1. 要求·
checkpoint2 是在 checkpoint1的基础上,实现B+树的删除、迭代器和并发访问操作(并发访问只用支持point search, insert和delete,不用支持range scan)。
具体要求参见:这里
总体来说,这部分相对第一部分会更难一些。
2. 题解·
2.1 删除操作·
删除操作是B+树种最为复杂的操作,因为涉及的情况较多。具体情况可以分为2大类:叶子节点和非叶子节点的删除。每类又可以分为4种情况:左兄弟转移,右兄弟转移,左兄弟合并、右兄弟合并。强烈推荐查看这篇文章,应该是我在全网中看到的最详细的B+树删除过程了。
核心函数为以下三个:
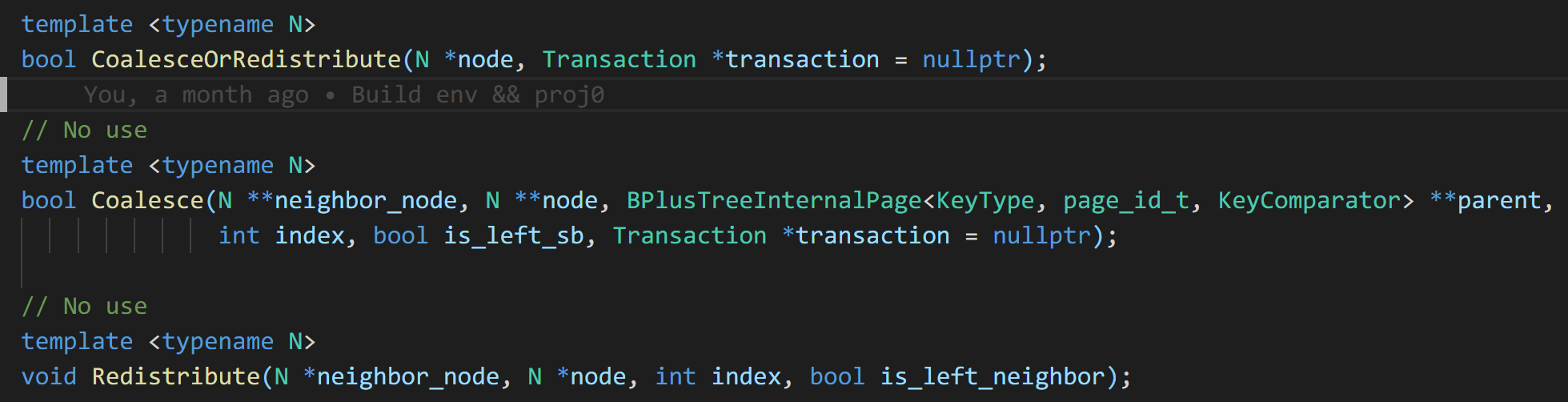
不过我在具体实现过程中,并没有使用 Coalesce 和 Redistribute 两个函数,而是自实现了以下几个函数:
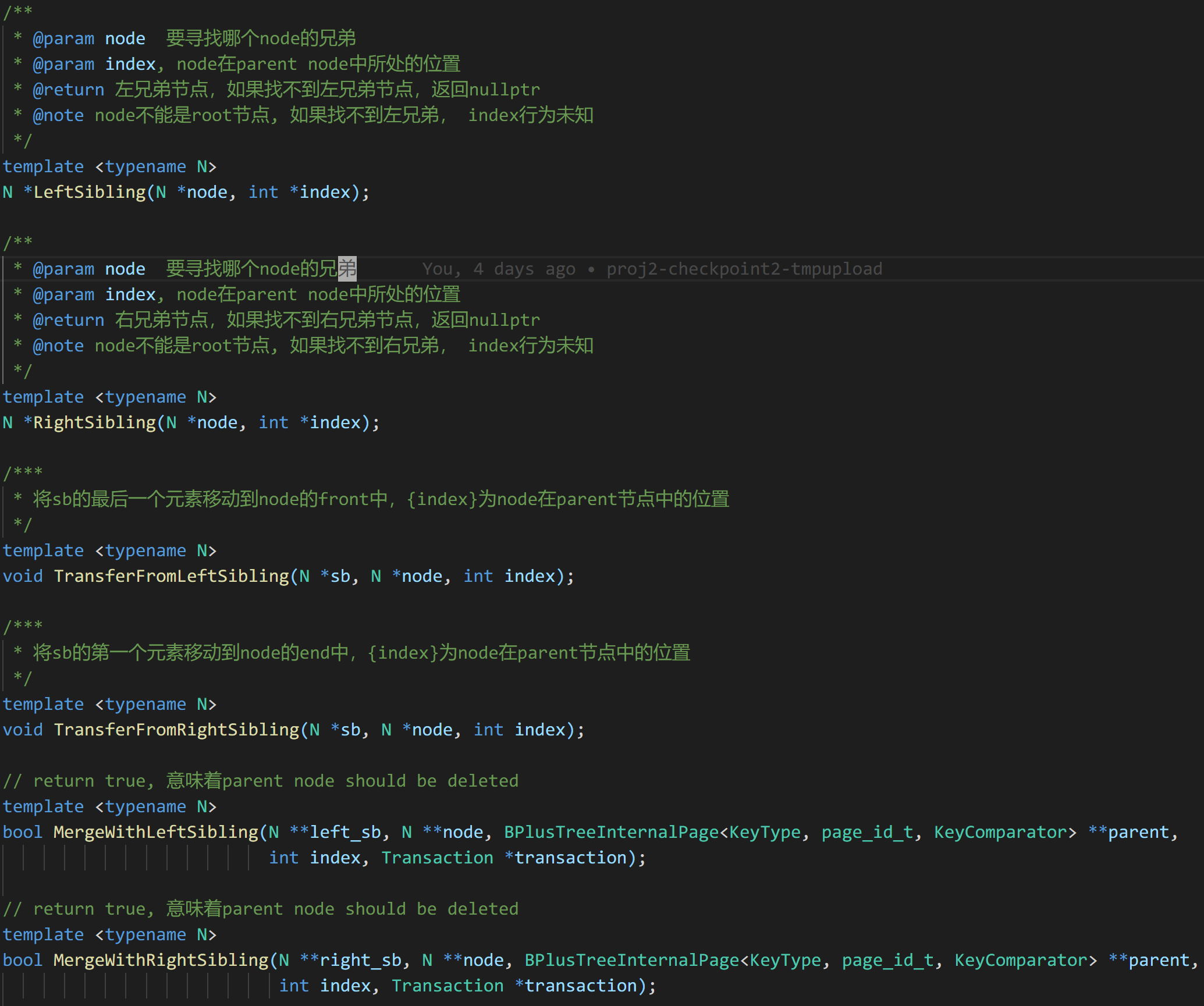
简单描述下删除的算法步骤:
-
判定树是否为空,如果为空,直接返回;否则进入第2步
-
找到要删除的key可能存在的叶节点N,执行删除操作,如果删除无效(key不在该叶子节点中),直接返回;否则进入第3步;
-
查看叶节点N当前剩余size是否大于等于最小size,如果大于等于,则直接返回;否则进入第4步;
-
寻找左兄弟,如果有左兄弟,查看左兄弟是否可以转移一个key value到节点N中,如果不可以,查看右兄弟是否可以转移,转移完成后,更新父节点,返回;如果均不可以,进入第5步。
-
寻找左兄弟,如果有左兄弟,则合并节点N到左兄弟中,更新父节点,如果父节点当前size 小于 最小size,则递归到第4步,如果不存在左兄弟,寻找右兄弟,如果有右兄弟,则合并右兄弟到节点N中,更新父节点,如果父节点当前size 小于 最小size,则递归到第4步;
Note: 如果一直递归到了root节点,由于root节点没有左右兄弟,则需要将root节点合并到孩子节点中。
写完后,可尝试是否能通过 b_plus_tree_delete_test 测试, 最好自己多写一些大规模数据量的测试,同时将tree的internal node和leaf node的最小size设置得尽量小(我是直接设置的3,3),因为这样可以造成更多的分裂,合并。
2.2 Index iterator·
