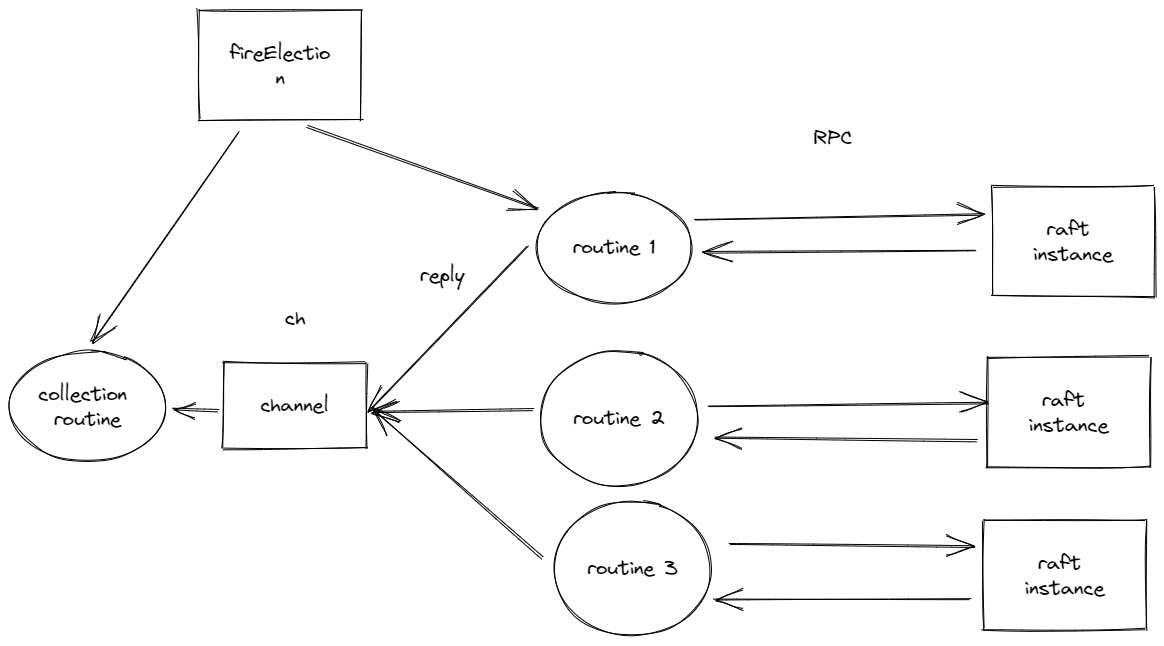
for { reply, ok := <-replyCh if !ok { return } if reply.Term > maxTermFromRsp { maxTermFromRsp = reply.Term } if reply.VoteGranted { voteNum++ if2*voteNum > len(rf.peers) { voteOnce.Do(func() { // we can't break loop because we need to receive all data from the channel, otherwise some goroutine will be blocked forever // update if need rf.mu.Lock(rf.me, "doReceiveRequestVoteReply.once") // double check whether curTerm is the same with rf.currentTerm to avoid while executing `RequestVote`, the candidate had started a new election if curTerm != rf.currentTerm || rf.role != CANDIDATE || rf.killed() { rf.mu.Unlock(rf.me, "doReceiveRequestVoteReply.once") return } if rf.currentTerm < maxTermFromRsp { rf.turnOnPendingPersist(rf.setNewTerm, maxTermFromRsp) rf.changeRoleTo(FOLLOWER) rf.mu.Unlock(rf.me, "doReceiveRequestVoteReply.once") return } rf.changeRoleTo(LEADER) DPrintf("[%d.%d.%d] becomes leader, log len:%d log content:%v \n", rf.me, rf.role, rf.currentTerm, len(rf.log), rf.log) rf.mu.Unlock(rf.me, "doReceiveRequestVoteReply.once") }) } } else { unVoteNum++ if2*unVoteNum >= len(rf.peers) { unVoteOnce.Do(func() { rf.mu.Lock(rf.me, "doReceiveRequestVoteReply.unVote") if curTerm != rf.currentTerm || rf.role != CANDIDATE || rf.killed() { rf.mu.Unlock(rf.me, "doReceiveRequestVoteReply.unVote") return } rf.changeRoleTo(FOLLOWER) rf.mu.Unlock(rf.me, "doReceiveRequestVoteReply.unVote") }) } } } }
follower:收到RequestVote,需要做一定log的校验(log at least up-to-date rule) ,看应该投同意票还是反对票. 一种投反对票的情况是我已经给其它svr投票了,而新来请求的term并不比我的curTerm高,此时我应该投反对票。另一种是对方的term比我的term低,此时也应该是反对票
func(rf *Raft) RequestVote(args *RequestVoteArgs, reply *RequestVoteReply) { rf.mu.Lock(rf.me, "RequestVote") defer rf.mu.Unlock(rf.me, "RequestVote") // this procedure isn't expensive, so give it a big latch DPrintf("[%d.%d.%d] grant vote for [%d] start... args:%+v \n", rf.me, rf.role, rf.currentTerm, args.CandidateId, args)
if args.Term < rf.currentTerm { return } if args.Term > rf.currentTerm { rf.turnOnPendingPersist(rf.setNewTerm, args.Term) // convert to follower if rf.role != FOLLOWER { rf.changeRoleTo(FOLLOWER) } }
if rf.votedFor != -1 { // voted before DPrintf("[%d.%d.%d] grant vote for [%d] failed: voted for [%d] before \n", rf.me, rf.role, rf.currentTerm, args.CandidateId, rf.votedFor) return } // check log is at least up-to-date or not iflen(rf.log) != 0 { lastLogEntry := rf.log[len(rf.log)-1] DPrintf("[%d.%d.%d] vote for [%d] log check start, my lastLogEntry is %+v\n", rf.me, rf.role, rf.currentTerm, args.CandidateId, lastLogEntry) if lastLogEntry.Term > args.LastLogTerm || (lastLogEntry.Term == args.LastLogTerm && len(rf.log) > args.LastLogIndex+1) { DPrintf("[%d.%d.%d] vote for [%d] log check check failed, my log content %+v\n", rf.me, rf.role, rf.currentTerm, args.CandidateId, rf.log) return } } rf.turnOnPendingPersist(rf.setVoteFor, args.CandidateId) rf.resetElectionTimer() if rf.role == LEADER { // now all checks pass, I will vote for other svr, so give up my leader role rf.changeRoleTo(FOLLOWER) } // ok, grant vote for it reply.VoteGranted = true
