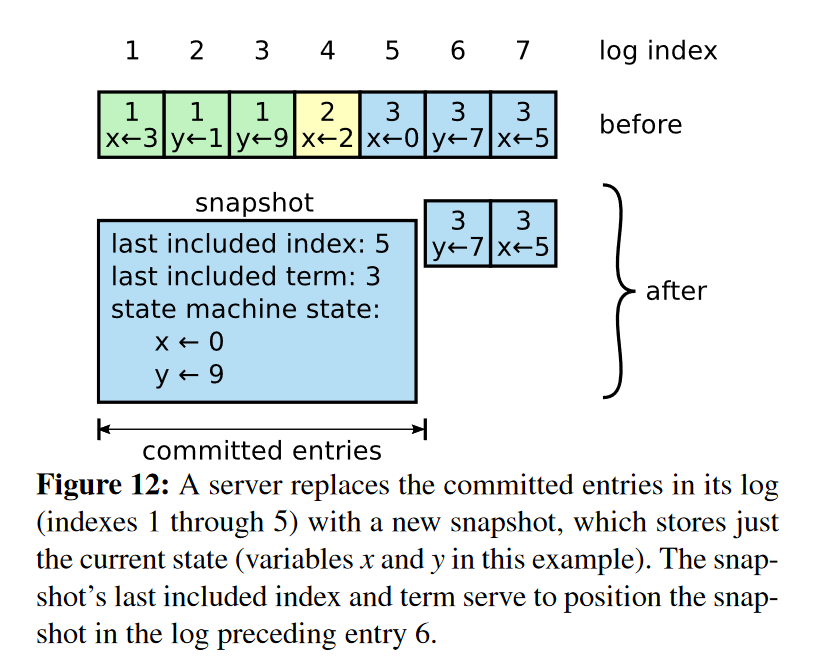
某个时刻,由raft的上层服务向raft发起Log Compaction请求,这个请求会带上log需要压缩到哪个地方参数(index), 另外还会发送service的状态数据snapshot,当raft收到该请求后,根据index将log做裁剪,并保留被裁剪部分的最后一个log entry的相关信息,即 last included index 和 last included term. 另外,还需持久化上层service状态(snapshot)和raft此时的状态,用于后续的重启恢复。当svr重启后,service可通过读取snapshot恢复至发起Log Compaction请求时的状态,最后重放raft log恢复至系统关机前的状态(此部分还未验证,待lab3做完后更新)。
type VLog struct { LastIncludedTerm int// last term at last index of log entries in snapshot LastIncludedIndex int// last index of snapshot, default value: -1 Logs []LogEntry // log entries following snapshot }
// return global log lengths containing snsapshot func(vlog *VLog) length() int
// // check global log is empty or not? // func(vlog *VLog) empty() bool
// get term number of global log at `idx` func(vlog *VLog) getTermAt(idx int) int
// // return global log entry at index 'idx' // if vlog doesn't contain the log at index `idx`, `sucess` will be set to false // func(vlog *VLog) indexAt(idx int) (entry LogEntry, success bool) // // set local log // func(vlog *VLog) setLog(logs []LogEntry) // // cut global logs from start to `end` but exclude log at end, i.e. get log[0,end) // this does change vlog.log content, jsut return a reference of the range slice // func(vlog *VLog) cutLog(start int, end int) []LogEntry
// compact log up to `index` inclued `index` // NOTE: must be guared by mutex func(vlog *VLog) logCompaction(index int)
func(rf *Raft) Snapshot(index int, snapshot []byte) { // Your code here (2D). index = index - 1// fix index by minus 1 // Do illegal check rf.mu.Lock(rf.me, "Snapshot") defer rf.mu.Unlock(rf.me, "Snpahost") // for debug if rf.lastAppliedIndex < index { log.Fatalf("[%d] lastAppliedIndex(%d) is less than index(%d)\n", rf.me, rf.lastAppliedIndex, index) }
DPrintf("[%d.%d.%d] start Snapshot, last include index=%d, current log real len(%d), virual len(%d)\n", rf.me, rf.role, rf.currentTerm, index, len(rf.vlog.Logs), rf.vlog.length()) if index < 0 || index <= rf.vlog.LastIncludedIndex || index >= rf.vlog.length() { log.Fatalf("[%d.%d.%d] Snapshot failed: index(%d) is illegal, current global log length(%d)\n", rf.me, rf.role, rf.currentTerm, index, rf.vlog.length()) } // save new snapshot rf.snapshot = snapshot rf.vlog.logCompaction(index) DPrintf("[%d.%d.%d] take snapshot success, real log len(%v), virtual log len(%v)\n", rf.me, rf.role, rf.currentTerm, len(rf.vlog.Logs), rf.vlog.length()) rf.persist() }
// save Raft's persistent state to stable storage, // where it can later be retrieved after a crash and restart. // see paper's Figure 2 for a description of what should be persistent. // // NOTE: must be guarded by rf.mu func (rf *Raft) persist() { DPrintf("[%d] persist state start, curTerm %d, voteFor %d, log %+v\n", rf.me, rf.currentTerm, rf.votedFor, rf.vlog.Logs) // Your code here (2C). // Example: w := new(bytes.Buffer) e := labgob.NewEncoder(w) e.Encode(rf.currentTerm) e.Encode(rf.votedFor) e.Encode(rf.vlog) data := w.Bytes() rf.persister.SaveStateAndSnapshot(data, rf.snapshot) DPrintf("[%d] persist state end, curTerm %d, voteFor %d, log %+v\n", rf.me, rf.currentTerm, rf.votedFor, rf.vlog.Logs) }
// // restore previously persisted state. // func (rf *Raft) readPersist(data []byte) { // NOTE: no lock need // rf.mu.Lock(rf.me, "readPersist") // defer rf.mu.Unlock(rf.me, "readPersist") if data == nil || len(data) < 1 { // bootstrap without any state? return } DPrintf("[%d] read state from storage\n", rf.me) // Your code here (2C). // Example: r := bytes.NewBuffer(data) d := labgob.NewDecoder(r) var currentTerm int var voteFor int var vlog VLog if d.Decode(¤tTerm) != nil || d.Decode(&voteFor) != nil || d.Decode(&vlog) != nil { DPrintf("[%d] [Error]: read state failed", rf.me) } else { rf.currentTerm = currentTerm rf.votedFor = voteFor rf.vlog = vlog rf.lastAppliedIndex = rf.vlog.LastIncludedIndex // !! rf.commitIndex = rf.vlog.LastIncludedIndex DPrintf("[%d] read state from storage, %+v\n", rf.me, rf) } }
// send InstallSnapshot rpc if rf.nextIndex[i] is less or equal than lastIncludeIndex if rf.nextIndex[i] <= rf.vlog.LastIncludedIndex { go rf.doSendSnpahost(svrId) }
// fire a new trun AppendEntriesRPC for svrId, AppendEntriesRPC may be executed many times go rf.reSendAppendEntries(replyInChan.svrId, pendingCommitIndex)