最近在读《深入理解分布式系统》,书中所描述的Multi-Paxos个人觉得不太好理解。本文结合书和网络上的资料,记录下Paxos的基本流程。
1. 共识(Consensus)?·
Paxos本质上就是一种分布式共识算法。那什么是共识?在分布式系统中,共识表示的是系统内可能出现任意故障的多个节点对某个值达成一致。
那为什么需要达成共识?
因为分布式系统存在诸多问题需要解决,包括不限于网络问题(延迟、丢包,重传等)、节点故障(节点可能因为任何原因出现临时故障(在有限时间内可恢复服务)或永久故障)和时钟不一致问题(分布式系统各节点的时钟不一致)等等。通常,可以使用 **状态机复制 **来解决这些问题。 状态机包括一组状态、输入、输出、转换函数、输出函数和初始状态,给定一个状态机,具有相同初始状态的不同节点,从头开始走状态机,最终一定会得到相同的结果。 可以把从一个转换到另一个状态需要做的动作看做一条日志,走状态机即回放一条条这样的日志。 如何做状态机复制即为如何让系统中各个节点都具有相同的状态机日志。 分布式共识可以解决“让所有节点都持有相同的状态机日志”问题。如下图:
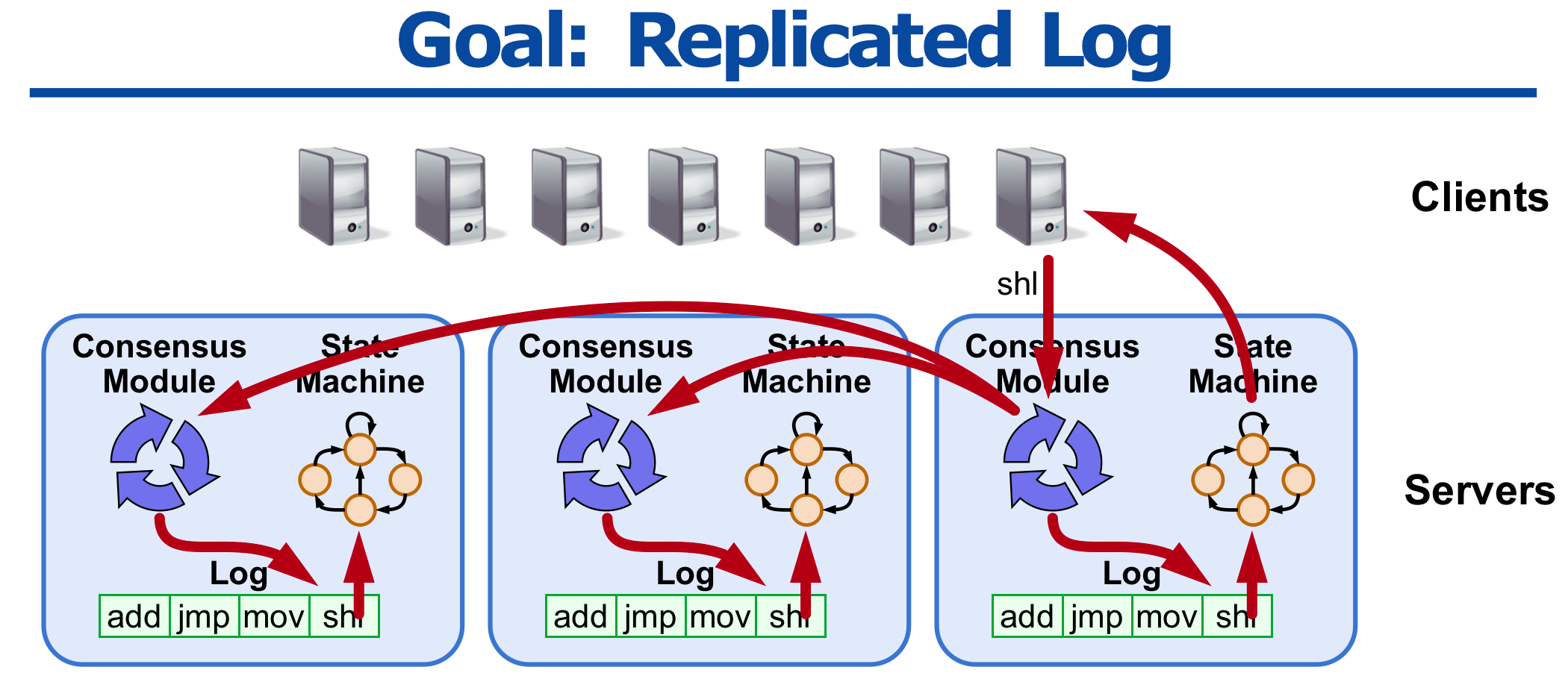
Client 发起执行shl指令的请求,为了让所有servers都按照严格顺序执行client发起的请求。接收请求的server的共识模块会将shl发给其他server, 并通过共识算法达到一致,生成日志,之后,server上的状态机执行模块会按序执行日志,执行完成后,回复client。显然只要初始状态和日志一致,各server最终的状态也是一致的。
Paxos是实现上述目标的一种算法,值得一提的是Paxos是非拜占庭容错的,即不允许系统内的节点出现“叛徒”,篡改消息通信的消息。
2. Paxos算法·
学习Paxos算法可以分为两部分:
-
Basic Paxos
Basic Paxos的目标如下:
- 允许一个或多个server 提出提案(proposal, 什么是proposal,下文会说)
- 整个系统最终仅允许单个value被批准(chosen,什么是chosen下文会说)
-
Multi-Paxos
将多个Basic paxos实例结合起来,即可以形成状态机log
让我们先从Basic Paxos开始。
1. Basic Paxos·
Basic Paxos算法中,系统中节点可以分为如下几个角色:
- Client:客户端向分布式系统发送一个请求,并等待响应。
- Proposer: Proposer可以接受来自Client的请求,并 提出相关的Proposal, 试图让Acceptor接收Proposal, 系统中可能出现多个Proposer,所以在发生Proposal 冲突时,Proposer还需要进行协调。
