一直以来对"并发"相关的主题都蛮感兴趣的,但这一块也确实非常复杂,因为同时涉及了硬件设计和软件协议。比如再看c++ memory order时,一定见过这些词语:重排序、乱序执行,分支预测、预测执行、MSEI、volatile,内存屏障、store buffer, invalidate queue, sequential order(SC)、TSO、PSO内存模型、happens before, synchronized-with、sequenced-before、program order等等名词。作为一个非科班的开发人员,大概率是会被绕晕的。这篇文章,就来谈谈这些概念,当然最终目标是理解c++11中提出的几大常见内存序该如何使用。由于水平有限,难免出错,也希望指正。
1. 缓存一致性 – Cache coherence·
我们都知道,为了充分利用程序的locality,当前的CPU架构基本包含L1, L2, L3 cache + Memory,如下图:

暂时抛开多级cache,假设cpu之间共有一个Memory,自身有一个私有cache:

Cache coherence·
在多核架构下,针对同一个变量x,每个cpu内部cache都有可能有x的一份副本(比如每个cpu都执行 load x指令)。接着cpu0执行store x指令,即更新了x,如何保证更新x后,之后所有cpu都能读到这份更改,是本节要探讨的问题。

可以把解决这个问题的方式分为两类,一种是软件解决方式(通常需要结合compiler和os),称为Cache coherency schema。另一种是硬件解决方式,称为Cache coherency protocol. 本节仅探讨硬件解决方式。
Snooping-based Cache Coherency Protocol·
Snooping-based 方案,即各CPU的cache controller需要对共享的总线进行监测,当监测总线上有属于自身cache line的更新时,需要做出一些更新动作。根据更新动作的不同,分为两类:
- Write-update
当处理器写入Cache块时,其他Cache监听到后把自己Cache中的数据副本进行更新。该方法通过总线向所有缓存广播写入数据。它比写无效协议(另一种更新动作)产生更大的总线流量,所有这种方式不常见。Dragon和firefly属于这一类协议。

- Write-Invalidate
这是最常用的监听协议。当处理器写入Cache块时,其他Cache监听到后把自己Cache中的数据副本标记为无效状态。这样处理器只能读取和写入数据的一个副本,其他缓存中的副本都是无效的。

除了各核心内部的cache更新外,还要考虑写回到内存,根据写回内存的机制不同,又分为两类:
- write through
CPU向cache写入数据时,同时也写入memory,使cache和memory的数据保持一致。
优点是简单,缺点是每次都要访问memory,速度比较慢。但是读数据时还是能够享受Cache带来的快速优点的。
- write back
CPU向cache写入数据时,只是把更新的cache区标记一下(cache line 被标为dirty),并不同步写入memory。
只是在cache区要被刷入新的数据时,才更新memory。
优点是CPU执行的效率提高,缺点是实现起来技术比较复杂。
其中write back可以减少不必要的内存写入,减轻总线压力。现在大部分场景下,cache多采用write back的方式,本文的介绍都是基于write back的方式。
如上两两组合,共有4种 snooping-based cache 一致性协议。
-
Write-update + write through
-
Write-update + write back
-
Write-Invalidate + write through
-
Write-Invalidate + write back
MESI Protocol·
MESI协议属于Write-invalidate协议中的一种。MESI协议又叫Illinois协议,MESI,“M”, “E”, “S”, "I"这4个字母代表了一个cache line的四种状态,分别是Modified,Exclusive,Shared和Invalid。
- Modified (M)
cache line只被当前cache所有,并且是dirty的。
- Exclusive (E)
cache line仅存在于当前缓存中,并且是clean的。
- Shared (S)
cache line在其他Cache中也存在并且都是clean的。
- Invalid (I)
cache line无效,即没有被任何Cache加载。
有了状态,就可以考虑下状态之间的转换,下图是一个状态转换图:

从上图也可以看出状态转换有时是需要CPU之间互传消息的,CPU之间的沟通协议有如下几种消息体:
- Read :带上数据的物理内存地址发起的读请求消息;
- Read Response:Read 请求的响应信息,内部包含了读请求指向的数据;
- Invalidate:该消息包含数据的内存物理地址,意思是要让其他如果持有该数据缓存行的 CPU 直接失效对应的缓存行;
- Invalidate Acknowledge:CPU 对Invalidate 消息的响应,目的是告知发起 Invalidate 消息的CPU,这边已经失效了这个缓存行啦;
- Read Invalidate:这个消息其实是 Read 和 Invalidate 的组合消息,与之对应的响应自然就是一个Read Response 和 一系列的 Invalidate Acknowledge;
- Writeback:该消息包含一个物理内存地址和数据内容,目的是把这块数据通过总线写回内存里。
举个例子,现在有 cpu0 cpu1 变量a,cpu0对a赋值 a=1:
假如变量a不在cpu0 缓存中,则需要发送 Read Invalidate 信号,再等待此信号返回Read Response和Invalidate Acknowledge,之后再写入量到缓存中。
假如变量a在cpu0 缓存中,如果该量的状态是 Modified 则直接更改发送Writeback 最后修改成Exclusive。而如果是 Shared 则需要发送 Invalidate 消息让其它 CPU 感知到这一更改后再更改。
- 一般情况下,CPU 在对某个缓存行修改之前务必得让其他 CPU 持有的相同数据缓存行失效,这是基于 Invalidate Acknowledge 消息反馈来判断的;
- 缓存行为 M 状态,意味着该缓存行指向的物理内存里的数据,一定不是最新;
- 在修改变量之前,如果CPU持有该变量的缓存,且为 E 状态,直接修改;若状态为 S ,需要在总线上广播 Invalidate;若CPU不持有该缓存行,则需要广播 Read Invalidate。
给一个MESI交互网站,可以动态观察MESI协议:https://www.scss.tcd.ie/Jeremy.Jones/VivioJS/caches/MESI.htm
Directory-based Coherency Protocol·
略,本文不关心这种协议。提出该类协议的原因是因为 Snooping-Based协议依赖于总线带宽,处理器越多,消耗带宽越多,可扩展性不好。感兴趣可参考:Cache一致性的那些事儿 (3)–Directory方案
2. 内存一致性模型 – Memory Consistency·
顺序一致性模型·
作为软件开发人员,我们希望cpu在执行代码时,始终按照我们**所写的代码顺序(program oroder)**来执行。即
1 | line 1 |
在单线程下,永远都是line 1 -> line 2 -> line 3 -> line N。换成多核多线程, 希望代码依然能**“顺序执行”**:

