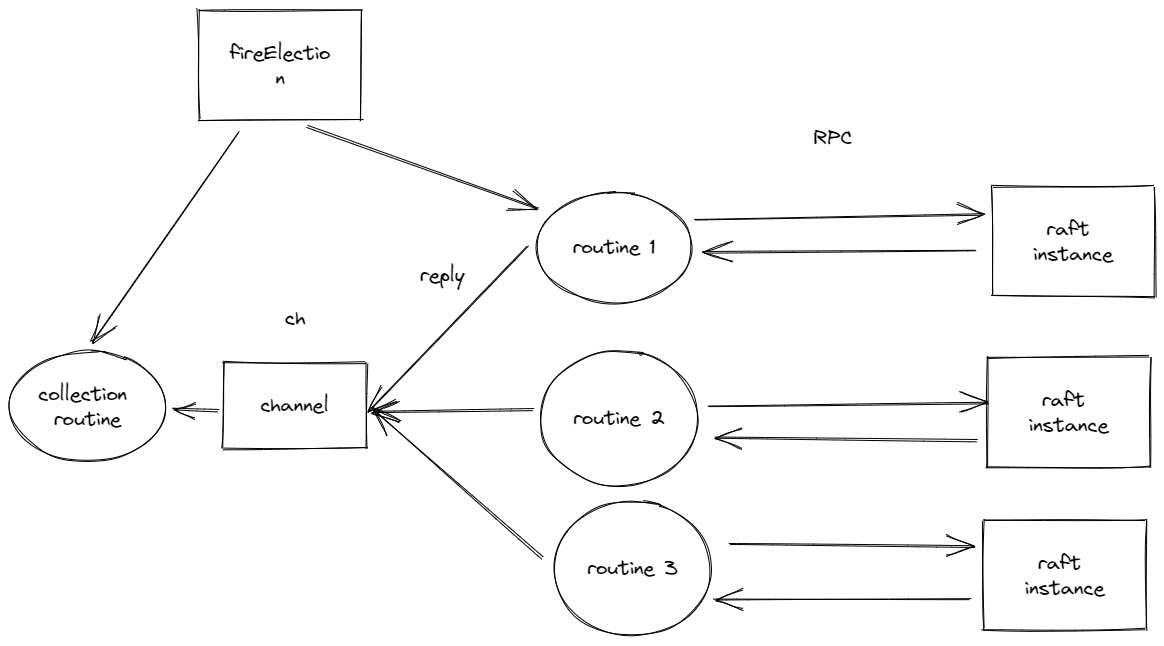
// NOTE: must be guarded by rf.mu func(rf *Raft) fireElection() { if rf.role == FOLLOWER { rf.changeRoleTo(CANDIDATE) } DPrintf("[%d] current role %v, fire a new election\n", rf.me, rf.role)
// start new election rf.currentTerm++ DPrintf("[%d] currentTerm++", rf.me) rf.votedFor = rf.me rf.resetElectionTimer() // send RequestVote to peers gofunc() { var curTerm int // send // build args, actually if we move `build args` into outside, we can avoid one lock acquire rf.mu.Lock() curTerm = rf.currentTerm lastLogTerm := -1 iflen(rf.log) != 0 { lastLogTerm = rf.log[len(rf.log)-1].Term } args := &RequestVoteArgs{ Term: rf.currentTerm, CandidateId: rf.me, LastLogIndex: len(rf.log), LastLogTerm: lastLogTerm, } rf.mu.Unlock()
ch := make(chan RequestVoteReply) go rf.doSendRequestVote(args, ch)
// wait <-done if rf.killed() { return } // update if need rf.mu.Lock() if rf.currentTerm < maxTermFromRsp { rf.currentTerm = maxTermFromRsp rf.changeRoleTo(FOLLOWER) } if voteNum*2 > len(rf.peers) { // double check whether curTerm is the same with rf.currentTerm to avoid while executing `RequestVote`, the candidate had started a new election if curTerm != rf.currentTerm || rf.role != CANDIDATE { rf.mu.Unlock() return } rf.changeRoleTo(LEADER) DPrintf("[%d] becomes leader\n", rf.me) // NOTE: leader routine } rf.mu.Unlock() }() }
func(rf *Raft) doSendRequestVote(args *RequestVoteArgs, ch chan<- RequestVoteReply) { var chCloseCnt int32 = int32(len(rf.peers) - 1) // use this to close `ch` // sender for i := 0; i < len(rf.peers); i++ { // peers is read-only once created, so no mutex needed // if rf.killed() { // if rf is killed, return immediately // return // } if i == rf.me { // rf.me is read-only once created continue } gofunc(svrId int) { var reply RequestVoteReply rf.sendRequestVote(svrId, args, &reply) DPrintf("[%d] --> [%d] RequestVote Done\n", rf.me, svrId) ch <- reply cnt := atomic.AddInt32(&chCloseCnt, -1) if cnt == 0 { // receive all reply, close channel now DPrintf("close ch channel in fireElection\n") close(ch) } }(i) } }
func(rf *Raft) doReceiveRequestVoteReply(replyCh <-chan RequestVoteReply, done chan<- bool, maxTermFromRsp *int, voteNum *int) { var once sync.Once voted := 1 tmpMaxTerm := 0 for { // if rf.killed() { // close(done) // actually we don't need this, now that rf is killed, blocked routines will be reclaimed by GC or OS // return // } reply, ok := <-replyCh if !ok { close(done) return } if reply.Term > *maxTermFromRsp { tmpMaxTerm = reply.Term } if reply.VoteGranted { // no mutex needed, `done chanel` will sync `*voteNum` and `maxTermFromRsp` for us voted++ if2*voted > len(rf.peers) { once.Do(func() { // we can't break loop because we need to receive all data from the channel, otherwise some goroutine will be blocked forever *voteNum = voted *maxTermFromRsp = tmpMaxTerm done <- true }) } } } }
采用 sync.Once来保证一旦收到半数以上的票后,只用反馈一次给外层routine。
最后还有一个注意点为:
在fireElection中的routine的最后几行中有如下:
1 2 3 4 5