// for debug lastLogEntry := LogEntry{} iflen(rf.log) > 0 { lastLogEntry = rf.log[len(rf.log)-1] } DPrintf("[%d.%d.%d] grant vote for [%d] success, my last log content %+v, arg last term (%d), last log index(%d)\n", rf.me, rf.role, rf.currentTerm, args.CandidateId, lastLogEntry, args.Term, args.LastLogIndex) }
func(rf *Raft) doSendAppendEntries(replyCh chan AppendEntriesReplyInCh, curTerm, pendingCommitIndex int) { rf.mu.Lock(rf.me, "doSendAppendEntries") defer rf.mu.Unlock(rf.me, "doSendAppendEntries") var sendRpcNum int32 = 0// use this to determine when to close channel var timeoutCnt int32 = 0 var timeoutOnce sync.Once // for debug // curTerm := rf.currentTerm curRole := rf.role nowTime := time.Now().UnixNano()
for i := 0; i < len(rf.peers) && rf.role == LEADER; i++ { if i == rf.me { continue } if rf.currentTerm != curTerm { close(replyCh) // close channel to exit Collection(receive) routine break }
prevLogTerm := -1 prevLogIndex := -1 var entries []LogEntry if rf.nextIndex[i] > 0 { DPrintf("[%d] build nextIndex args: log len:%d, nextIndex[%d]=%d\n", rf.me, len(rf.log), i, rf.nextIndex[i]) prevLogTerm = rf.log[rf.nextIndex[i]-1].Term prevLogIndex = rf.nextIndex[i] - 1 } elseif rf.nextIndex[i] < 0 && pendingCommitIndex >= 0 { // NOTE: Fix bug: if svr becomes leader, set all nextIndex to -1, then accepted new logs, and then doSendAppendEntries rf.nextIndex[i] = 0 }
if rf.nextIndex[i] >= 0 { // for debug if rf.nextIndex[i] > pendingCommitIndex+1 { log.Panicf("rf.nextIndex[i]=%d is large than pendingCommitIndex=%d", rf.nextIndex[i], pendingCommitIndex) } entries = make([]LogEntry, 0) // do a copy entries = append(entries, rf.log[rf.nextIndex[i]:pendingCommitIndex+1]...) }
args := &AppendEntriesArg{ Term: rf.currentTerm, LeaderId: rf.me, PrevLogIndex: prevLogIndex, PrevLogTerm: prevLogTerm, Entries: entries, LeaderCommit: rf.commitIndex, } DPrintf("[%d.%d.%d] [%v] --> [%d] sendAppendEntries, total log len:%d, args:%+v, nextIndex[%d]=%d, pendingCommitIndex=%d\n", rf.me, rf.role, rf.currentTerm, nowTime, i, len(rf.log), args, i, rf.nextIndex[i], pendingCommitIndex) gofunc(svrId int) { var reply AppendEntriesReply ok := rf.sendAppendEntries(svrId, args, &reply) DPrintf("[%d.%d.