LockShared(Transaction, RID): Transaction txn tries to take a shared lock on record id rid. This should be blocked on waiting and should return true when granted. Return false if transaction is rolled back (aborts).
LockExclusive(Transaction, RID): Transaction txn tries to take an exclusive lock on record id rid. This should be blocked on waiting and should return true when granted. Return false if transaction is rolled back (aborts).
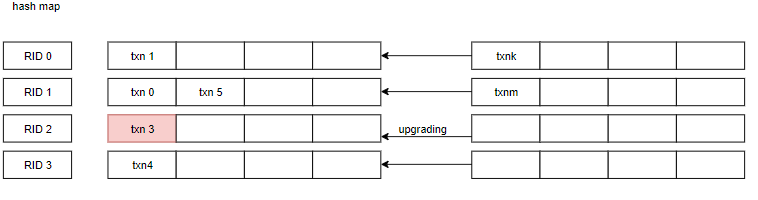
LockUpgrade(Transaction, RID): Transaction txn tries to upgrade a shared to exclusive lock on record id rid. This should be blocked on waiting and should return true when granted. Return false if transaction is rolled back (aborts). This should also abort the transaction and return false if another transaction is already waiting to upgrade their lock.
Unlock(Transaction, RID): Unlock the record identified by the given record id that is held by the transaction.
boolLockManager::LockShared(Transaction *txn, const RID &rid){ if (txn->GetState() == TransactionState::ABORTED) { returnfalse; } if (txn->GetState() == TransactionState ::SHRINKING) { txn->SetState(TransactionState::ABORTED); throwTransactionAbortException(txn->GetTransactionId(), AbortReason::LOCK_ON_SHRINKING); } if (txn->GetIsolationLevel() == IsolationLevel::READ_UNCOMMITTED) { /* read uncommitted doesn't need any S lock */ returnfalse; } if (txn->IsSharedLocked(rid) || txn->IsExclusiveLocked( rid)) { /* exclusive lock is larger than shared lock, so we think exclusive lock as a shared lock */ returntrue; }
/* now we get the shared lock, put it into txn's shared lock set */ txn->GetExclusiveLockSet()->emplace(rid); txn->SetState(TransactionState::GROWING);
boolLockManager::Unlock(Transaction *txn, const RID &rid){ if (!txn->IsSharedLocked(rid) && !txn->IsExclusiveLocked(rid)) { returntrue; /* no need to unlock */ } /* rc shouldn't get shared lock */ assert(!(txn->GetIsolationLevel() == IsolationLevel::READ_UNCOMMITTED && txn->IsSharedLocked(rid))); std::unique_lock<std::mutex> lck(latch_); auto &req_queue = lock_table_[rid].request_queue_; assert(!req_queue.empty()); req_queue.pop_front(); lock_table_[rid].cv_.notify_all(); /* notify all waitting threads */ /* change txn state to shrinking if txn isolation is "RR"! */ if (txn->GetState() != TransactionState::ABORTED && txn->GetState() != TransactionState::COMMITTED) { if (txn->GetIsolationLevel() == IsolationLevel::REPEATABLE_READ) { /* RR unlocks all locks until txn ends, so no other locks can be get */ txn->SetState(TransactionState::SHRINKING); } } txn->GetSharedLockSet()->erase(rid); txn->GetExclusiveLockSet()->erase(rid); returntrue; }
需要注意的地方有两点:
RU 隔离级别不会获取S lock,所以我加了assert。
RR模式只要Unlock,设置txn State为SHRINKING,RC和RU则应该在Unlock X lock才设置状态为SHRINKING。
The graph API you must implement and use for your cycle detection along with testing is the following:
AddEdge(txn_id_t t1, txn_id_t t2): Adds an edge in your graph from t1 to t2. If the edge already exists, you don’t have to do anything.
RemoveEdge(txn_id_t t1, txn_id_t t2): Removes edge t1 to t2 from your graph. If no such edge exists, you don’t have to do anything.