这个就非常好写了,B+ tree暴露了三个函数给上游,分别为:
- begin()
- Begin(key), 这个相当于先seek
- end()
而index iterator中,也只有少量几个函数。核心逻辑为先定位到合适的leaf node,然后可以使用一个索引游标idx,记录当前的位置,如果idx达到一个node(假设为node i)的最大size时,更新游标到下一个node i+1,同时释放node i。
至于 end()函数的设计,我的做法是 end() 是将当前索引到的 node 指针设定为 nullptr。
2.3 并发index·
针对这个问题,最简单的方式是采用 “大锁”的方式, 对全局定义一个 latch, 然后针对 Search, Insert和 Delete操作上 latch, 这样能够保证同一个时刻只有一个线程在做操作。 不过这样的代价就是B+树的性能过低。
我的建议是,先上大锁,然后查看是否能通过并发测试。
我在写时,B+树完成delete操作后通过了单线程下的所有默认测试,但是上大锁时并发测试居然没有过,所以强烈建议自己多写几个单线程下的测试,尽量做到较大数据量和 Internal page和 leaf page 的 min size较小。如果一切通过了,再考虑细粒度锁。
那如何提高性能? 使用 latch crabbing. 详细可以参考讲义ppt和教材的914页。这里只贴一下官方的一个简单描述:
Search: Starting with root page, grab read (R) latch on child Then release latch on parent as soon as you land on the child page.Insert: Starting with root page, grab write (W) latch on child. Once child is locked, check if it is safe, in this case, not full. If child is safe, release all locks on ancestors.Delete: Starting with root page, grab write (W) latch on child. Once child