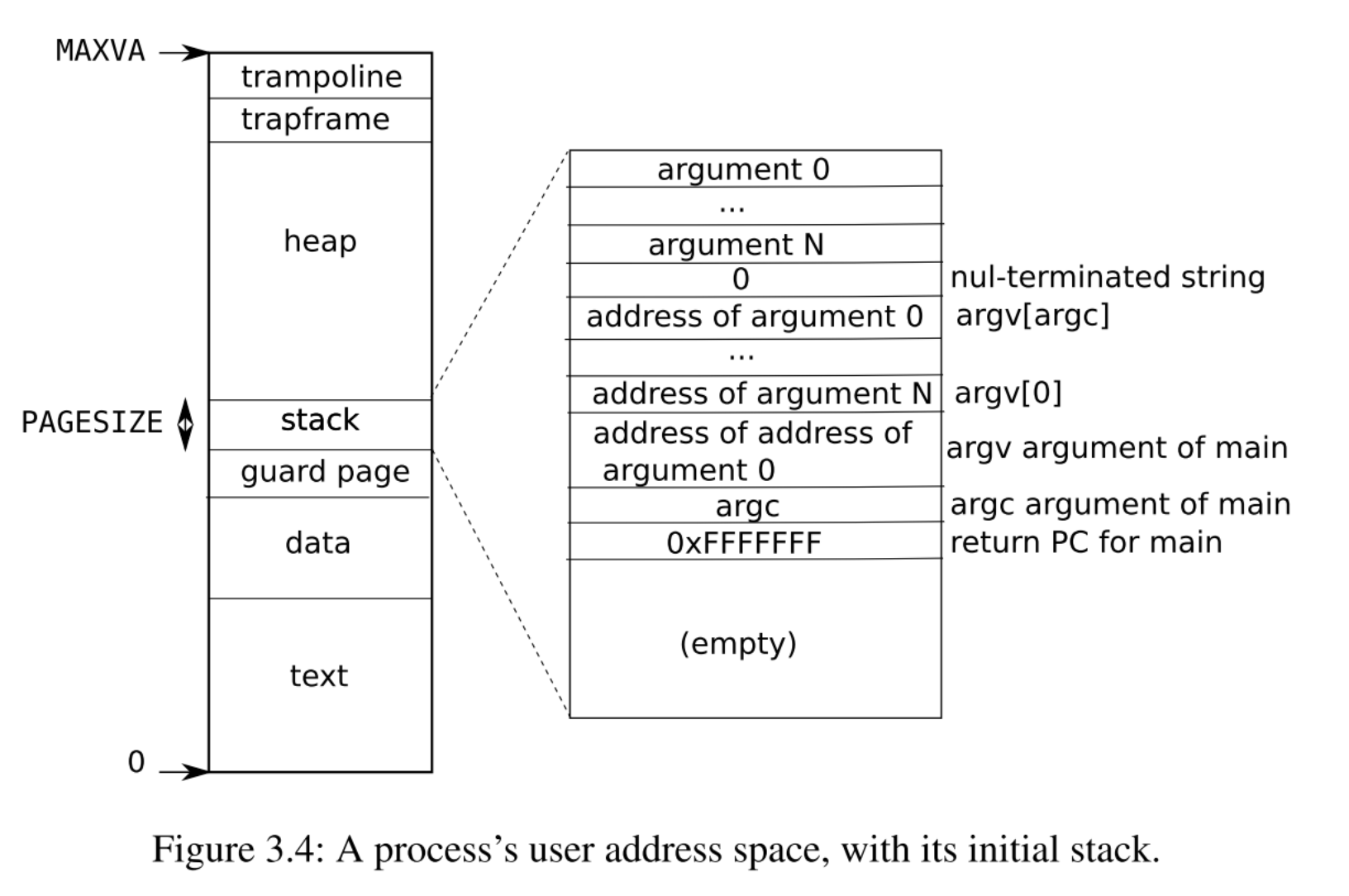
// Return the address of the PTE in page table pagetable // that corresponds to virtual address va. If alloc!=0, // create any required page-table pages. // // The risc-v Sv39 scheme has three levels of page-table // pages. A page-table page contains 512 64-bit PTEs. // A 64-bit virtual address is split into five fields: // 39..63 -- must be zero. // 30..38 -- 9 bits of level-2 index. // 21..29 -- 9 bits of level-1 index. // 12..20 -- 9 bits of level-0 index. // 0..11 -- 12 bits of byte offset within the page. pte_t* walk(pagetable_t pagetable, uint64 va, int alloc) { if (va >= MAXVA) panic("walk");
// p->lock must be held when using these: enumprocstatestate;// Process state structproc *parent;// Parent process void *chan; // If non-zero, sleeping on chan int killed; // If non-zero, have been killed int xstate; // Exit status to be returned to parent's wait int pid; // Process ID
// these are private to the process, so p->lock need not be held. uint64 kstack; // Virtual address of kernel stack uint64 sz; // Size of process memory (bytes) pagetable_t pagetable; // User page table