// NOTE: must be guared by mutex func(kv *KVServer) encodeServiceState() (snapshot []byte) { DPrintf("[%d] encode current service state, dataBase%+v, opRecord%+v\n", kv.me, kv.dataBase, kv.opRecord) w := new(bytes.Buffer) e := labgob.NewEncoder(w) e.Encode(kv.dataBase) e.Encode(kv.opRecord) snapshot = w.Bytes() return }
// NOTE: must be guarded by mutex func(kv *KVServer) decodeServiceState(snapshot []byte) { DPrintf("[%d] decode service state from snapshot\n", kv.me) r := bytes.NewBuffer(snapshot) d := labgob.NewDecoder(r) dataBase := make(map[string]string) opRecord := make(map[int64]int) // TODO: do we need to clear dataBase first? if d.Decode(&dataBase) != nil || d.Decode(&opRecord) != nil { log.Panicf("[%d] decode service state failed\n", kv.me) } kv.dataBase = dataBase kv.opRecord = opRecord DPrintf("[%d] decode service state success\n", kv.me) }
... kv.mu.Lock() ... // build channel var replyCh chan InternalReply if _, ok := kv.doneChanMap[idx]; !ok { // Started a command before DPrintf("[%d] create channel at index[%d]\n", kv.me, idx) kv.doneChanMap[idx] = make(chan InternalReply) replyCh = make(chan InternalReply) kv.doneChanMap[idx] = replyCh kv.mu.Unlock() } else { DPrintf("[%d] more than 1 command at the same idx(%d)\n", kv.me, idx) kv.mu.Unlock() }
// wait on channel DPrintf("[%d] <-- [%d] finish `Get` rf.Start, args:%+v\n", kv.me, args.ClientId, args) var tmpReply InternalReply select { case tmpReply = <-replyCh: // NOTE: check like Put operation for Get operation is unnecessary curTerm, isLeader := kv.rf.GetState() if curTerm != term || !isLeader { reply.Err = ErrWrongLeader DPrintf("[%d] <-- [%d] Server Get fail end, term(%d), curTerm(%d), isLeader(%v), tmpReply.Op(%v), args(%v)\n", kv.me, args.ClientId, term, curTerm, isLeader, tmpReply.OpIdentify, args.OpIdentify) return } reply.Err = tmpReply.Err reply.Value = tmpReply.Value DPrintf("[%d] <-- [%d] Server Get end, reply(%v)\n", kv.me, args.ClientId, reply) case <-time.After(commitLogTimeout * time.Millisecond): DPrintf("[%d] time up, give up idx=%d receiving Get%+v reply\n", kv.me, idx, args) reply.Err = ErrTimeout }