%d] [%v] --> [%d] AppendEntries Done, reply:%+v\n", rf.me, curRole, curTerm, nowTime, svrId, reply) if ok { rf.mu.Lock(rf.me, "doSendAppendEntries1") if !rf.killed() { rf.mu.Unlock(rf.me, "doSendAppendEntries1") replyCh <- AppendEntriesReplyInCh{ AppendEntriesReply: reply, svrId: svrId, } rf.mu.Lock(rf.me, "doSendAppendEntries1") } rf.mu.Unlock(rf.me, "doSendAppendEntries1") } else { DPrintf("[%d] timeout\n", rf.me) if2*atomic.AddInt32(&timeoutCnt, 1) > int32(len(rf.peers)) { timeoutOnce.Do(func() { rf.mu.Lock(rf.me, "doSendAppendEntries1") // seems like I lost the leader relationship (maybe network partition, or maybe I am sole now) if curTerm == rf.currentTerm && rf.role == LEADER && !rf.killed() { DPrintf("[%d] commit operation failed, can't get majority rsp\n", rf.me) rf.changeRoleTo(FOLLOWER) // consider to execute only once? } rf.mu.Unlock(rf.me, "doSendAppendEntries1") }) } } cnt := atomic.AddInt32(&sendRpcNum, 1) // NOTE: sendPrcNum++ here to prevent close opeartion(below) was executed ahead of replyCh channel due to no one accpet reply ifint(cnt) == len(rf.peers)-1 { close(replyCh) // DPrintf("[%d.%d.%d] SendAppendEntries close reply channel\n", rf.me, curRole, curTerm) } }(i) } DPrintf("[%d.%d.%d] main routine of SendAppendEntries exists, sub routine unsure \n", rf.me, rf.role, rf.currentTerm) }
rf.mu.Lock(rf.me, "doReceiveAppendEntries1") if reply.Term > rf.currentTerm { DPrintf("[%d.%d.%d] --> [%d] , remote term %d is large than me \n", rf.me, rf.role, rf.currentTerm, reply.svrId, reply.Term) rf.turnOnPendingPersist(rf.setNewTerm, reply.Term) rf.changeRoleTo(FOLLOWER) // someone's term is large than me, so give up leader role and change to follower rf.mu.Unlock(rf.me, "doReceiveAppendEntries1") continue }
// NOTE:update nextIndex and matchIndex even though the reply is stale data rf.updateNextIndex(reply, pendingCommitIndex)
// discard stale rsp if curTerm != rf.currentTerm || rf.role != LEADER || rf.killed() { rf.mu.Unlock(rf.me, "doReceiveAppendEntries1") continue }
if reply.Success { successCnt++ } if2*successCnt > len(rf.peers) { if successCnt == len(rf.peers) { // all svrs hold the logs precedeing(contains) `pendingCommitIndex` // NOTE: this branch is used to handle the scenario that receive `rf.log[pendingCommitIndex].Term < curTerm` // but no curTerm log entry anymore, which will cause the logs precedeing pendingCommitIndex never be // committed and client will timeout if rf.commitIndex < pendingCommitIndex { DPrintf("[%d] [%v] all svrs hold the log precedeing(contain) index %d\n", rf.me, nowTime, pendingCommitIndex) rf.commitLog(pendingCommitIndex) } // } } else { succOne.Do(func() { rf.hBStopByCommitOp = false// force to reset preempByCommit so that heartBeatTimer can send msg if rf.commitIndex >= pendingCommitIndex || // exclude later heartbeat commit first rf.log[pendingCommitIndex].Term != curTerm { // NOTE:!!!! raft paper figure 8 prevention, we can't commit log entry from previous term!!!! return } rf.commitLog(pendingCommitIndex) }) } } rf.mu.Unlock(rf.me, "doReceiveAppendEntries1") } }
首先是 leader角色退位, 如果收到的rpc响应的term比自身还高,需要主动退位:
1 2 3 4 5 6 7 8 9 10 11 12