pagetable_t kpagetable; // Kernel page table structtrapframe *trapframe;// data page for trampoline.S structcontextcontext;// swtch() here to run process structfile *ofile[NOFILE];// Open files structinode *cwd;// Current directory char name[16]; // Process name (debugging) };
// Look in the process table for an UNUSED proc. // If found, initialize state required to run in the kernel, // and return with p->lock held. // If there are no free procs, or a memory allocation fails, return 0. staticstruct proc* allocproc(void) { structproc* p;
for (p = proc; p < &proc[NPROC]; p++) { acquire(&p->lock); if (p->state == UNUSED) { goto found; } else { release(&p->lock); } } return0;
found: p->pid = allocpid();
// Allocate a trapframe page. if ((p->trapframe = (struct trapframe*)kalloc()) == 0) { release(&p->lock); return0; }
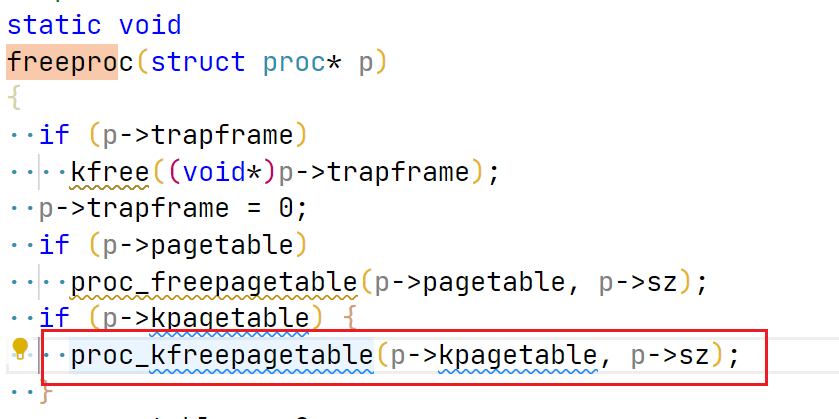
// An empty user page table. p->pagetable = proc_pagetable(p); if (p->pagetable == 0) { freeproc(p); release(&p->lock); return0; } // Create kernel page table. p->kpagetable = proc_kpagetable(p); if (p->kpagetable == 0) { freeproc(p); release(&p->lock); return0; }