is locked, check if it is safe, in this case, at least half-full. (NOTE: for root page, we need to check with different standards) If child is safe, release all locks on ancestors.
拿 Insert操作来说, 既然在寻找到叶节点的过程中,可能存在加锁和释放锁,那肯定需要一个数据结构来存放之前已经加过锁的page, 这个数据结构存放在Transcation这个类中的page_set_, 如下图:

delte_page_set_是给删除操作使用的
具体实现过程中,核心函数为 FindLeafPage, 在这个函数中,需要实现所有的加锁和释放锁过程,并把还未释放锁的 祖先节点们收集起来放到 page_set_中。问题是在从root节点到leaf节点的遍历过程中,什么时候能够释放祖先节点的锁?那就是判定当前所处的节点,是否safe。 什么是safe?不同的节点,有不同的的定义。我的insert safe_checker代码如下,注意safe_checker的实现与你之前的Insert操作和Delete操作强相关,所以我也不是标准答案:

最后贴一下加锁和释放锁的核心代码:
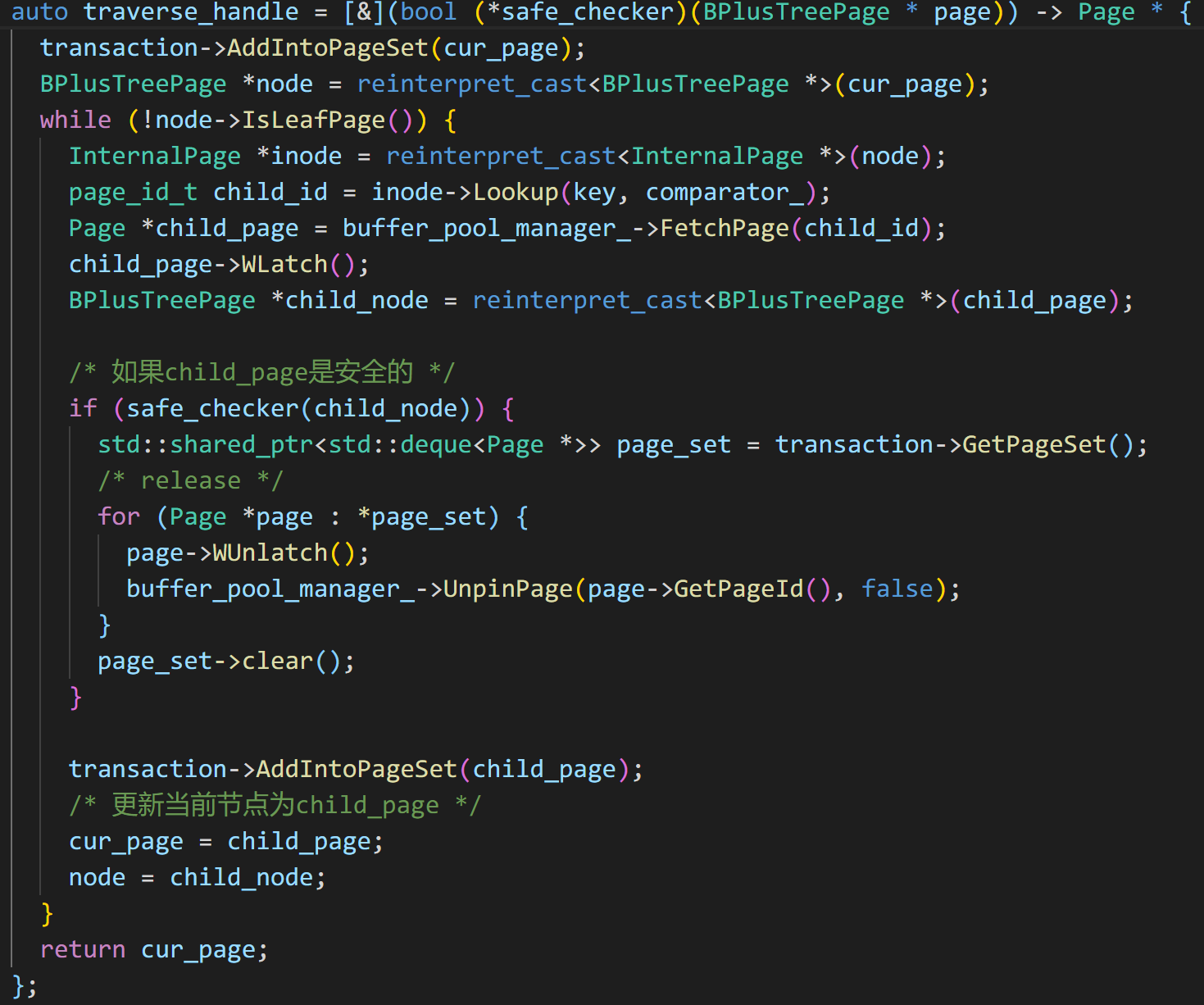
另外,需要思考下UnpinPage和 UnLatch操作的先后顺序是什么, 其实官网上已经给出了答案:
- Think carefully about the order and relationship between
UnpinPage(page_id, is_dirty)method from buffer pool manager class andUnLock()methods from page class. You have to release the latch on that page BEFORE you unpin the same page from the buffer pool.
原因是如果Unpin在Unlatch之前,即使thread拿到page的latch,一旦page被Unpin,后续这个page很可能会被替换出去,那thread拿到的锁也就失去了意义,因为数据已经发生了改变。