- Acceptor:投票接收或拒绝Proposal。
- Learner:Learner仅能学习Proposal,不能参与到决议中。
值得一提的是,系统中的各个节点都可以同时充当多个角色,如一个server可能既是Proposer也可能是Acceptor。
简述下上述角色在Basic Paxos中的位置: Client可以向Proposer发起请求,Proposer收到请求后,广播该请求到其他Acceptor中(提出Proposal),Acceptor接收到该请求后,根据一定条件,选择接收或拒绝该Proposal,回信给Proposer,Proposer如果收到半数以上的接受回信,认为该Proposal通过(被Chosen),然后回信给客户端,同时,一旦某个提案(proposal)被chosen后,learner就可以学习到proposal。
下面我们一步步补全上述流程的细节。
模型推导·
单Acceptor·
首先,假想系统中有多个Proposers,单个Acceptor:
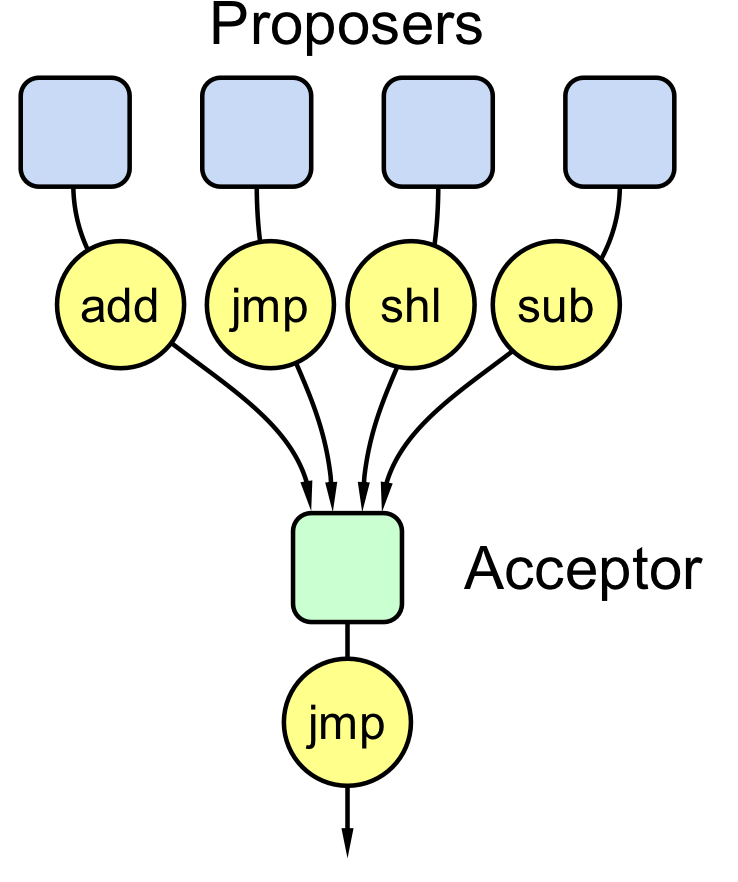
上述模型只要单个Acceptor决定接收提案,该提案就通过。但是在分布式系统中,故障是家常便饭,一旦Acceptor故障,整个系统将变得无法使用,显然单Acceptor行不通。所以需要多个Acceptors,多个Acceptor中,只要半数以上的Acceptor接受提案即可持续推进算法,这样即使有Acceptor故障,系统仍是正常的。提高了可用性。
但这样带来了新问题:由于多个Proposer并发提出提案,Acceptor们该选择接受哪个提案?
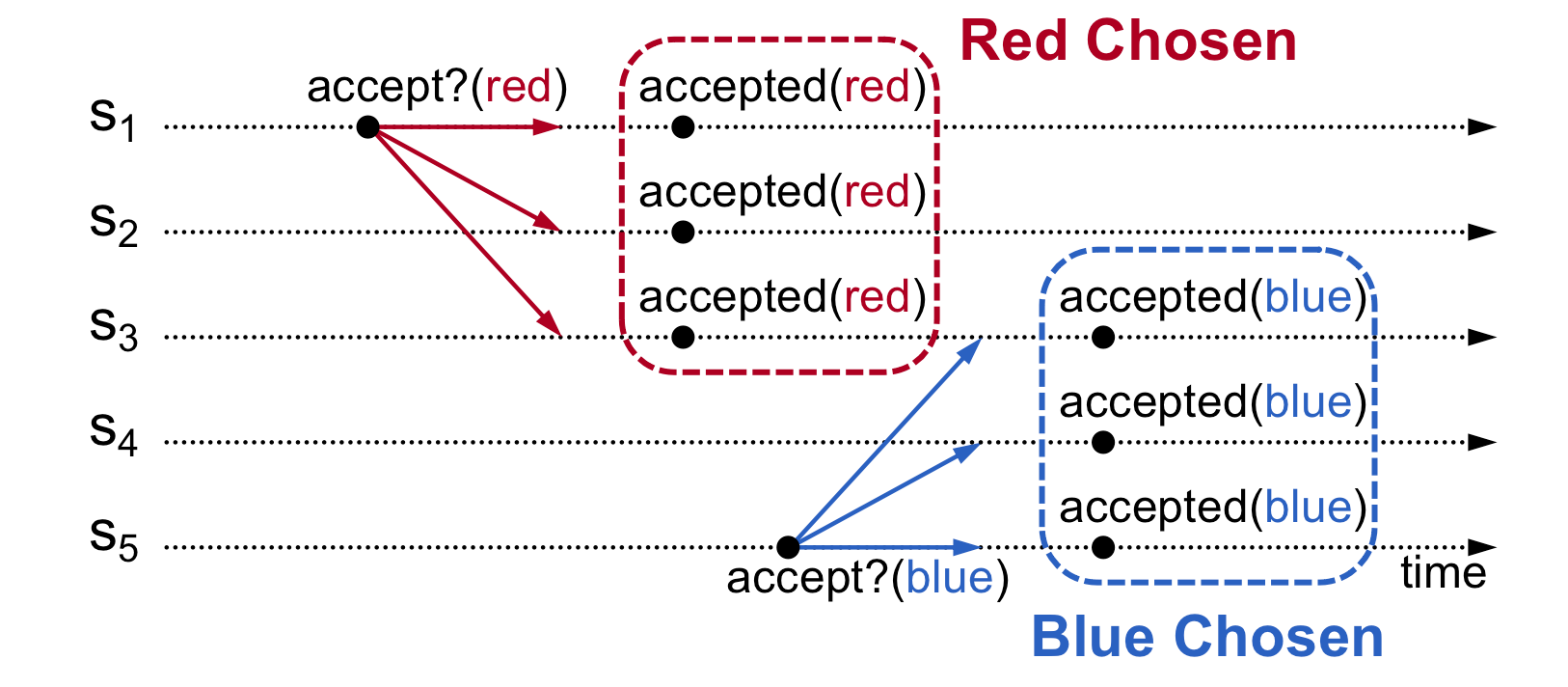
多Acceptor,只接受首先达到的提案·
一种很直观的想法是每个Acceptor只接受收到的第一个提案,拒绝之后所有的提案。不过这种会带来Liveness问题,即整个系统可能在运行但是无法就某个value达到共识(没有value被chosen)。如下图:

系统共有5个server,S1、S3和S5分别同时提出了red、blue、green三个值,S1 S2接受了red, S3 S4接受了blue,S5接受了green。而系统能决策一个value是需要超过半数的acceptor回复接受的。但在这种情况下,无法达成共识。显然acceptor需要能接受多个value,来解决这种问题,这样系统一次没有决策出,还可以重试。
又有新问题:既然多个acceptor可以接受多个value,那接受哪一个?