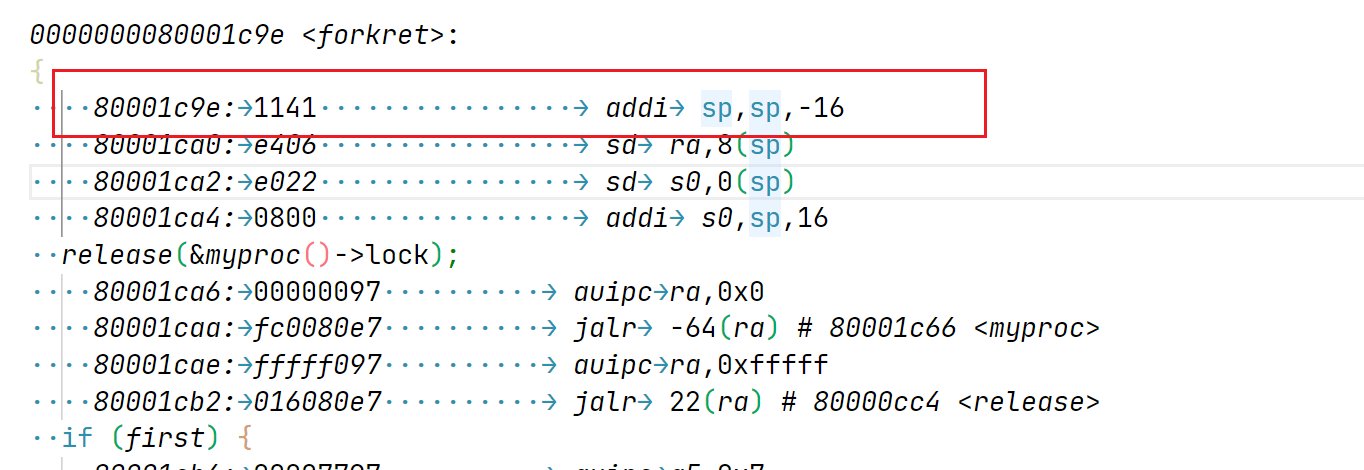
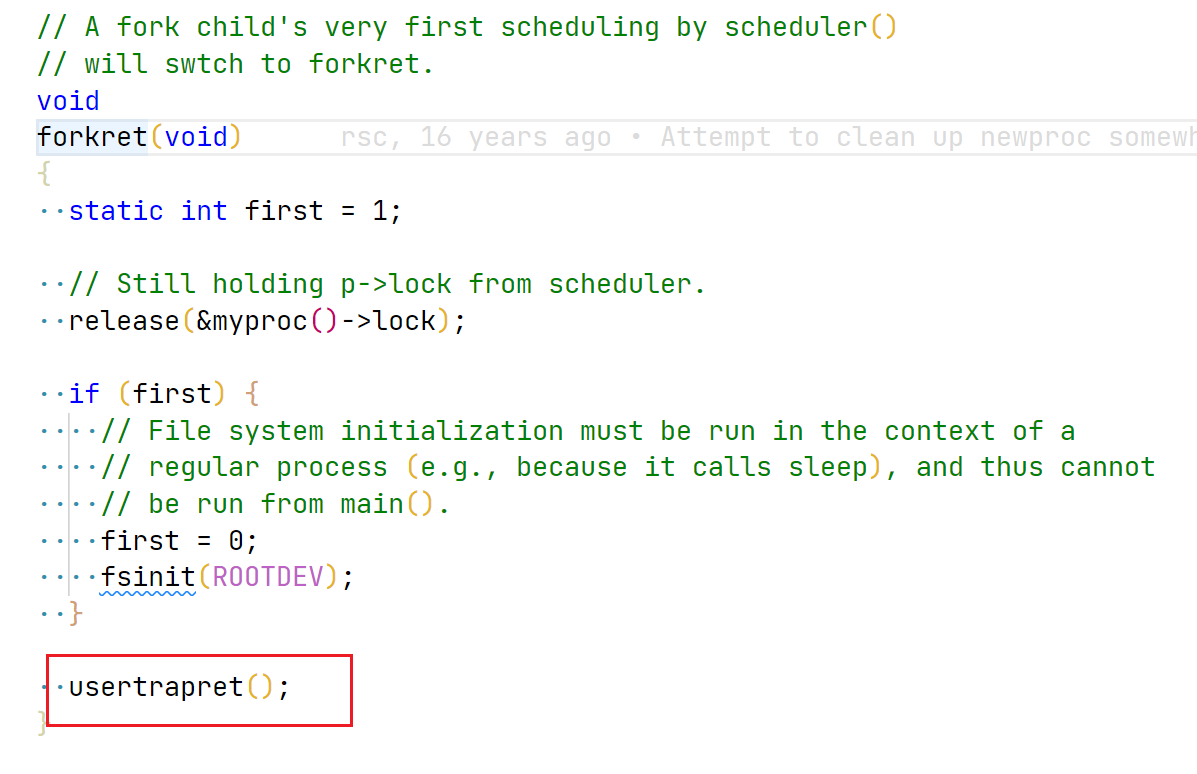
// Set up new context to start executing at forkret, // which returns to user space. memset(&p->context, 0, sizeof(p->context)); p->context.ra = (uint64)forkret; p->context.sp = p->kstack + PGSIZE;
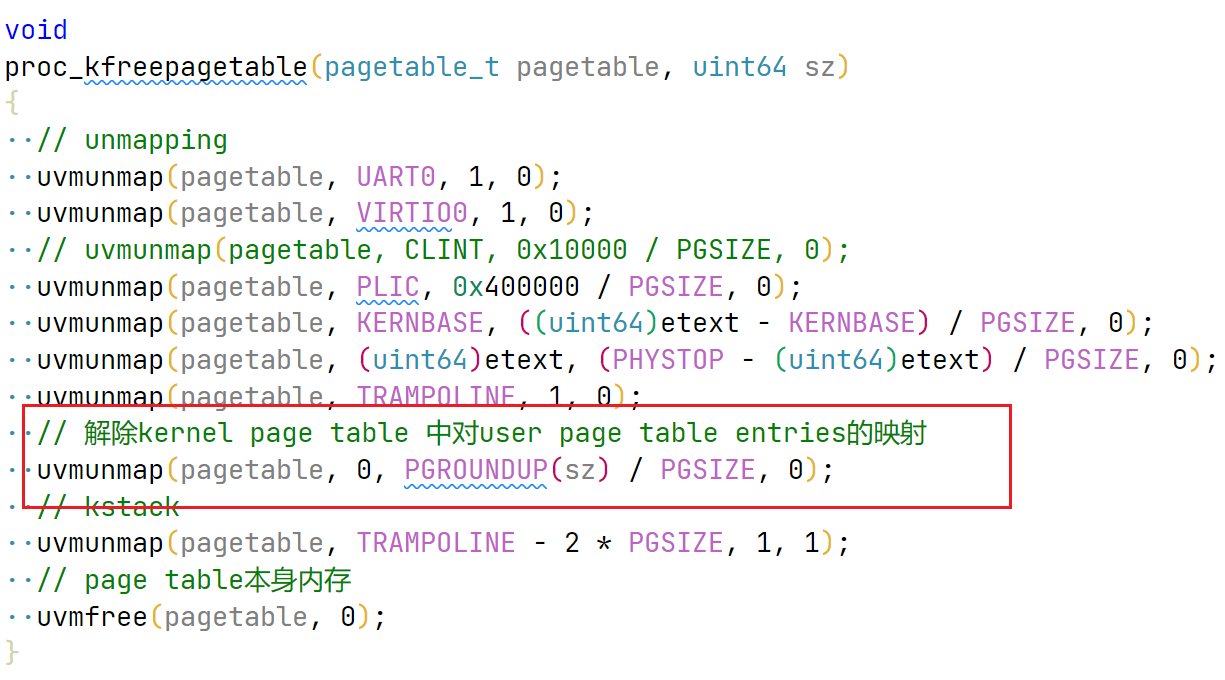
// map kernel text executable and read-only. if (mappages(pagetable, KERNBASE, (uint64)etext - KERNBASE, KERNBASE, PTE_R | PTE_X) < 0) { panic("kernel text mapping failed"); }
// map kernel data and the physical RAM we'll make use of. if (mappages(pagetable, (uint64)etext, PHYSTOP - (uint64)etext, (uint64)etext, PTE_R | PTE_W)) { panic("kernel data and free memory mapping failed"); }
// map the trampoline for trap entry/exit to // the highest virtual address in the kernel. if (mappages(pagetable, TRAMPOLINE, PGSIZE, (uint64)trampoline, PTE_R | PTE_X) < 0) { panic("kernel TRAMPOLINE mapping failed"); } }
// Per-CPU process scheduler. // Each CPU calls scheduler() after setting itself up. // Scheduler never returns. It loops, doing: // - choose a process to run. // - swtch to start running that process. // - eventually that process transfers control // via swtch back to the scheduler. void scheduler(void) { structproc* p; structcpu* c = mycpu();