等待在replyCh上,并添加了超时等待机制,一旦超时,直接返回。这里遗留下了replyChan,如果未来raft commit此条log并上传至service,而service将通过log index log回传给rpc handler,而rpc handler已经因为timeout退出,所以service通过log index channel回传时,也需要超时检测。
func(rf *Raft) heartBeatFromChan() { SpecialPrintf("[%d] heartBeatFromChan start...\n", rf.me) // timerId := time.Now().Unix() for { val := <-rf.hBChan if val == hBChanEnd { if !rf.killed() { log.Panic("pass 1 to end hBChan, but rf instant is not killed, did you forget to set the dead flag?") } break } if val != hBChanContinue { log.Panic("only val = 0, we can send AppendEntriesRPC") } rf.mu.Lock(rf.me, "HeaderBeatTimer") rf.oneMoreTicker = true if rf.role == LEADER { DPrintf("[%d] fireAppendEntriesRPC\n", rf.me) rf.fireAppendEntries() } rf.mu.Unlock(rf.me, "HeaderBeatTimer") } SpecialPrintf("[%d] heartBeatFromChan end...\n", rf.me) }
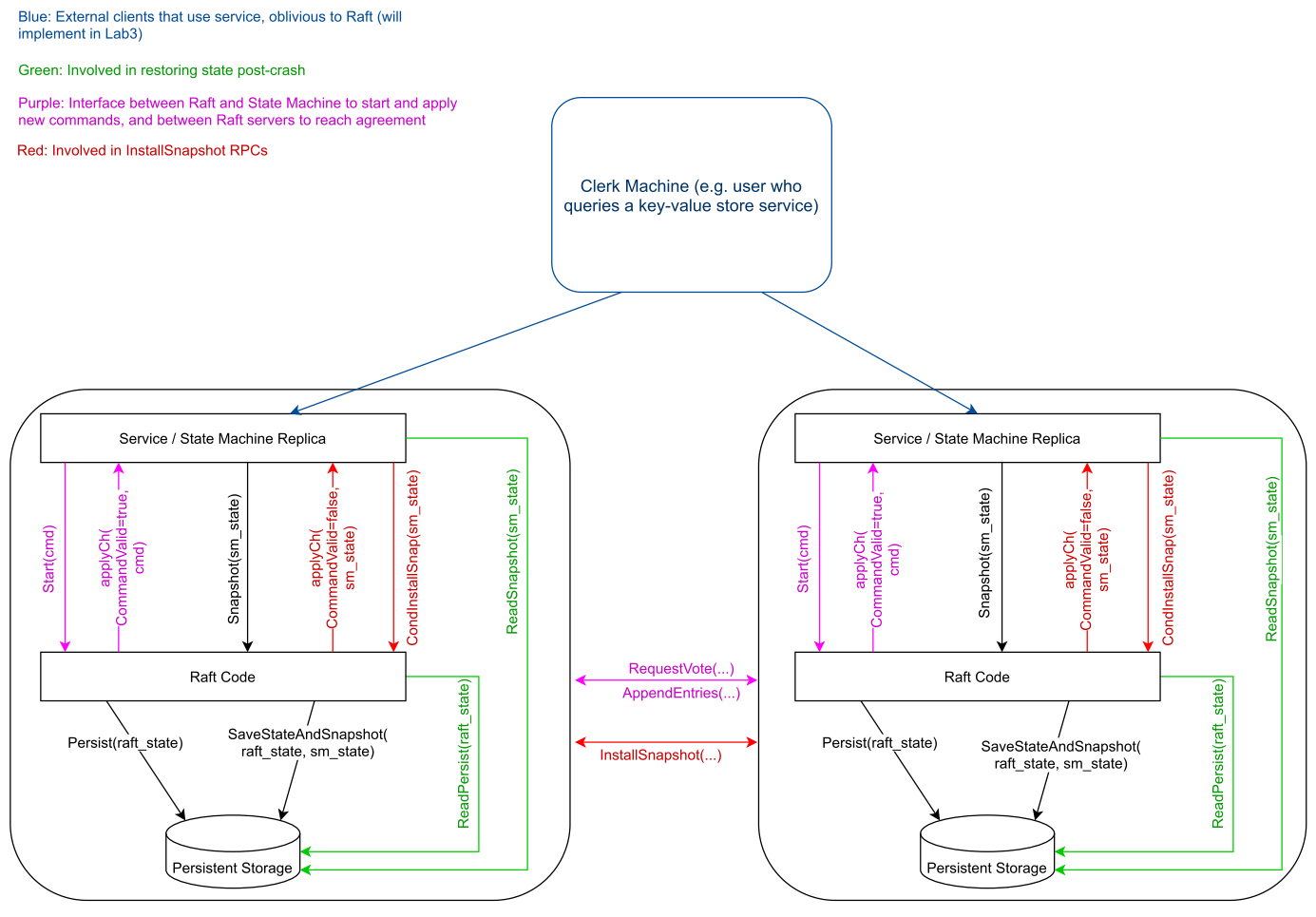
// // the service using Raft (e.g. a k/v server) wants to start // agreement on the next command to be appended to Raft's log. if this // server isn't the leader, returns false. otherwise start the // agreement and return immediately. there is no guarantee that this // command will ever be committed to the Raft log, since the leader // may fail or lose an election. even if the Raft instance has been killed, // this function should return gracefully. // // the first return value is the index that the command will appear at // if it's ever committed. the second return value is the current // term. the third return value is true if this server believes it is // the leader. // // NOTE: this is a thread-safe function func(rf *Raft) Start(command interface{}) (int, int, bool) { ... DPrintf("[%d] notify hBChan start", rf.me) select { case rf.hBChan <- hBChanContinue: // TODO: maybe stuck here? DPrintf("[%d] notify hBChan end", rf.me) case <-time.After(10 * time.Millisecond): DPrintf("[%d] notify hBChan timeout", rf.me) } return index, term, isLeader }