如何理解这里的 “顺序执行”:
从每个线程自身视角来看,执行的代码流都是符合progrom order的,即对于T0来说,执行流是1,2,3;对于T1来说,执行流是4,5,6. 但是线程可以并行、交互执行。最终的执行序列无法提前知道,可以是 1,2,3,4,5,6. 可以是 1,4,2,5,6,3 也可以是 1,4,2,5,3,6。 但是绝不会是 2,1,3,4,5,6. 因为2一定在1之后。除了这个特性外,一个个线程执行流产生的作用会被另一个线程锁看到,即T0执行2处后(a=1),在之后的T1的5处一定会被观察到(print(a)为1)。
这是我们的理想内存一致性模型,这种模型也被称为 顺序一致性(Sequential Consistency)。更学术的定义为:

最终它能保证,所有操作都是ordered。
顺序一致性模型的缺点·
要实现顺序一致性,最粗暴的做法就是cpu一次只发射一个指令,等待这个指令完成后再执行下一条。但很明显这样性能太差了。下图展示了它到底有多慢:
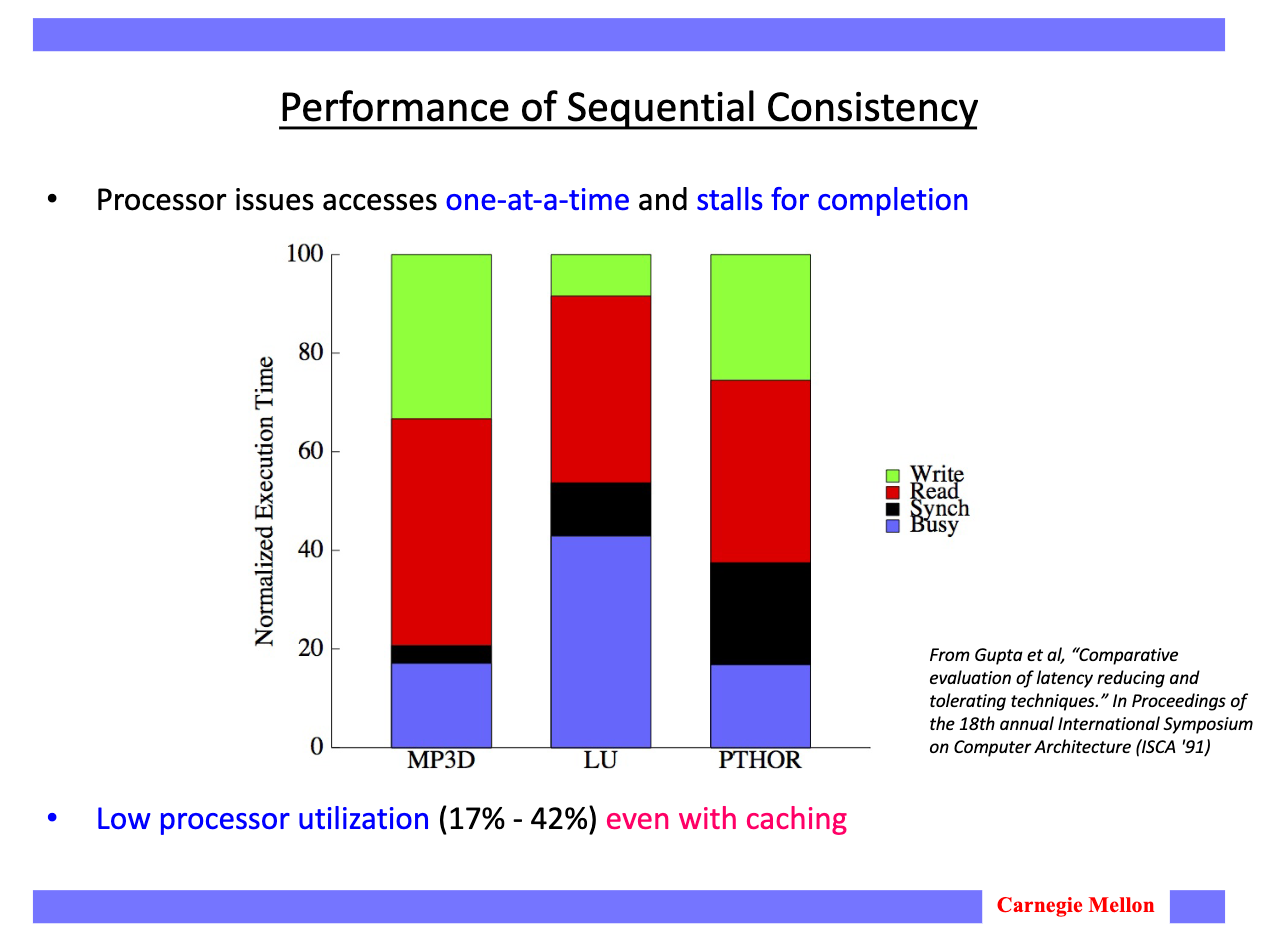
横轴是不同的应用,纵轴是cpu耗时拆分的百分比。Busy部分是指令实际生效的时间,Synch是同步开销,Read和Write分别是Read和Write的stall时间。从结论上看,如果采用这种顺序一致性模型,cpu的利用率仅17%~42%。 这当然不是硬件工程师们想要的。
其他内存一致性模型·
硬件工程师为了更充分利用CPU,选择了让软件工程师做出妥协。 即不提供严格的顺序一致性模型,放松了内存一致性模型。目前CPU主流架构上流行两种宽松一点的内存一致性模型:TSO和PSO。
Total Store Order(TSO)·
TSO主要是为了优化写操作而设计的。想象一下,系统上电后,cache内没有任何东西,cpu要执行 a = 1: 首先要从内存里将a的值缓存在cache中,再执行写操作。 比较下这里的cpu执行时间和从内存中取值时间, 下图是Jeff Dean给出的一些经验值:
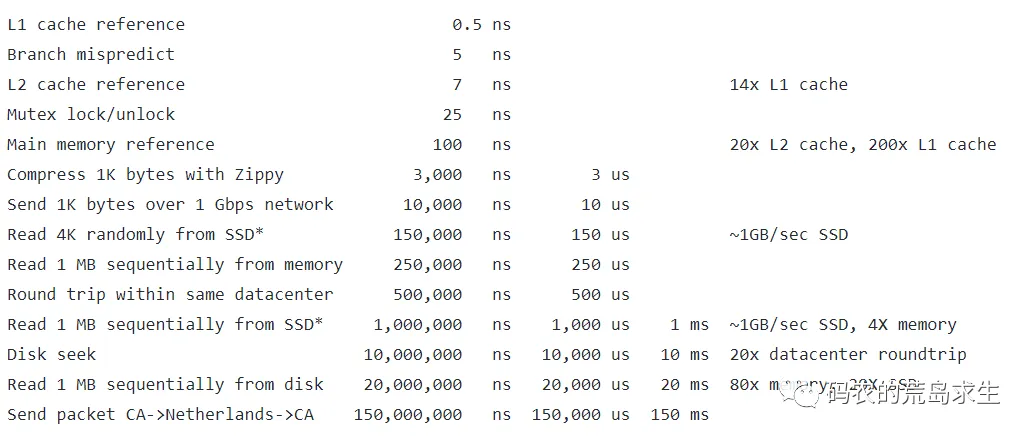
显然从内存中load value的时间比cpu执行指令的时间高得多。为了更快执行写指令,硬件工程师们为CPU增加了==“Store Buffer”==。 如下图所示:

它的作用是暂存store指令,直到内存系统能够处理它。其优化store指令的原理在于当发起store指令时,即使cache未持有目标值(即store miss),也可以立即对当前cpu commit store指令,减少了stall时间。等待 cache 持有该值并处于 read-write coherence state(E或者S状态)时,指令离开store buffer并得到真正执行。
天下没有免费的午餐,得到优化的同时也带来了新的问题,看下面代码:
1 | a = 1; // a初始为0 |
假设只有一个cpu,cache最开始为空,执行 a=1时,由于cache为空,该指令进入Store Buffer, 接着执行b=a+1, 此时cache加载出a的旧值为0,但store buffer中a=1的指令并未执行,b=a+1将拿着cache中a的旧值0进行计算,计算出b=1,最终assert掉了。 这样看来仿佛 a=1与 b=a+1两行发生重排序。 出现的原因在于,a的值有两份,一份在cache中,一份在store buffer中,为了解决这个问题,硬件工程师们对上图做了微调:

cpu在执行load指令时,除了从cache中load数据,也会从store buffer中load数据。这样保证了 a=1 一定会被cpu看到。这种读方式叫做 Store Forwarding。
即使这样,只是保证了单CPU对同一个变量的读写一致,但是对于不同变量的读写,依然可能有重排:
1 | store a |
假设系统上电,b已经在cache中(E状态),a在内存中。现在cpu执行上述指令,由于a store miss,所以进入store buffer,接着执行b,b已经在cache中,可以直接load b。 等待a的数据加载完成,再执行store a的指令。 这个过程,发生了 Write-Read 重排。这也是TSO模型的特性。

即 Read-Read无重排,Read-Write不重排,Write-Read可能重排,Write-Write不重排。Intel采用了这种内存一致性模型。
TSO更为学术的定位为:

再举个Write-Write不重排具体的例子:
1 | CPU0: |
CPU0执行 a = 1后,b=2。 CPU1等待b直到b=2,然后assert(a==1)。 由于在TSO下,Write-Write不重排,所以a=1一定b=2前执行完成,当CPU1观察到b=2时,assert(a==1) 一定满足,不会fire。 另外提一下,TSO防止Write-Write重排的方式,通常是store-buffer以FIFO运行(有FIFO肯定就有非FIFO,非FIFO就可能造成Write-Write重排)。
有了TSO模型,再来比较下它与SC(顺序一致性)的性能:
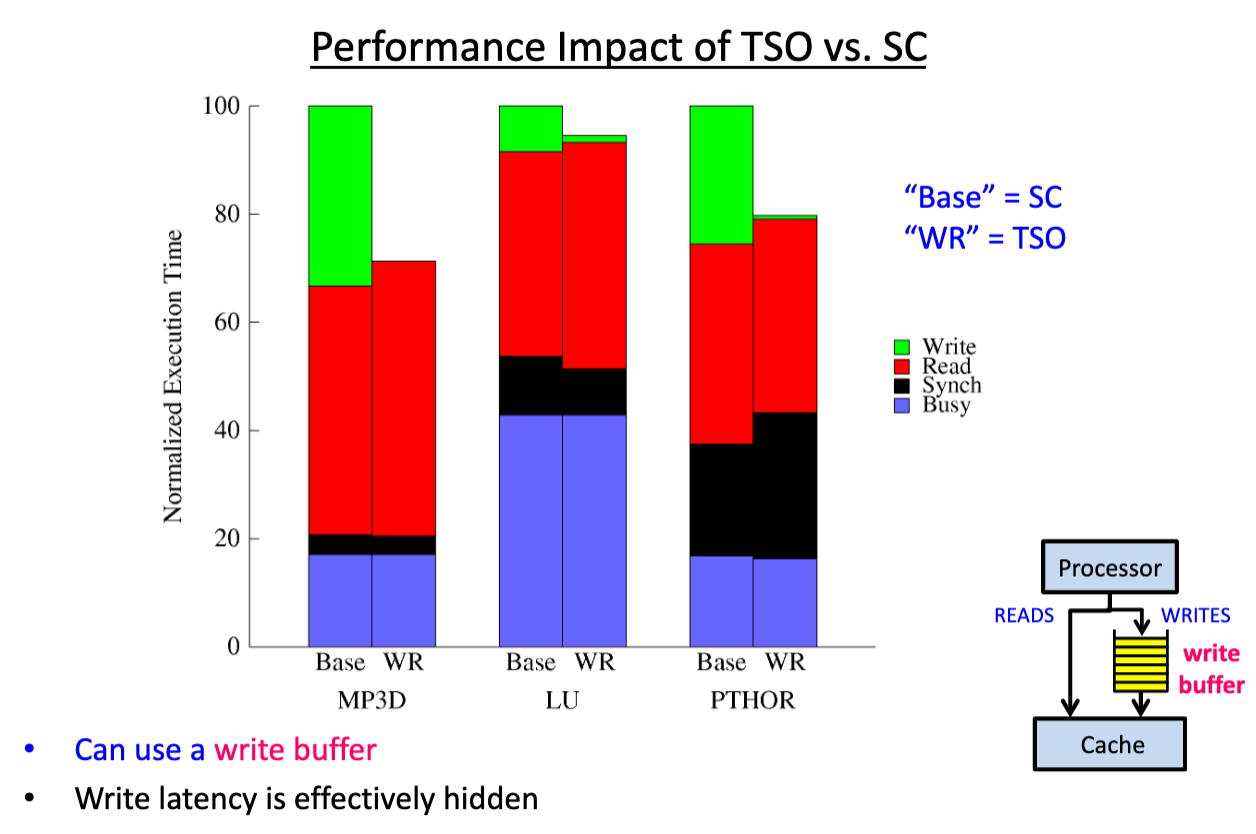
可以看到绿色的Write耗时极大减少了。
Partial Store Order(PSO)·
PSO是比TSO模型更宽松的内存一致性模型。其特点如下:
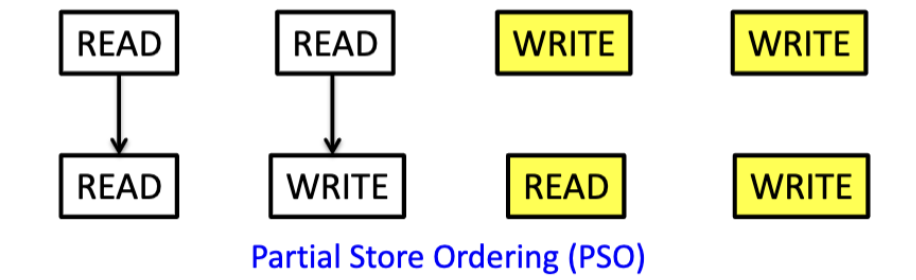
除了允许Write-Read重排外,还允许Write-Write重排。这样的收益是什么?考虑如下两条指令:
1 | a = 1; |
若初始状态 a=1, b=2的a和b都不在cache中,则a=1和b=2都需要等待cache加载a和b的值,并且a=1先进入store buffer,b=2后进入store buffer。假设b的值先加载至cache,为了提升性能,cpu肯定是想立即将b=2指令从store buffer中移除并执行。但这样store buffer就不满足FIFO原则,这也导致了Write-Write重排。
SPARC 支持这种模型。
TODO: PSO Summary
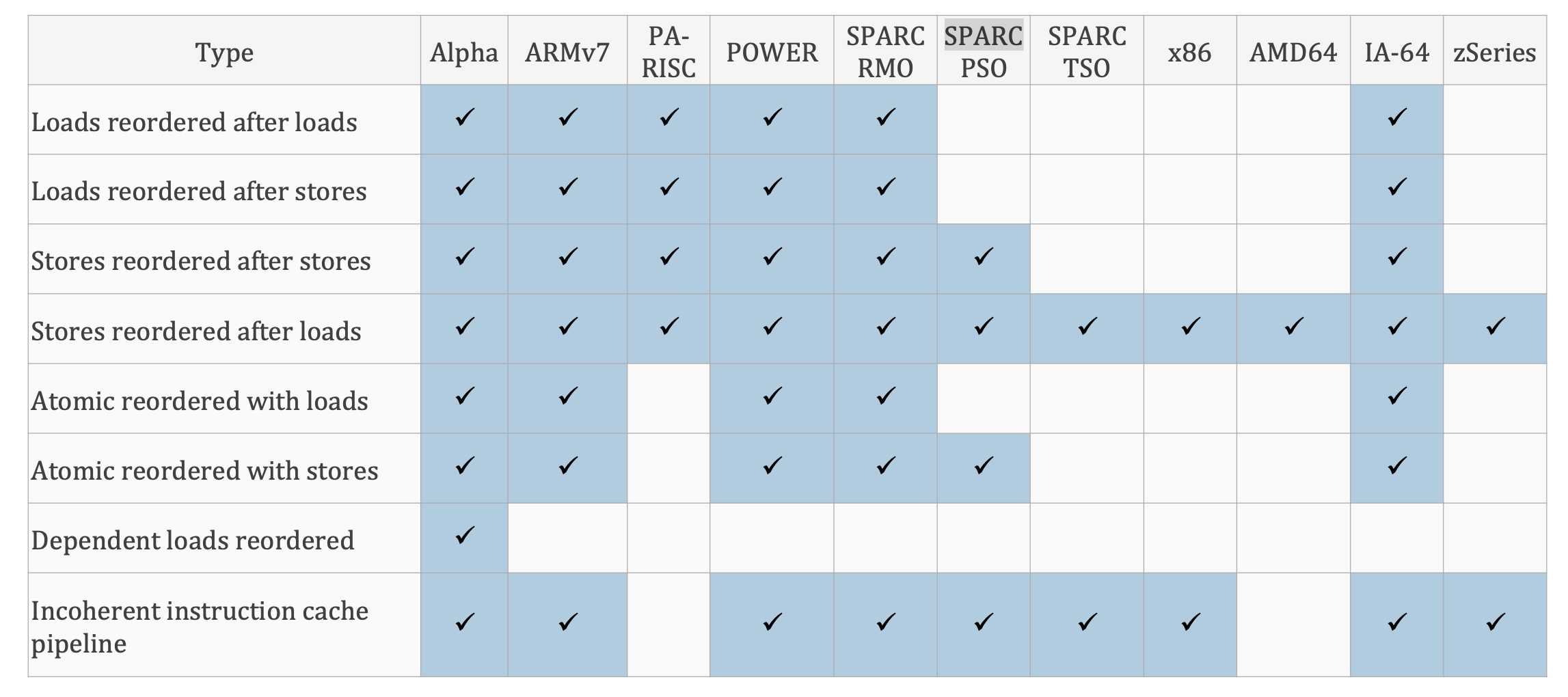
各硬件架构的指令reorder情况总结·
下图总结了各种硬件架构的各种重排情况
3. Cache Coherence vs Memory Consistency·
Cache Coherence: 强调对 同一个 内存地址的读写行为。
Memory Consistency: 强调对 不同 内存地址的读写行为。