c->proc = 0; for (;;) { // Avoid deadlock by ensuring that devices can interrupt. intr_on();
int found = 0; for (p = proc; p < &proc[NPROC]; p++) { acquire(&p->lock); if (p->state == RUNNABLE) { // Switch to chosen process. It is the process's job // to release its lock and then reacquire it // before jumping back to us. p->state = RUNNING; c->proc = p; load_kpgtbl(p->kpagetable); // 必须要在switch之前切换页表 swtch(&c->context, &p->context);
// 切换会内核页表? load_kpgtbl(kernel_pagetable); // Process is done running for now. // It should have changed its p->state before coming back. c->proc = 0;
found = 1; } release(&p->lock); } #if !defined(LAB_FS) if (found == 0) { intr_on(); asmvolatile("wfi"); } #else ; #endif // TODO: 也许应该将这部分移动到上面的 if(found == 0), 但是暂时未知该处作用,所以重开分支 if (found == 0) { // No running process. use kernel pagetable load_kpgtbl(kernel_pagetable); } } }
// translate a kernel virtual address to // a physical address. only needed for // addresses on the stack. // assumes va is page aligned. uint64 kvmpa(uint64 va) { uint64 off = va % PGSIZE; pte_t* pte; uint64 pa; structproc* p = myproc();