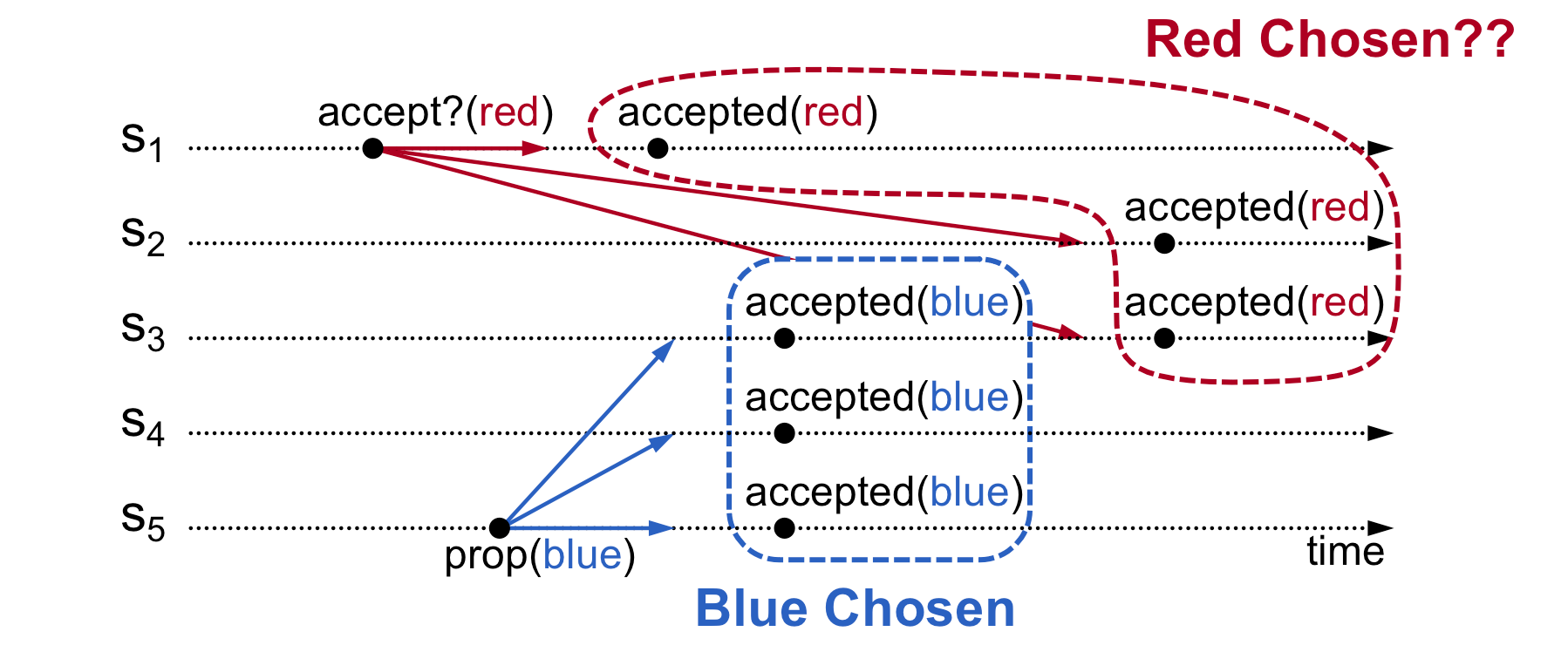
多Acceptor,接受收到的每个请求·
一种可能的情况即所有Acceptor接受其收到的所有proposal。但考虑如下场景:
S1和S5是proposer,全员都可以是acceptor。S1首先提出提案,并得到了S1 S2 S3的接受回复。系统认为red被chosen。由于S5并不知道red已经被chosen了,S5继续提出自己的提案,这次S3 S4 S5同意提案。系统又认为blue被chosen。显然这违背了Basic Paxos的目标:整个系统只有一个value会被chosen。出现这种问题的原因有两个:1. S5不知道系统中已经有被chosen的value;2. S3 之前已经接受了一个提案(red),又接受了blue提案。
为了解决上述问题,我们需要一种两阶段的协议,即单轮通信是不能解决上述问题的。首先尝试解决问题1(新proposer不知道有被chosen的value),在第一阶段的通信中,S5可以去问其他节点:“是否有提案已经被chosen过了?”,这样S5就有机会知道系统是否有被chosen的value了,从而不会提出blue提案了。
但是仅是这样就足够了吗?继续看下面的case:
S1提出red提案后,在acceptor回复前,S5也提出了提案,这样即使使用两阶段协议,依然无法达成“整个系统仅有一个value被chosen”的目标。因为其他节点采用的是 “接受收到的每个请求” 策略。所以仍需设计一种策略,让acceptor不能无脑接受收到的每个提案。为了解决这个问题,Paxos中为每个提案都做了编号:如果还没有value被chosen过,acceptor只接受具有最大编号的提案。如上case,假设S1 red提案的编号为1, S5 blue提案的编号为2, 那么S3一旦接受了blue,记录下当前接受过的最大的提案编号为2,之后接收到red提案时会直接拒绝掉。
提案编号策略(Proposal Numbers)·
如何进行编号?Paxos提出的一种策略为:

每个提案的编号由两部分组成,低位为节点id,高位为round number,节点内记录当前所使用到的最大Round Number,记为maxRound 。提案编号需要保证单调唯一, maxRound是需要持久化的,为了应对掉电重启的情况。
生成提案编号的规则如下:
- 增加maxRound
- 将其和server id结合
两阶段协议·
在“多Acceptor,接受收到的每个请求”小结中,提到需要使用两阶段协议,现在看看两阶段的详细设计:

1. Phase 1: Prepare阶段·
Prepare阶段的目标有两个:
- 找到系统中已被chosen的value(如果有的话)
- 拦截还未被chosen的老的proposals
Proposer收到client的请求后,生成一个提案编号,并向所有(或超过半数的)Acceptor广播Prepare消息, 该流程中仅需发送提案编号,不必带上提案值。