4. 内存屏障·
回忆前文所说的PSO模型。它允许Write-Write和Write-Read重排。那么看如下代码:
1 | void foo() |
假设CPU0执行foo,CPU1执行bar函数。其中foo函数的a=1和b=1发生了重排,现有如下执行序列:
1 | step1: CPU0 执行语句2 |
上述执行是简化后的执行序列。
实际情况可能是, CPU0 执行 a=1, b=1(都进入store buffer),由于b所在的cache line先加载进来,所以b=1的指令先退出store buffer。CPU1再执行3和4语句。 单从CPU0的角度看,a=1和b=1都已经执行。但是从CPU1的角度看,它只能看到落在cache中的数据,由于a=1还在CPU0的store buffer中,CPU1无法感知,所以发生了重排。
作为软件开发人员,我们肯定不希望发生这样的重排。这就是 “内存屏障(fence或barrier)” 该发挥作用的时候了:
1 | void foo() |
smp_mb便是内存屏障之一,手册地址
借助手册解释:This function inserts a hardware memory barrier that prevents any memory access from being moved and executed on the other side of the barrier. It guarantees that any memory access initiated before the memory barrier will be complete before passing the barrier, and all subsequent memory accesses will be executed after the barrier.
也就是说插入内存屏障后,上面的代码不能往下走,下面的代码不能往上走。对于foo函数,保证a=1和b=1一定不重排。从硬件角度讲,a=1和b=1都进入store buffer后,即使 b 的数据先在cache中就位,也要保证先刷a=1再刷b=1。显然加入屏障后的代码执行效率会比没加入前低。
有写写重排问题,是否有读读重排呢?答案是有的。考虑这样一个场景,假设cpu执行的store指令都在store miss。这些指令都会转存在store buffer中,但是store buffer的容量是有限的,如果load data的速度跟不上填充store buffer的速度,那么store buffer总有一天会被填充满。那么后续的指令将会stall住。硬件工程师们当然不愿意cpu被stall住,于是提出了 invalidate queue 的结构。回忆MESI协议,多核结构下,假设变量X在各CPU中处于S状态,现在CPU0要对X进行写操作,需要发送Invalidate消息给其他CPU,对端CPU收到消息后,invalidte 自身 cache line回复源CPU invalidate ack消息。这里的耗时主要体现在 “对端CPU收到消息后invalidate自身cache line” 过程中,如果能让消息先暂存在对端CPU,立即回复ack,源CPU也就能更快执行store指令了。 invalidate queue 的工作就是这个,暂存invalidate消息, 等待处理。
CPU承诺:如果一个invalidate请求在invalidate queue中,那么对于这个请求相关的cacheline,在该请求被处理完成前,cpu不会再发送任何与该cacheline相关的MESI消息。