pte = walk(p->kpagetable, va, 0); // 修改为每个process的kernel page table if (pte == 0) panic("kvmpa"); if ((*pte & PTE_V) == 0) panic("kvmpa"); pa = PTE2PA(*pte); return pa + off; }
// Set up new context to start executing at forkret, // which returns to user space. memset(&p->context, 0, sizeof(p->context)); p->context.ra = (uint64)forkret; p->context.sp = p->kstack + PGSIZE;
// Copy from user to kernel. // Copy len bytes to dst from virtual address srcva in a given page table. // Return 0 on success, -1 on error. int copyin_new(pagetable_t pagetable, char *dst, uint64 srcva, uint64 len) { structproc *p = myproc();
// Load the user initcode into address 0 of pagetable, // for the very first process. // sz must be less than a page. void ukvminit(struct proc* proc, uchar* src, uint sz) { char* mem;
if (sz >= PGSIZE) panic("inituvm: more than a page"); mem = kalloc(); memset(mem, 0, PGSIZE); mappages(proc->pagetable, 0, PGSIZE, (uint64)mem, PTE_W | PTE_R | PTE_X | PTE_U); mappages(proc->kpagetable, 0, PGSIZE, (uint64)mem, PTE_W | PTE_R | PTE_X); memmove(mem, src, sz); }