HasCycle(txn_id_t& txn_id): Looks for a cycle by using the Depth First Search (DFS) algorithm. If it finds a cycle, HasCycle should store the transaction id of the youngest transaction in the cycle in txn_id and return true. Your function should return the first cycle it finds. If your graph has no cycles, HasCycle should return false.
GetEdgeList(): Returns a list of tuples representing the edges in your graph. We will use this to test correctness of your graph. A pair (t1,t2) corresponds to an edge from t1 to t2.
RunCycleDetection(): Contains skeleton code for running cycle detection in the background. You should implement your cycle detection logic in here.
在进行死锁检测时,额外的要求为:
Your DFS Cycle detection algorithm must be deterministic. In order to do achieve this, you must always choose to explore the lowest transaction id first. This means when choosing which unexplored node to run DFS from, always choose the node with the lowest transaction id. This also means when exploring neighbors, explore them in sorted order from lowest to highest.
When you find a cycle, you should abort the youngest transaction to break the cycle by setting that transactions state to ABORTED.
When your detection thread wakes up, it is responsible for breaking all cycles that exist. If you follow the above requirements, you will always find the cycles in a deterministic order. This also means that when you are building your graph, you should not add nodes for aborted transactions or draw edges to aborted transactions.
boolInsertExecutor::Next([[maybe_unused]] Tuple *tuple, RID *rid){ /** * RR, RC, RU all should release lock when txn aborted or committed */ RID inserted_rid; Tuple inserted_tuple; std::vector<Tuple> pending_inserted_tuples;
/* insert value directly */ if (child_executor_ == nullptr) { auto values = plan_->RawValues(); /* Insert all values int to tables */ for (const std::vector<Value> &entry : values) { inserted_tuple = Tuple(entry, schema_); pending_inserted_tuples.push_back(inserted_tuple); } } else { /* insert from child_executor */ while (child_executor_->Next(&inserted_tuple, &inserted_rid)) { pending_inserted_tuples.push_back(inserted_tuple); } }
for (constauto &pending_inserted_tuple : pending_inserted_tuples) { /* do insert */ /* NOTE: function "InsertTuple" maintains the write set which is used to rollback */ if (!table_meta_->table_->InsertTuple(pending_inserted_tuple, &inserted_rid, exec_ctx_->GetTransaction())) { returnfalse; } if (!TryLock(inserted_rid)) { exec_ctx_->GetTransaction()->SetState(TransactionState::ABORTED); returnfalse; }
/* Update index */ for (IndexInfo *idx_info : idx_infos_) { idx_info->index_->InsertEntry(pending_inserted_tuple, inserted_rid, exec_ctx_->GetTransaction()); /* maintain writeset used to rollback txn(I know it's somewhat a ugly way, but I have no other choose) */ IndexWriteRecord index_write_record(inserted_rid, table_meta_->oid_, WType::INSERT, pending_inserted_tuple, idx_info->index_oid_, exec_ctx_->GetCatalog()); exec_ctx_->GetTransaction()->AppendTableWriteRecord(index_write_record); } } returnfalse; }
bool UpdateExecutor::TryLock(RID rid) { try { if (exec_ctx_->GetTransaction()->GetIsolationLevel() == IsolationLevel::READ_COMMITTED) { /* child_executor get shared lock, now we want to update tuples, so upgrade the shared lock to exclusive lock */ return exec_ctx_->GetLockManager()->LockExclusive(exec_ctx_->GetTransaction(), rid); } if (exec_ctx_->GetTransaction()->GetIsolationLevel() == IsolationLevel::REPEATABLE_READ) { /* child_executor get shared lock, now we want to update tuples, so upgrade the shared lock to exclusive lock */ return exec_ctx_->GetLockManager()->LockUpgrade(exec_ctx_->GetTransaction(), rid); } } catch (const TransactionAbortException &e) { return false; } return false; }
boolDeleteExecutor::TryLock(RID rid){ try { /* when execute deletion operation on rid, the rid has been in the shared lock mode */ return exec_ctx_->GetLockManager()->LockUpgrade(exec_ctx_->GetTransaction(), rid); } catch (const TransactionAbortException &e) { returnfalse; } returnfalse; }