Acceptor收到该请求后,比较提案中的提案编号n与当前记录的曾经收到的最大的提案编号(minProposal)。如果n > minProposal, 更新minProposal,承诺不会接受任何编号小于n的提案(用于实现目标2),返回 Promise 消息,同时如果本节点曾经有value被chosen过,Promise消息中带着该值和接受该值时的编号;否则,忽略该请求,回复消息。
如上过程中的minProposal、acceptedProposal和acceptedValue都需要持久化。
2. Phase 2: Accept阶段·
Proposer收到Promise消息后,如果发现带有有效的acceptedProposal, acceptedValue,则使用返回的acceptor中具有最大的acceptedProposal对应的acceptedValue作为本轮的value发起Accept请求;否则,可以使用任意值作为value(通常为符合client请求的value)发起请求。
值得注意的是,Proposer Prepare阶段发给的Acceptor不一定和Accept阶段的Acceptor完全一致。因为只要满足超过半数的条件,那么本轮和第一轮一定是有重叠的。
Acceptor收到消息后,比较n与minProposal的大小,如果n < minProposal,拒绝此次提案 ,带上minProposal (解决目标2) ;否则,更新 acceptedProposal , acceptedValue 和 minProposal 。返回成功消息给Proposer。
值得注意的是,Acceptor如果决定接受提案,一定需要更新acceptedProposal,acceptedValue和minProposal。
Proposer收到Acceptor的回复后,检查如果任一返回消息中有提案编号大于自己的编号,则从prepare阶段重试,如果超过半数的acceptor回复接受,则本提案通过(chosen)。
值得一提的是,accept和chosen是两个概念,accept描述的是Acceptor认为某个提案可以接受,chosen是Proposer收到了超过半数的Acceptor的同意。
如上即为整个Basic Paxos算法流程,可以看到还是相当简单的。下面通过举例来看下它能解决哪些场景的问题。
举例·
1. 曾经有提案被批准(chosen)·
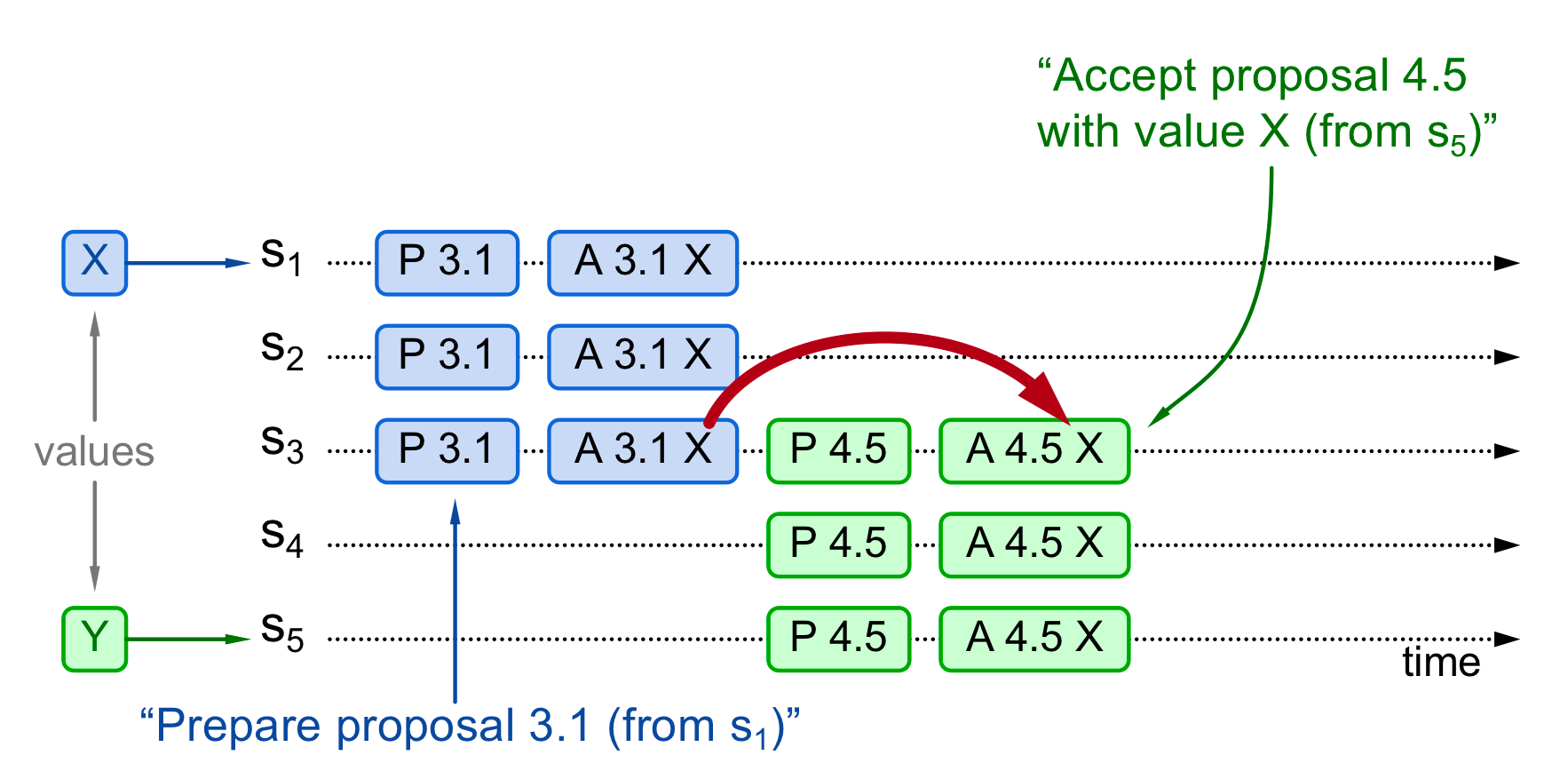
S1提出的X在提案编号为3.1时被chosen过,当S5提出Y的提案时,在其Prepare阶段,由于S3接受了3.1 X,Promise消息中会带上3.1和X。 S5发现返回消息中带上X,Accept阶段将提案值更改为X。 最终系统仅X被chosen,所有节点就X也达到了共识。
2. 曾经有提案被accept还未chosen,新提案者可以感知到该值·
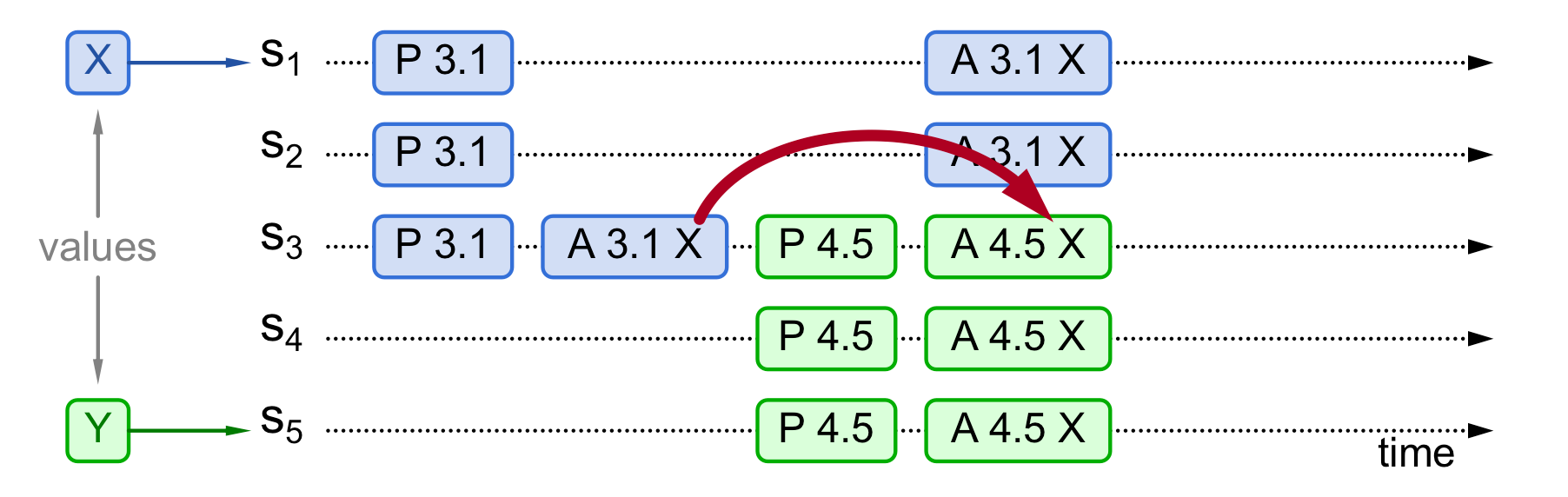
提案X在S3上通过了accept,但还未收到超过半数的同意,未被chosen。新提案Y在Prepare阶段,S3返回了X,S5发现X,替换想要提案的Y为X,继续发起accept请求。最终整个系统仅X被chosen。 S1 和 S2可能accept到X也可能没有accept到X。