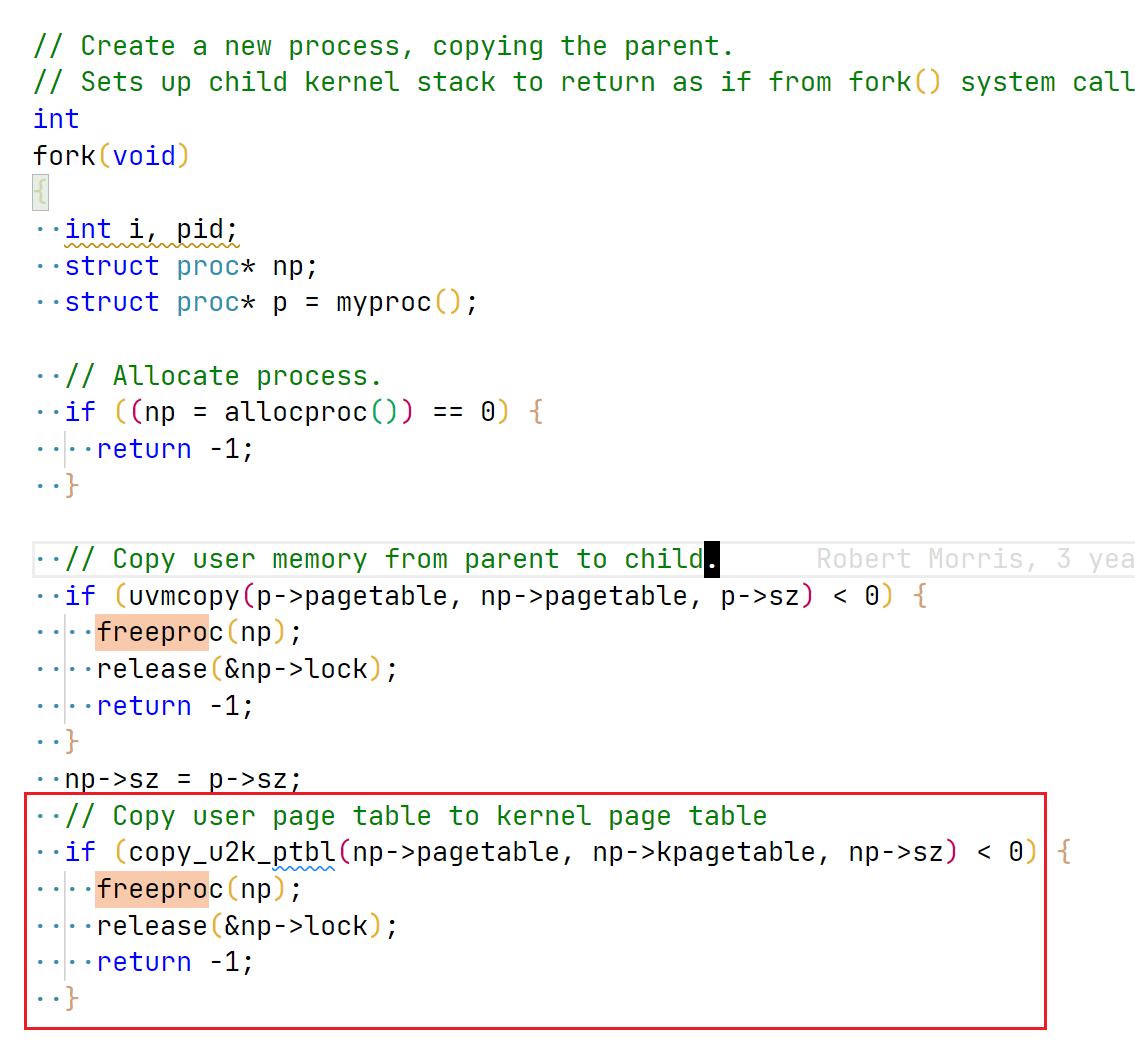
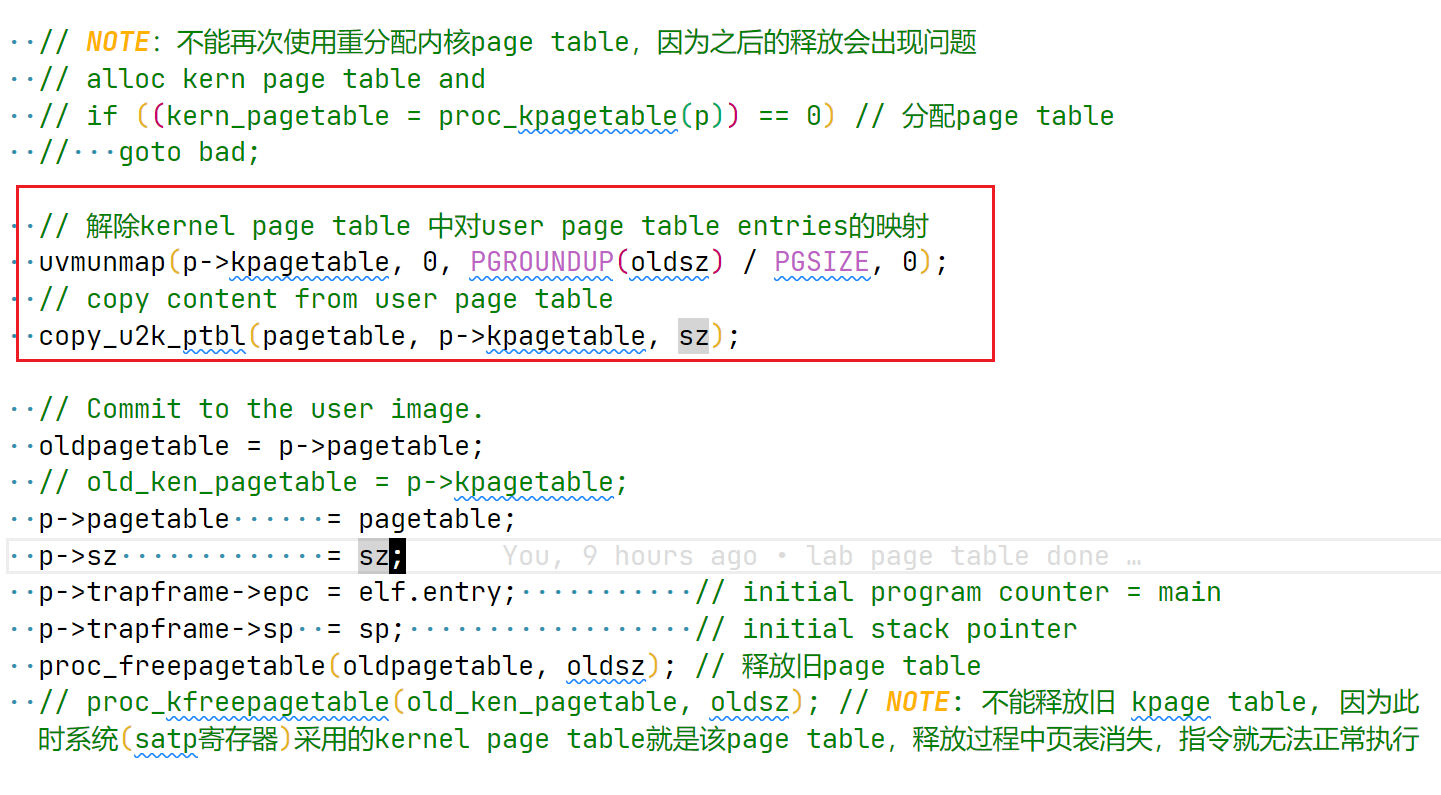
// copy `user` page table mapping to `ken` // this copying does not allocate any physical mem // while do kern page table mapping, the PTE_U will be unset // 0 means success, -1 failed // NOTE: used by fork and exec int copy_u2k_ptbl(pagetable_t user, pagetable_t ken, uint64 sz) { pte_t* pte; uint64 pa, i; uint flags;
for (i = 0; i < sz; i += PGSIZE) { if ((pte = walk(user, i, 0)) == 0) { panic("copy_u2k_ptbl: pte should b exist in user page table"); } if ((*pte & PTE_V) == 0) { panic("copy_u2k_ptbl: page not present"); } pa = PTE2PA(*pte); flags = PTE_FLAGS(*pte); UNSET_FLAG(flags, PTE_U); if (mappages(ken, i, PGSIZE, pa, flags) != 0) { panic("copy_u2k_ptbl: mappages failed"); } }
// Allocate PTEs and physical memory to grow process from oldsz to // newsz, which need not be page aligned. Returns new size or 0 on error. // NOTE: the difference between uvmalloc and this is that // in addition to map user page table, we do kernel page table mapping too uint64 ukvmalloc(pagetable_t uptbl, pagetable_t kptbl, uint64 oldsz, uint64 newsz) { char* mem; uint64 a;