回到主题,读读重排是如何发生的:
1 | void foo() |
上述代码解决了写写重排问题,看下是如何发生读读重排的。假设a同时存在于cpu0和cpu1中,状态为s。b是cpu0独占,E状态。考虑如下序列:
| 序号 | cpu0的步骤(执行set) | cpu1的步骤(执行print) |
|---|---|---|
| 1 | 想写入a=1,但是由于a的状态是s,向cpu1发送invalidate消息 | 执行while(b==0),由于b不在自身的cacheline中,向cpu0发送read消息 |
| 2 | 向store buffer中写入a=1 | 收到cpu0的invalidate消息,放入invalidate queue,响应invalidate ack消息。 |
| 3 | 遇到smp_mb(),等待直到可以将store buffer中的内容刷新到cacheline。立刻收到cpu0的invalidate ack,将store buffer中的a=1写入到cacheline,并且修改状态为M | 等待cpu0响应的read response消息 |
| 4 | 由于b就在自己的cacheline中,写入b=1,修改状态为M | 等待cpu0响应的read response消息 |
| 5 | 收到cpu1响应的read请求,将b=1作为响应回传,同时将cacheline的状态修改为s。 | 等待cpu0响应的read response消息 |
| 6 | 无 | 收到read response,将b=1写入cacheline,程序跳出循环 |
| 7 | 无 | 由于a所在的cacheline还未失效,load值,进行比对,assert失败 |
| 8 | 无 | cpu处理invalidate queue的消息,将a所在的cacheline设置为invalidate,但是已经太晚了 |
可以看到,由于CPU1的执行顺序为: 收到invalidate消息–读数据–处理invalidate消息。所以读数据时,并未感知该数据已经失效。导致assert fire。 从总体看,语句1 2 3肯定不会重排(屏障保证),4 处 b=1退出循环,能够推断出 1 2 3肯定已经执行。 但5处a却=0, 看起来 5先于4执行。这就是 读读重排。
为了解决这个问题,仍然可以通过屏障解决。
1 | void foo() |
5处加的屏障,对于CPU1来说,表现为 “处理完invalidate queue”。 所以当执行到6时,CPU1已经感知到a失效,重新走MESI协议,从CPU0中获取a的最新值1,最终assert不会fire。
如上我们介绍了屏障的两方面作用:
- 解决写写重排,添加屏障,使得CPU将至将store buffer的内容写入cache。
- 解决读读重排,添加屏障,使得CPU将invalidate queue中的请求处理完毕。
回到smp_mb的手册解释:It guarantees that any memory access initiated before the memory barrier will be complete before passing the barrier, and all subsequent memory accesses will be executed after the barrier. 硬件工程师们认为这样的语义保证过于严格,于是将屏障划分为了如下几个:
-
读屏障: 强制cpu将i
nvalidate queue中的请求处理完毕。也被称之为smp_rmb -
写屏障: 强制cpu将
store buffer中的内容写入到cacheline中或者将该指令之后的写操作写入store buffer直到之前的内容被写入cacheline.也被称之为smp_wmb -
读写屏障: 强制刷新store buffer中的内容到
cacheline,强制cpu处理完invalidate queue中的内容。也被称之为smp_mb
这样可将上述代码替换为:
1 | void foo() |
注意,在c/c++代码中,应该尽可能避免使用屏障(除非是写非常底层的代码),而且fence应该总是成对出现。
5. c/c++ volatile 关键字·
上文主要围绕着Memory(Cache) System展开谈了些指令"重排"的问题。但是除了内存(缓存)影响着重排外,还有编译器优化重排。本节不会详细说明编译器优化技术(实际上我也没学过编译原理),只会举例编译器优化例子,同时最重要的,介绍volatile关键字。
编译器优化·
一些编译器优化分类看 这里
例子1:
1 | x = 1 |
如上代码可转换为:
1 | y = "universe" |
由于x最终都会等于 x=2, x=1并没有作用。这种优化方式为 “常量折叠”。 对于单线程来说,这种优化没有问题,但是假设还有其他线程想要观察到 x=1时的状态,这该怎么办?
例子2:
1 | for(i = 0; i< max; ++i) |
如上代码可以转换为:
1 | r1 = *z; |
采用register变量操作,减少访存。
例子3:
1 | for(i = 0; i < rows; ++i) |
转化为:
1 | for(i = 0; i < rows; ++i) |
这个转化就很明显,为了更好locality而优化。
OK, 编译器优化固然好,但是某些场景下,我们并不希望它进行优化。 这时候就需要volatile入场了。 注意这里说的是c/c++ volatile, 不是Java。不同语言这个关键字是完全不同的。
什么时候使用volatile?·
以下三种场景,需要添加volatile修饰:
- Memory-mapped hardware
- Global variables modified by an interrupt service routine/signal handler
- setjmp/longjmp
Memory-mapped hardware·
在嵌入式系统中,通常包含了大量外设设备。这些外设包含的寄存器值,相对于正常的程序流程,可能被异步修改。比如0x1234是一个表明状态的地址,0x1234处的初始值为0,程序需要等待0x1234地址的1字节非0后,才运行后面的代码,典型错误的实现为:
1 | uint1 *ptr = (uint1 *)(0x1234) // 1 |
经过编译器优化,可能变为:
1 | while(true); |
最终变成了一个死循环, 因为我们已经在1处加载过 0x1234的值,循环中没有必要再加载。
为了避免编译器优化,可以添加volatile关键字。
1 | volatile uint1 *ptr = (uint1 *)(0x1234) // 1 |
volatile会阻止编译器优化,由volatile修饰的变量,不会进入register,读写都会通过Memory(Cache) System。
Interrupt Service Routines(ISR) OR Signal Handler·
考虑单片机中的如下代码:
1 | int etx_rcvd = FALSE; |
main函数中,需要等待ext_rcvd为TRUE时,才跳出循环,但是只有在中断中才有机会设置为TRUE。编译器无法感知etx_rcvd会被ISR设置,直接优化ext_rcvd为FALSE。 导致陷入死循环。
解决方案依是将etx_rcvd声明为volatile。
volatile是否能解决c++中的并发问题?·
先给出答案:不行。
看如下代码:
1 | // global shared data |
首先启动thread1, 在thread1中启动thread2,thread1中使用死循环等待flag = true, 期待thread2更改flag为true,然后执行后面的代码。