3. 曾经有提案被accept还未chosen,新提者无法感知该值·
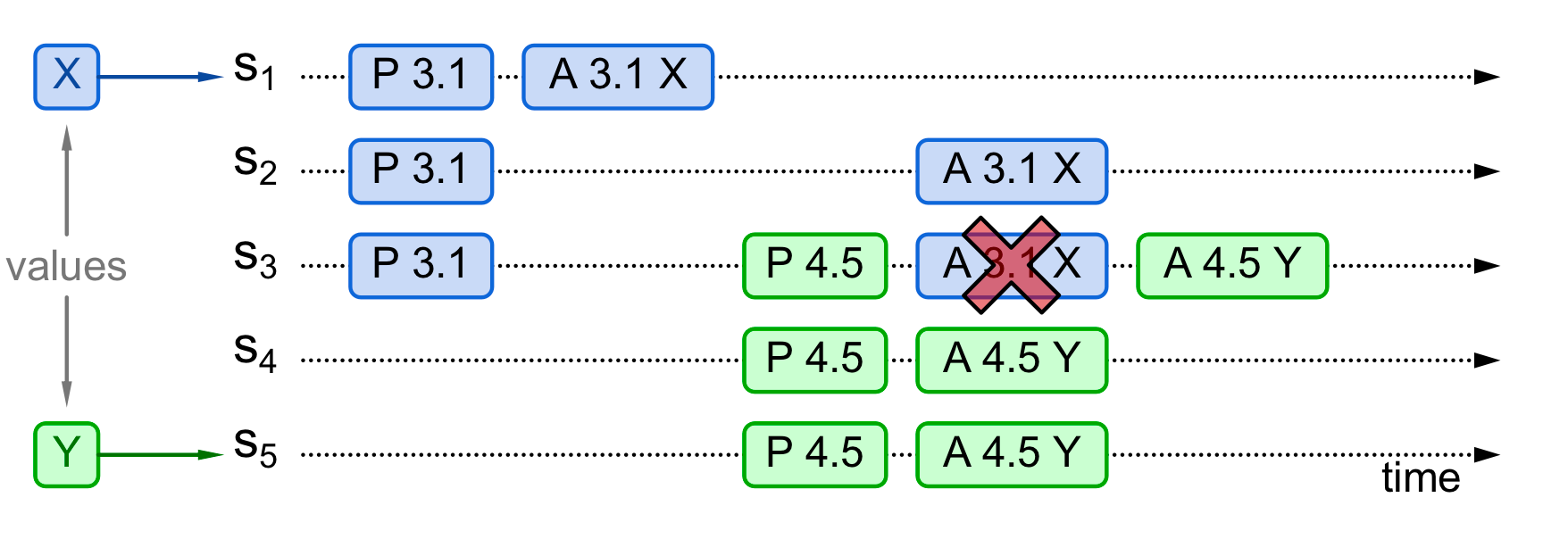
如图,3.1 X仅在S1上被accept, S5提案Y时,Prepare仅发送给S3 S4 S5,这三个节点没有X被accept的信息,于是S5认为曾经没有值被accept,继续使用Y accept,S3 S4 S5通过该提案。 对于老的提案 3.1 X, 由于其编号小于 4.5 ,被拦截了。 最终整个系统仅Y被chosen。
Liveness 问题·
就举例case 3而言,出现了“一个提案被另一个提案拦截”的情况,这是由于采用了两阶段协议的问题。于是可能出现如下case:
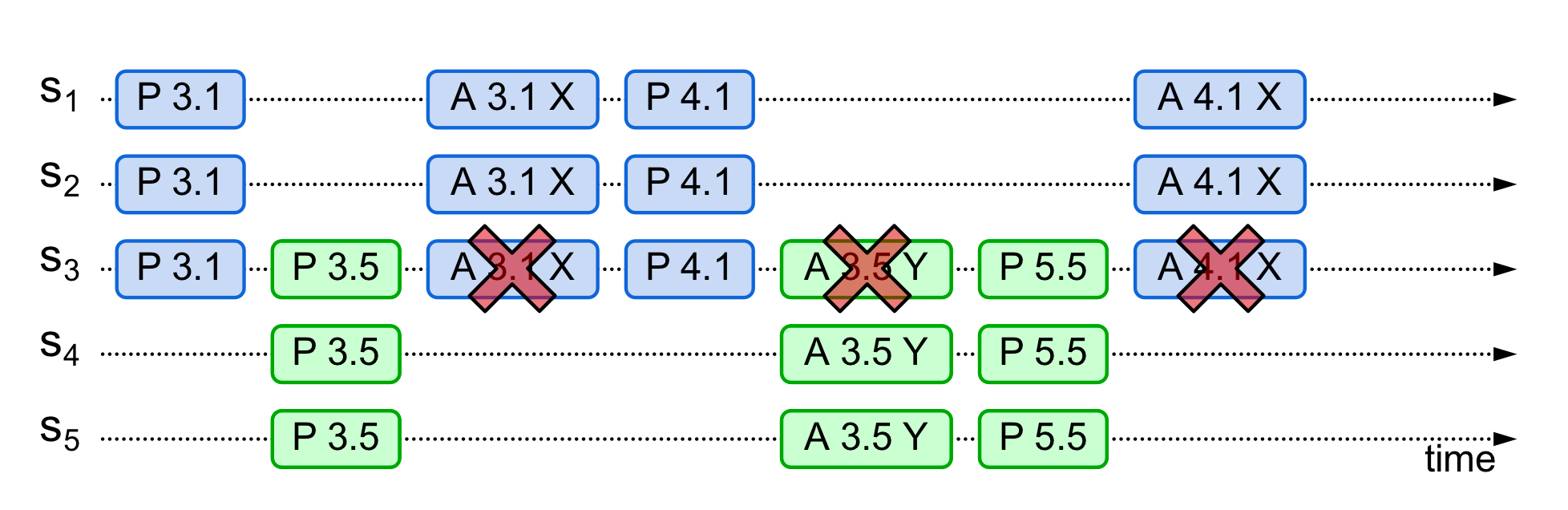
S1提出3.1 提案,被S5的3.5提案拦截,3.5发起Accept请求时,S1由于发现提案被拒绝,增加提案编号为4.1并重试,该请求先于3.5的Accept请求到达S1 S2 S3,所以S5的3.5提案被拒绝,整个系统持续演进,最终导致整个系统持续运行,但是永远达不成公式。
一种简单有效的解决方式是增加随机延迟,当proposer发现提案被拦截后,增加一段延迟,让其他proposer可以通过提案。
Basic Paxos的问题·
问题1:Paxos中仅有Proposer知道哪个提案被chosen了,其他节点如果想要知道被chosen的value,必须要自己提出议案才能感知。
问题2:每个提案都必须经过Prepare + Accept两个阶段,当系统内存在多个Proposer时,冲突上升,系统内rpc消息将有很多,性能低下(即使只有当个Proposer,如果存在多个Baisc Paxso实例,冲突依然严重,具体见下文 Multi Paxos)。
问题3:Basic Paxos仅能解决单个值的共识,要形成replicated log,需要就多个值达成共识。
为了解决这些问题,提出了Multi-Paxos。
2. Multi Paxos·
一次Basic Paxos run能够决定一个value,那么如果运行多次Basic Paxos算法,就可以决定多个value,形成日志,从而实现状态机复制。我们把每次决定单个value共识的运行称为一个Basic Paxos实例。
1. 选择日志索引·
显然,不能允许多个Basic Paxos实例随意运行,因为要保证每个Server的日志完全一致,不能说Server 1上的日志为1 2 3, 而Server 2上的日志为1 3 2,这样虽然实例决定出的值都为1 2 3, 但是顺序不一致。为了解决这个问题,需要为每个Basic Paxos实例所决策的value在日志中的位置添加index。
新的问题是如何为每个实例选择日志索引? Paxos采用如下规则:
- 找到第一个没被chosen的log entry所在的位置,记为index;
- 运行Basic Paxos算法,对client的请求进行提案(Prepare + Accept)
- Prepare阶段返回了acceptedValue?