if (newsz < oldsz) return oldsz;
oldsz = PGROUNDUP(oldsz); for (a = oldsz; a < newsz; a += PGSIZE) { mem = kalloc(); if (mem == 0) { uvmdealloc(uptbl, a, oldsz); kvmdealloc(kptbl, a, oldsz); return0; } memset(mem, 0, PGSIZE); if (mappages(uptbl, a, PGSIZE, (uint64)mem, PTE_W | PTE_X | PTE_R | PTE_U) != 0) { kfree(mem); uvmdealloc(uptbl, a, oldsz); kvmdealloc(kptbl, a, oldsz); return0; } if (mappages(kptbl, a, PGSIZE, (uint64)mem, PTE_W | PTE_X | PTE_R) != 0) { panic("ukvmalloc: mapping kernel page table entry failed"); // kfree(mem); // uvmdealloc(pagetable, a, oldsz); return0; } } return newsz; }
// Deallocate user pages to bring the process size from oldsz to // newsz. oldsz and newsz need not be page-aligned, nor does newsz // need to be less than oldsz. oldsz can be larger than the actual // process size. Returns the new process size. uint64 uvmdealloc(pagetable_t pagetable, uint64 oldsz, uint64 newsz) { if (newsz >= oldsz) return oldsz;
if (PGROUNDUP(newsz) < PGROUNDUP(oldsz)) { int npages = (PGROUNDUP(oldsz) - PGROUNDUP(newsz)) / PGSIZE; uvmunmap(pagetable, PGROUNDUP(newsz), npages, 1); }