// double check whether curTerm is the same with rf.currentTerm to avoid while executing `RequestVote`, the candidate had started a new election if curTerm != rf.currentTerm || rf.role != CANDIDATE { rf.mu.Unlock() return }
func(rf *Raft) RequestVote(args *RequestVoteArgs, reply *RequestVoteReply) { // Your code here (2A, 2B). rf.mu.Lock() // maybe receive RequestVote by multiple candidates at the same time, so we need this guard defer rf.mu.Unlock() // this procedure isn't expensive, so give it a big latch
if args.Term < rf.currentTerm { return } if args.Term > rf.currentTerm { rf.currentTerm = args.Term rf.votedFor = -1 }
if rf.votedFor != -1 { // voted before DPrintf("[%d] grant vote for [%d] failed: voted for [%d] before \n", rf.me, args.CandidateId, rf.votedFor) return } // check log is at least up-to-date or not iflen(rf.log) != 0 { lastLogEntry := rf.log[len(rf.log)-1] if lastLogEntry.Term > args.LastLogTerm || (lastLogEntry.Term == args.LastLogTerm && len(rf.log) > args.LastLogIndex) { DPrintf("[%d] vote for [%d] log check check failed\n", rf.me, args.CandidateId) return } } rf.votedFor = args.CandidateId rf.resetElectionTimer() // ok, check pass, grant vote for it DPrintf("[%d] grant vote for [%d]\n", rf.me, args.CandidateId) reply.VoteGranted = true }
// replica log entires and used as heart beat func(rf *Raft) fireAppendEntiresRPC() { gofunc() { var curTerm int replies := make([]AppendEntriesReply, len(rf.peers)) var waitGroup sync.WaitGroup
// send requests go rf.doSendAppendEntires(&waitGroup, replies) // wait until having received all replies waitGroup.Wait() if rf.killed() { return }
// update leaders' term if need maxTermFromRsp := 0 for i := 0; i < len(rf.peers); i++ { // if rf.killed() { // return // } if i == rf.me { continue } if replies[i].Term > maxTermFromRsp { maxTermFromRsp = replies[i].Term } } rf.mu.Lock() DPrintf("[%d] %+v, me term %d, maxTermFromRsp %d", rf.me, replies, rf.currentTerm, maxTermFromRsp) if rf.currentTerm != curTerm { // double check, because maybe `currentTerm` has been changed by other routine rf.mu.Unlock() return } if rf.currentTerm < maxTermFromRsp { rf.currentTerm = maxTermFromRsp } rf.mu.Unlock() }() }
/* TODO: 1. Reply false if term < currentTerm (§5.1) 2. Reply false if log doesn’t contain an entry at prevLogIndex whose term matches prevLogTerm (§5.3) 3. If an existing entry conflicts with a new one (same index but different terms), delete the existing entry and all that follow it (§5.3) 4. Append any new entries not already in the log 5. If leaderCommit > commitIndex, set commitIndex = min(leaderCommit, index of last new entry) */ // TODO: step 2-5 are ignored by now if rf.role != FOLLOWER { rf.changeRoleTo(FOLLOWER) } rf.resetElectionTimer() reply.Term = rf.currentTerm reply.Success = true DPrintf("[%d] get an AppendEntiresRPC from leader [%d]\n", rf.me, args.LeaderId) }
注意状态转换:
1 2 3
if rf.role != FOLLOWER { rf.changeRoleTo(FOLLOWER) }
If RPC request or response contains term T > currentTerm: set currentTerm = T, convert to follower (§5.1). 除此外,还应该将voteFor设置为nil(我设置为-1),因为已经进入到新的一轮term