- Yes。用该值做Accept,回到第一步。
- No。用提案值作为value做Accept。
举个例子:
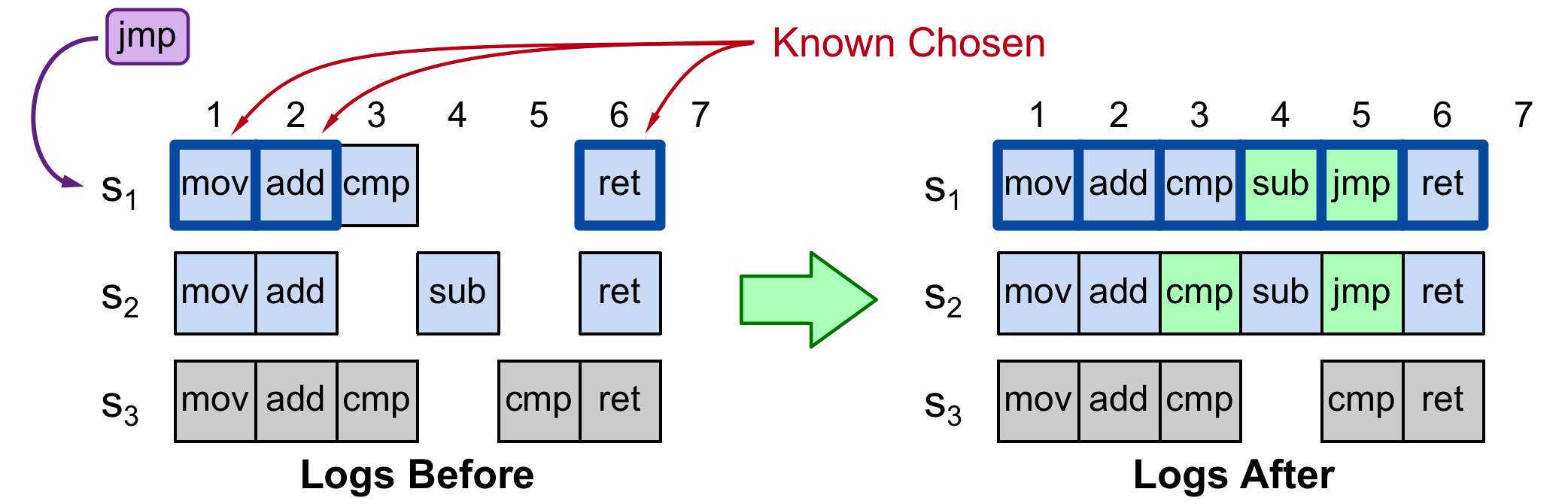
假设有3个Server,其中S1接收client的请求,S3故障失联(假设其能接收rpc,但是不能回复rpc)。索引1 2 6为被chosen的value(因为日志在超过半数的地方都有,且S1能感知),3 5之所以不能认为是被chosen,因为S3处于失联状态,S1无法感知。
Step 1: 找到第一个未被chosen的日志索引,3。
Step 2: 使用Basic Paxos算法,广播到S1,S2,S3(S3不能回复)。
Step 3:S1的Promise回复中带有acceptedValue cmp, 故采用cmp做Accept。
Step 4: S2的index 3得到cmp补全。
Step 5: 回到Step 1重试,发现index 4,补全了S1的index 4为sub。
Step 6: 回到Step 1重试,发现index 5, 由于S1和S2上都没有acceptedValue。所以此次提案成功,index 5为用户请求中的jmp命令。
值得注意的是,Proposer(即S1)可以并发接收多个client的请求,由于它能感知3 4 5 7都没有acceptedValue,于是可以并行处理请求,将请求分别对应到这四个slot中。但是,日志只能被顺序apply。
至此,我们解决了[Basic Paxos的问题](#Basic Paxos的问题)小节中的问题3。
2. 领导者选举·
由于一个集群内可能存在多个Proposer,这些Proposer可能相互冲突(比如前文提到的 [Liveness 问题](#Liveness 问题) ),可以通过选领导者,让集群内仅有一个Proposer来避免冲突。如果领导者故障,重新选取即可。
如何实现领导者选举?Paxos论文中提的方法为:
- 使用具有最大Server Id的server作为领导者。
- 每个节点每隔T ms发起心跳来交换server id信息。
- 如果节点超过2T ms未收到比自身更大的server id心跳,自身转变为leader(即集群内的proposer)。
- 如果一个节点不是leader,当其收到client的请求时,要么放弃该请求,要么重定向到集群内的leader。
算法很简单,但可能存在两个问题:
- 无法准确保证集群内只有单个leader,比如出现网络分区,两个分区内各有自己的leader。但是不影响算法正确性,因为Basic Paxos本身就容忍多个Proposer的存在。
- 由于集群内每个server上的log不是完全对齐的,有些节点可能因为故障了比较久,重启后日志落后较多,重新补齐需要一些时间。如果这个节点刚好是server id最大的节点(即leader),那么补齐日志期间无法提供服务。 (Raft算法解决了该问题,因为它选择了日志最新的作为leader)。
至此,解决了Proposer们之间的冲突,但是单个Proposer仍需对每条log都发起2次rpc,仍有可优化的空间。
3. 减少Prepare阶段·
一次Basic Paxos Run需要两次RPC:Prepare和Accept。 有没有办法减少Prepare?先来思考下Prepare阶段的作用:
- 如果系统内存在多个提案,Prepare可以屏蔽老的提案。
- Proposer通过Prepare感知系统内是否有已经accepted的值,如有则替换自己的提案值。
先看第1点,原Prepare阶段可以屏蔽一个log index上的老提案,每个log index都需要prepare。为了避免每个log index都prepare,可以将提案编号按照整个log单调递增。acceptor只用记录一个minProposal(而不是每个log index一个),后续各个log index的Prepare请求(如果需要的话)只用和这个minProposal比较即可。
再看第2点,Prepare返回阶段时,Acceptor要返回两个信息: 1. 对于当前log entry(idx),如果有acceptedValue,返回minProposal 和 acceptedValue; 2. 增加一个标识noMoreAccepted,标识从当前log idx开始,往后查看本节点是否有accepted的value,如果没有,该标识为true,如果有,该标识为false。当Proposer收到来自Acceptor的noMoreAccepted标志为true时,之后对该Acceptor不再需要发起prepare请求, 当Proposer收到超过半数以上的noMoreAccepted,则之后整个log都不需要发送Prepare请求(除非换了leader,或者因为某种原因存在多个leader(proposoer))。
通过如上两个优化,即可以减少大量的Prepare请求。至此,我们解决了 [Basic Paxos的问题](#Basic Paxos的问题)中的问题2。
4. Chosen entry感知&全log replication·
前文提到,Basic Paxos只有Proposer能感知chosen的value,其他Server如果想要感知,必须自己发起Proposal。而上述的Multi-Paxos中也存在这个问题,此外,由于Paxos仅需“超过半数”的人同意提案,提案就被chosen。试想一个场景,S1 S2 S3 S4 S5, 系统开始run之前, S4 S5由于网络分区不参与整个提案过程,那么理想情况下仅有S1 S2 S3上有全量log。 当网络分区治愈后,S4 S5缺乏所有log,如何补齐这些log呢?