if reply.Term > rf.currentTerm { DPrintf("[%d.%d.%d] --> [%d] , remote term %d is large than me \n", rf.me, rf.role, rf.currentTerm, reply.svrId, reply.Term) // for debug if reply.Success { log.Panicf("reply.Term is large than me, but reply.Success is true") } rf.turnOnPendingPersist(rf.setNewTerm, reply.Term)
rf.changeRoleTo(FOLLOWER) // someone's term is large than me, so give up leader role and change to follower rf.mu.Unlock(rf.me, "doReceiveAppendEntries1") continue }
if successCnt == len(rf.peers) { // all svrs hold the logs precedeing(contains) `pendingCommitIndex` // NOTE: this branch is used to handle the scenario that receive `rf.log[pendingCommitIndex].Term < curTerm` // but no curTerm log entry anymore, which will cause the logs precedeing pendingCommitIndex never be // committed and client will timeout if curTerm == rf.currentTerm && rf.role == LEADER && !rf.killed() && rf.commitIndex < pendingCommitIndex { DPrintf("[%d] [%v] all svrs hold the log precedeing(contain) index %d\n", rf.me, nowTime, pendingCommitIndex) rf.commitLog(pendingCommitIndex) } }
当所有svr都回复了成功,也即所有svr都有了该条log的副本,此时我们可以提交该log。
提交log的代码如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
// NOTE: must be guarded by rf.mu func(rf *Raft) commitLog(pendingCommitIndex int) { // for debugging if rf.commitIndex >= pendingCommitIndex { log.Panicf("[%d] rf.commitIndex(%d) is larger equal than pendingCommitIndex(%d)\n", rf.me, rf.commitIndex, pendingCommitIndex) } rf.commitIndex = pendingCommitIndex DPrintf("[%d.%d.%d] committedIndex to %d\n", rf.me, rf.role, rf.currentTerm, rf.commitIndex) DPrintf("[%d.%d.%d] get majority of appendentries rsp, change committedIndex to %d\n", rf.me, rf.role, rf.currentTerm, pendingCommitIndex) // notify applier rf.committedChangeCond.Broadcast() rf.hBStopByCommitOp = true rf.mu.Unlock(rf.me, "doReceiveAppendEntries1") // fire next turn AppendEntries to tell others to commit rf.fireAppendEntries(false) rf.mu.Lock(rf.me, "doReceiveAppendEntries3") // TODO:lock followed unlock immediately, how to fix this? use `go rf.fireAppendEntries` is another way, but launch a new goroutine is costly too }
for i := 0; i < len(pendingApplyLog); i++ { applyMsg := ApplyMsg{ CommandValid: true, // NOTE: how to use this? maybe need to fix this in the future Command: pendingApplyLog[i].Command, CommandIndex: lastAppliedIndex + 1 + i, // raft's log id starts from 0, but service starts from 1, so fix it by plus 1 } rf.applyCh <- applyMsg DPrintf("[%d] applier feeds command, applymsg:%+v\n", rf.me, applyMsg) }
DPrintf("[%d.%d.%d] AppendEntriesRPC start from leader [%d], commitIndex=%d log len:%d, log info %v\n", rf.me, rf.role, rf.currentTerm, args.LeaderId, rf.commitIndex, len(rf.log), rf.log) // for debug // if rf.role == LEADER && rf.currentTerm >= args.Term { // log.Panicf("[%d.%d.%d] AppendEntriesRPC start from leader [%d], my term is larger than args.Term(%d)\n", rf.me, rf.role, rf.currentTerm, args.LeaderId, args.Term) // } // init reply rf.resetElectionTimer() reply.Term = rf.currentTerm reply.Success = false reply.XTerm = -1 reply.XIndex = -1 reply.XLen = -1