但很明显,上述代码是问题的。问题有两个:1. thread1中,由于编译器不知道flag还可能会被其它线程修改,所以可能直接将if语句优化掉,变成一个死循环。2. thread2中,flag=true可能被**“指令重排”**到update前面。(update函数本身可以作为一个编译屏障,也就是说编译器生成的代码中,flag=true一定在update函数后,但是不要忘了CPU可是可以乱序执行的)。
前面说了,volatile可以避免编译器优化,那加上volatile后呢?
1 | // global shared data |
加上volatile后,if语句不会被编译器优化,但是CPU依然可以乱序执行。所以flag=true可能跑在value->update函数前。
那该怎么做? – 使用c++中的atomic变量, atomic实现根据平台不同而不同,比如锁总线更新、添加fence指令等,还记得在内存屏障一节中内存屏障的作用吗?,不就是为了防止指令重排嘛:
1 | // global shared data |
6. C/C++ Memory Order·
OK,终于到C++ Memory Order,前面的所有内容都是为了本小节铺垫。c11中,c标准引入了如下内存序:
1 | memory_order_relaxed |
其中consume基本不会用到,本小节不探讨。
后文的内容,基本摘抄自:这里
一些预备知识·
同步点:·
对于一个原子类型变量a,如果a在线程1中进行store(写)操作,在线程2中进行load(读)操作,则线程1的store和线程2的load构成原子变量a的一对同步点,其中的store操作和load操作就分别是一个同步点。
可以看出,同步点具有三个条件:
-
必须是一对原子变量操作中的一个,且一个操作是store,另一个操作是load;
-
这两个操作必须针对同一个原子变量;
-
这两个操作必须分别在两个线程中。
synchronized-with·
对于一对同步点来说,当写操作写入一个值x后,另一个同步点的读操作在某一时刻读到了这个变量的值x,则此时就认为这两个同步点之间发生了同步关系。
同步关系具有两方面含义:
- 针对的是一对同步点之间的一种状态的描述;
- 只有当读取的值是另一个同步点写入的值的时候,这两个同步点之间才发生同步;
也就是说,如果读取的值不是另外一个同步点写入的值,则此时这两个同步点之间并没有发生同步。
happens-before·
当线程1中的操作A先执行,而线程2中的操作B后执行时,A就happens-beforeB。happens-before是用来表示两个线程中两个操作被执行的先后顺序的一种描述。
happens-bofore有三个个特点:
- 可传递性。如果A happens-before B,B happens-before C,则有A happens-before C;
- 当store操作A与load操作B发生同步时,则A happens-before B;
happens-before一般用于描述分别位于**两个线程中的操作之间的顺序**。
sequenced-before·
如果在单个线程内操作A发生在操作B之前,则表示为A sequenced-before B。这个关系是描述**单个线程内两个操作之前的先后执行顺序**的,与happens-before是相对的。
此外,sequenced-before也具有可传递性,并且sequenced-before与happences-before之间也具有可传递性:如果线程1中操作A sequenced-before 操作B,而操作B happences-before线程2中的操作C,操作C sequenced-before线程2中的操作D,则有操作A happences-before操作D。
relaxed order·
relaxed order 是最弱的一种内存序,relaxed除了保证原子性外,其余没有任何保证(如果你是在x86平台上写代码,永远不需要将内存序声明为relaxed order,因为x86保证原子性的方式都是通过锁总线的方式),也就是说指令都以随意重排。
2024-6-24, 即使是x86的relaxed 和 seq_cst 的效果依然是不一样的。
考虑如下代码:
1 |
|
5除代码是否会fire?
答案是YES。z可能等于0。
因为x和y都是原子变量relaxed order。所以可以随意重排。那么2可能先于1执行。 如果执行序列是 2->3->4->1, 那么z将不会被++。即使物理时间上执行的是 1->2->3->4。 z依然可能不会被++(想象之前说的Write-Write重排,Store Buffer的故事)。对于a线程来说,1 2已经执行,但是对于 b线程来说,可能看不到x的修改(x=true在store buffer中)。 b线程看到的x y可能是(true, true), (true, false), (false, true), (false, false)中的任意一个,但是b线程保证,一旦看到x = true, 那么后续只要没有其他线程更改x,b线程后续对x的读都是true。
acquire-release order·
acquire-release order或许是最常见的内存序了。当原子变量同步点的store操作是memory_order_release或memory_order_acq_rel时,而对应的另一个同步点的load操作是memory_order_acquire或memory_order_acq_rel或memory_order_consume时,此时就是acquire-release内存序模型。
可以将acquire-release的同步点组合看成一把锁, 夹在锁中间的是临界区,临界区中的代码不能逃出锁的范围内,但是临界区外的代码可以跑进临界区。
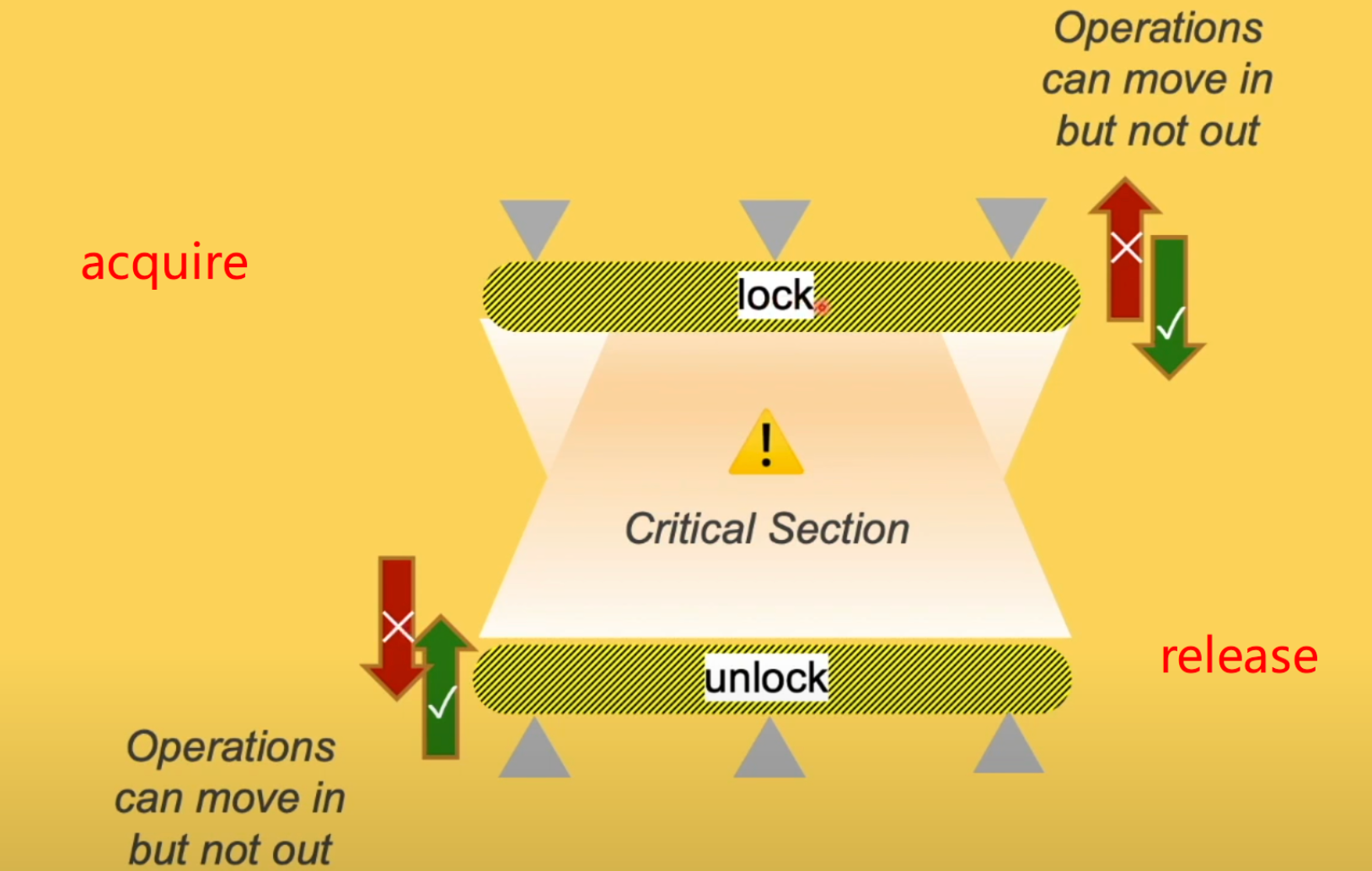
lock 对于 acuiqre, unlock 对应 release。 acquire-release除外保证原子性外,最重要的功能就是同步了,同步的目标是同步非原子变量本身以外的变量。(如何理解这句话,看下面代码)
1 |
|
问: 11处的输出是什么?
答案:一定是 45.9 25 45。
6 和 10构成一组同步点,store release保证,1,2,3,4,5不会被重排到6之后,7 8倒是可以随意重排到6之前。acquire load保证11不会提到10之前,9可以下到10之后。有了这样的保证,再进一步分析, 1,2,3,4,5 都是 sequenced-before 6, 6 happens-before 于10, 10 sequenced-before 11, 根据可传递原则,1,2,3,4,5 happens-before 11。 所以11处的输出是固定的。
再解释:同步的目标是同步非原子变量本身以外的变量。6 和 10是的原子变量是一组控制变量,我们想要的结果是11,被同步的1,2,3,4,5。 1,2,3,4,5可以是原子变量也可以是非原子变量。
假设没有任何编译器优化,细想一下硬件是如何保证上述序列的,可以理解成,store release是由store指令(能保证原子) + mfence构成,mfence 将flush store buffer,也就是说如果 1 2 3 4 5在store buffer中,经过6后,1 2 3 4 5一定写入了cache,cache的一致性由MESI协议保证。同理,对于acquire load是由mfence + load(能保证原子)构成的,mfence保证执行load指令前,先清空invalidate queue,所以经过10处,11所拿到的b c ai都是最新的数据。
再看一个更复杂的例子,x,y,z都是0:
1 |
|
问题:7处可会fire吗?
答案:YES。
我们可以识别上述的4组同步点:

但是1,3,6和2,4,5之间没有任何同步关系。我们可以将3,4重排,5和6重排。这样z是可能为0的。 另外一种理解方式是,acquire-release对于曾经在其他地方发生过同步的原子变量没有任何约束。
看下面的时间线:
1 | T1: // 1 x = 1 |
seq_cst order·
最强,但是性能最差的内存序, 也是默认的内存序。seq_cst修饰的变量,对其做的任何操作,都可想象在其前加入了smb在之后加入了rmb内存屏障,这样seq_cst上面的代码无法移动到下,下面的代码无法移动到上。相比acquire-release order, seq_cst order保证曾经在其他地方发生过同步的原子变量也能继续参与本次的同步
这和分布式系统中的线性一致性类似:
- 任何一次读必须读到最近一次写入的数据
- 执行序列和全局时钟下的顺序一致
再看下面代码:
1 |
|
还是原来的时间线:
1 | T1: // 1 x = 1 |
一些TIPS·
-
如果
seq_cst与acquire或者release配对使用(即seq_cst修饰同一对同步点中的一个,acquire或者release修饰这一对同步点中的另一个),则如果seq_cst修饰的是store操作,则此store操作相当于用的是release语义,如果seq_cst修饰的是load操作,则此load操作相当于用的是acquire语义; -
注意,在使用原子变量之前,最好先使用
is_lock_free()判断一下其内部是否是用锁实现的,如果是的,那么最好不要使用原子变量,而是直接就使用锁,因为锁更不容易出错,且容易维护。这种情况下原子操作的效率并不比锁的效率高。当然,最好是使用相关的宏,直接在编译期就能确定是不是,这样能写出效率更好的代码。此外,C++17的is_always_lock_free()函数也是编译期执行的,也可优先考虑使用; -
原子类型的那些复合赋值操作符(如+=)返回的是当前原子变量存储的新值,而这些操作符对应的成员函数版本(如fetch_add())返回的是原子变量的旧值。例外情况是,前置递增(或递减)运算符返回的是新值,后置递增(或递减)运算符返回的是旧值。注意,它们返回的全都不是引用,而是右值;
-
注意,在弱CAS的平台上(即平台不支持直接使用CPU指令来实现原子类型的比较并交换(
compare-and-swap)操作),compare_exchange_strong()函数可能内部是使用compare_exchange_weak()函数并加上一个循环来实现的。因此,如果用compare_exchange_strong()函数时要主动加一个循环,可以考虑看看能不能直接使用compare_exchange_weak()函数,这样或许能少加一层循环; -
整形原子变量没有乘法、除法和位移动操作符;
-
如果想把
std::atomic<>模板用于自定义类型(UDT),则UDT不能含有虚函数,不能有虚基类,且赋值运算符必须是编译器合成的。此外,UDT的基类以及它的非静态数据成员也必须符合这些条件。这些条件会允许编译器使用memcpy或者等价的操作(也就是连续内存拷贝)来执行赋值操作。最后,UDT原子类型的compare_exchange操作必须可以用按位比较(就像使用memcmp()一样),而不能有任何自定义的比较操作。如果UDT类型提供的比较操作有不同的语义,或者其中含有一些填充bit位不参与比较,则即使数值比较上是相等的,compare_exchange操作也会失败。综合看起来,就UDT就像是C语言中的struct类似,就是存储一些数据的集合体,即使包含有内置类型数组都可以; -
注意,浮点原子类型在使用
compare_exchange等函数时可能会出错,因为浮点数的表示形式可能不一样。此外,浮点原子类型没有任何算数运算操作(比如+=,-=等);
参考·
- 为什么需要内存屏障
- 硬件角度看内存屏障
- Computer Organization & Architecture (COA)
- 为什么在 CPU 中要用 Cache 从内存中快速提取数据?
- C++11内存模型完全解读-从硬件层面和内存模型规则层面双重解读
- cpu缓存和volatile
- 谈谈 C/C++ 中的 volatile
- Introduction To The Volatile Keyword In C/C++
- Is function call an effective memory barrier for modern platforms
- Her Sutter的演讲
- C++ Multi Threading Part 3: Atomic Variables and Memory Models
- CMU-15418 Memory Consistency
- 清华大学-高级操作系统
- Sequential Consistency & TSO
- 图解 CPU-Cache 一致性