可以加上如下4种解决方案:
Solution 1:proposer在后台不停重试,直到所有acceptor都响应了请求;
Solution 2:为每个server增加 acceptedProposal数组。acceptedProposal[i]表示log entry[i] 被accepted时的提案编号。特别地,如果acceptedProposal[i]=∞,则认为该log entry被chosen。此外,为每个server增加firstUnChosenIndex变量,表明该server上第一个没被chosen的index,即扫描acceptedProposal数组,firstUnChosenIndex=第一个acceptedProposal[i] != ∞的位置。
Solution 3: Proposer告诉Acceptor chosen的entries。具体方法如下:
- Proposer在Accept RPC阶段,带上自己的firstUnChosenIndex
- Acceptor收到Accept请求后,找到log index中所有 i < request.firstUnchosenIndex 并且 acceptedProposal[i] == request.proposal的entry,将他们的acceptedProposal[i]=∞(即认为被chosen)
举个例子:
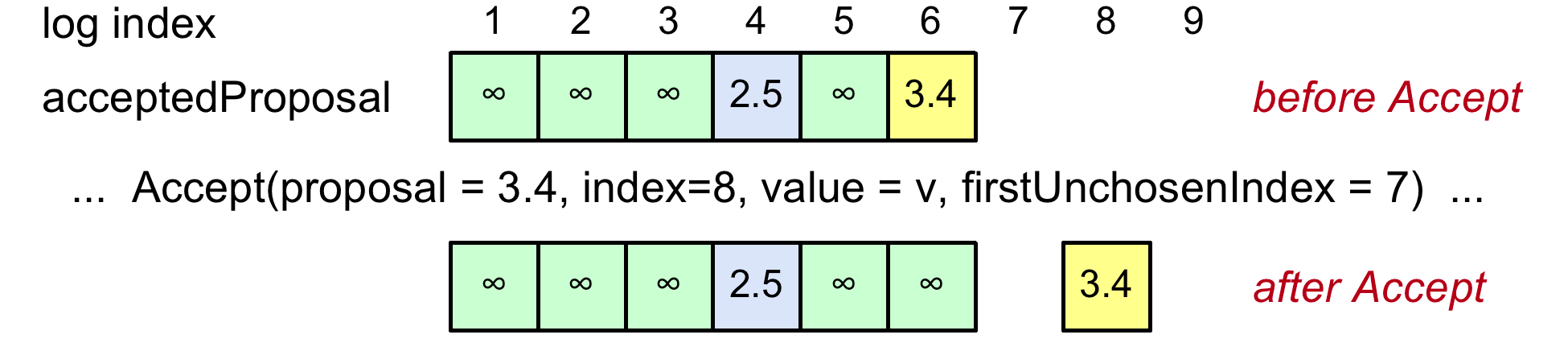
起始时, 1 2 3 5被chosen, 4来自2.5,6来自3.4。现Acceptor收到proposal =3.4 index = 8, value =v , firstUnchosenIndex = 7. 首先因为 entry 8的proposal number=3.4, 整个log中的最大的proposal编号也为3.4,所以在entry 8上accepted value = v; 其次,firstUnchosenIndex = 7,查看4和6 log entry, 由于4的proposal number 2.5 !=request中的3.4, 所以无法chosen它。6处的3.4 = 请求中的3.4, 将其标为无穷大。
问题:条件为什么是 i < request.firstUnchosenIndex && acceptedProposal[i] == request.proposal
先看前半部: i < request.firstUnchosenIndex,因为Proposer肯定是知道哪些log entry被chosen最多的人,所以对于acceptor来说,只用看小于proposer的firstUnchosenIndex。
再看后半部: acceptedProposal[i] == request.proposal, 比如上图中的entry 4,由于2.5 != 3.4,说明entry 4处的value来自于server 5,server 5所提出的value到底有没有chosen, server 4并不知道,server 4无法越权去标记它被chosen。
现考虑“后半部”中entry 4中的2.5,如果server 5在发起过accept后,宕机了,那么acceptor永远不知道entry 4到底被chosen没有,这是无法接受的,这引出了Sloution 4。
Sloution 4:Acceptor在Accept RPC的response中,回复自己的 firstUnchosenIndex, Leader收到该响应后,检查是否 leader’s firstUnchosenIndex > acceptor’s firstUnchosenIndex, 如果成立, leader 在后台通过Success RPC, 该请求带有将 acceptor’s firstUnchosenIndex 对应的value发给acceptor,acceptor收到后,即可更新 acceptor’s firstUnchosenIndex 处的log entry value, 并将对应acceptedProposal标记为无穷大,接着继续返回下一个 firstUnchosenIndex 给leader。如此重复。
通过如上Solution,其他server可以感知被chosen的value有哪些,同时全log replication可完成。