// 1. Reply false if term < currentTerm (§5.1) if args.Term < rf.currentTerm { DPrintf("[%d.%d.%d] AppendEntriesRPC from leader [%d], args Term less than me %v\n", rf.me, rf.role, rf.currentTerm, args.LeaderId, args.Term) return }
// follow all server rule if args.Term > rf.currentTerm { rf.turnOnPendingPersist(rf.setNewTerm, args.Term) } if rf.role != FOLLOWER { rf.changeRoleTo(FOLLOWER) } if rf.votedFor != args.LeaderId { rf.turnOnPendingPersist(rf.setVoteFor, args.LeaderId) }
logChanged := false// use this to avoid unnecessary persist if args.PrevLogIndex != -1 { // 2. Reply false if log doesn’t contain an entry at prevLogIndex whose term matches prevLogTerm (§5.3) iflen(rf.log)-1 < args.PrevLogIndex { // case 3: rf.log is too short reply.XLen = len(rf.log) DPrintf("[%d.%d.%d] my log len is too short", rf.me, rf.role, rf.currentTerm) return } if rf.log[args.PrevLogIndex].Term != args.PrevLogTerm { reply.XTerm = rf.log[args.PrevLogIndex].Term reply.XIndex = args.PrevLogIndex i := args.PrevLogIndex - 1 // find the first index of args.PrevLogTerm in rf.log for i >= 0 && rf.log[i].Term == rf.log[i+1].Term { reply.XIndex = i i-- } DPrintf("[%d.%d.%d] set XTerm(%d) xIndex(%d)", rf.me, rf.role, rf.currentTerm, reply.XTerm, reply.XIndex) return } // check pass, cut rf.log if len(rf.log) -1 != args.PrevLogIndex iflen(rf.log)-1 != args.PrevLogIndex { logChanged = true rf.log = rf.log[:args.PrevLogIndex+1] } } else { // clear log, because leader sent a full log iflen(rf.log) != 0 { logChanged = true rf.log = []LogEntry{} } } // 4. Append any new entries not already in the log if logChanged || len(args.Entries) != 0 { rf.turnOnPendingPersist(rf.setLog, append(rf.log, args.Entries...)) } // 5. If leaderCommit > commitIndex, set commitIndex = min(leaderCommit, index of last new entry) if args.LeaderCommit > rf.commitIndex { if args.LeaderCommit > len(rf.log)-1 { if rf.commitIndex > len(rf.log)-1 { log.Panicf("[%d] rf.commitIndex(%d) is less than len of rf.log -1(%d)\n", rf.me, rf.commitIndex, len(rf.log)-1) } rf.commitIndex = len(rf.log) - 1 } else { rf.commitIndex = args.LeaderCommit } // notify applier rf.committedChangeCond.Broadcast() // NOTE: maybe do a batch persist? DPrintf("[%d] rf.commitIndex=%d \n", rf.me, rf.commitIndex) DPrintf("[%d] take AppendEntries RPC, now change commitIndex to %d\n", rf.me, rf.commitIndex) } reply.Success = true DPrintf("[%d.%d.%d] AppendEntriesRPC end from leader [%d], commitIndex=%d, log len:%d, log info %v\n", rf.me, rf.role, rf.currentTerm, args.LeaderId, rf.commitIndex, len(rf.log), rf.log) }