至此,我们解决了 [Basic Paxos的问题](#Basic Paxos的问题)中的问题1。
5. 客户端协议·
客户端协议包含:
寻找leader:客户端第一次启动时,并不知道leader是谁,所以此时client可选择任一server发起请求,如果该server为leader则处理,否则由该server告诉client谁是leader。client知道谁是leader后,记录下来,后续的请求即可直接发给leader。
请求超时:如果client发起请求超时(可能是网络问题,leader故障等等),client可以重新发起该请求。而重试可能会带来新问题,由于client请求的操作可能不是幂等的,站在client角度,只希望自己发起的请求成功一次。现考虑client共发起两次请求(第二次为重试),第一次超时,但实际成功,第二次为重试也成功,那么相当于一个请求操作了两次。为了解决该问题,client需要为每次请求带上一个unique id,server侧将每个请求的id记录在log中,状态机在apply过程中可以检测该条log对应的请求是否已经处理过,如果处理过直接忽略该log,否则执行即可。
6. 配置更改·
一个分布式集群,可执行扩容、缩容,节点替换等改变集群成员组的操作,而对于Paxos算法来说,如果集群内节点数发生改变,其Quorum(超过半数的机制)将会改变。比如扩容前,集群仅有3个节点,超过半数即超过2, 而扩容后集群节点数量为5, 超过半数就变成了3。如果不小心处理,整个系统可能变得不一致。
比如现在发起一次Basic Paxos, s1作为proposer认为系统只有3个节点 s1 s2 s3; s5作为proposer则认为系统有5个节点s1-s5。s1以v1作为提案,收到了s1和s2的接受回复,此时s1 chosen了v1。 而s5以v2作为提案,收到了s3 s4 s5的接受回复,chosen了v2。 这显然是不符合Basic Paxos的目标的:系统只能就一个value达成共识。
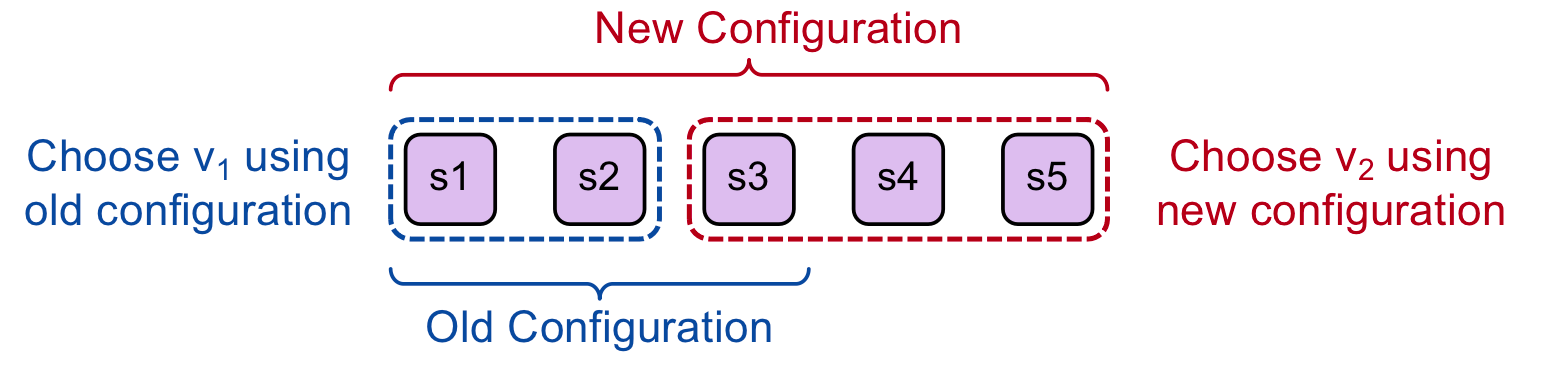
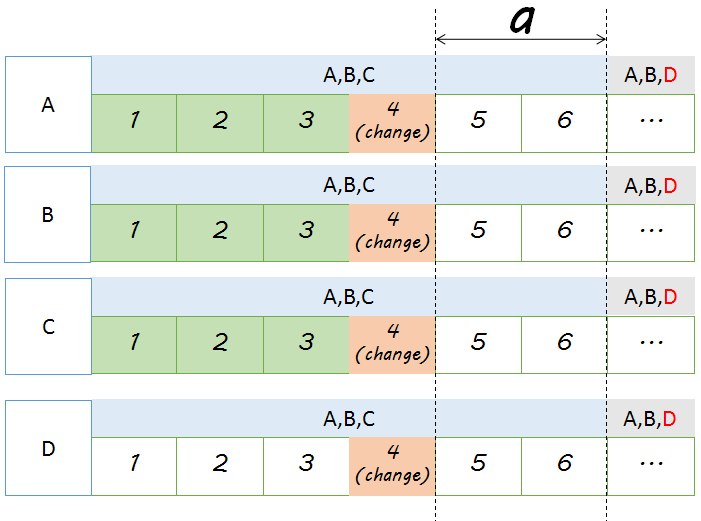
在Paxos论文中,使用日志来管理配置变更,即将一次变更作为日志存在在log中。如下图:
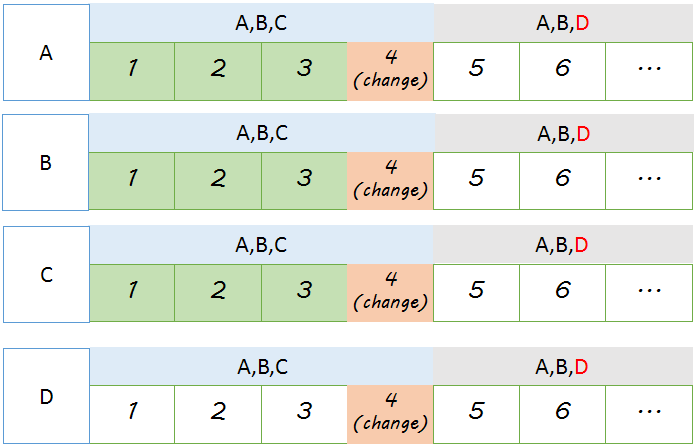
在log entry 4之后,配置改变,由原来的A B C变更为A B D。从5开始,认为变更完成。但如上示意图仅是理论实现。
由Proposer可以并发处理来自不同客户端的请求,这会带来新问题。还是上图,假设4 5 6请求同时处理,4被chosen后,5 6其实并不知道配置已经发生改变,于是它们仍然认为 A B C才是当前的成员组。为了避免这种情况发生,通常在Paxos算法中需要定义一个延缓窗口 a , 该参数的含义为配置生效点在配置被chosen的index处再加上 a 个 index。 比如 a=2 则下图配置生效点在index 7。 该参数虽然解决了各成员对成员组保持一致的问题,但也限制了Proposer能处理的并发度,因为 直到 log entry[i] 被chosen前,log entry [i+a] 无法被chosen,因为不知道 [i ~ i+a) 之间是否有配置变更的log。 所以a 变量取值很重要,过小,限制了并发度,过大,配置生效需要等很长时间。 为了加速配置生效时间, 可以加入一些nop日志。
3. 总结·
至此,本文介绍完整个Paxos算法的流程: Basic Paxos,仅就一个value达成共识,其包含Prepare 和 Accept两阶段。Multi Paxos,为对多个value达成共识,介绍了选择日志索引的方式(即第一个没被chosen的index)。为减少rpc调用次数,介绍了领导者选举和减少Prepare阶段请求;为达成full log replication,让其他server感知被chosen的log,介绍四个solution,后台不停发,acceptedProposal,firstUnchosen变量的引入,还有Success RPC。接着介绍了Client协议,为了避免重试请求造成的错误,需要为每个请求做唯一编号。最后还介绍了如何做配置变更。
4. 参考·
- 《深入理解分布式系统》
- Diego Ongaro - Paxos lecture
- Paxos理论介绍(4): 动态成员变更