3. 注意点记录·
上面是整个寻找过程中的加锁,下面再说说具体实现insert和delete过程中,有哪些需要注意的地方:
-
root id的访问问题。由于root id是会在多个线程被访问,且可能被修改。所以首先要保证root id的访问修改是原子且对其它线程是可见的。这里可以通过一个
mutex来保证(其实最好的做法个人是使用原子变量,但是不方便修改代码中已经默认写好的其他地方,所以采用了mutex)。但除此之外还是可能会存在问题,举个例子:当前root id=10, 存在thread 1执行查询操作, thread 2执行插入操作。 thread 2先被调度,但是在thread 2执行到一半时,切换到了thread 1,此时thread 1拿到root id=10的page,但是还未加上读锁。 此时线程再次切换到thread 2, 而thread 2由于插入操作,造成了原本 root id =10的根节点分裂,生成一个新的根节点,更新root id=11,现在thread 2执行完成,线程切换到thread 1, thread 1还是拿着旧的root id=10的page,加上读锁后执行后续search操作,此时的Search是错误的,因为不是从真正的根节点root id=11的page开始搜索。 那这个该如何解决?- 我个人的做法是,首先记录一次
rootid为old_root_id,并获取page加上读锁后,再次比对old_root_id是否等于当前的root_id, 如果等于,则进行后操作,如果不等于,则释放page的锁,重试本次操作。这部分代码如下:
- 我个人的做法是,首先记录一次
1 | Page *BPLUSTREE_TYPE::FindLeafPageLock(const KeyType &key, OperationType op_type, Transaction *transaction) { |
在调用FindLeafPageLock的地方,这样写:
1 | /* find the leaf page that may contain the key */ |
另一种做法是增加虚拟节点,所有操作应该首先获取虚拟节点,再获取root节点,这样可以将对root节点操作和其它节点的操作统一起来,应该是一种更为精简优雅的做法,也是推荐的做法。
-
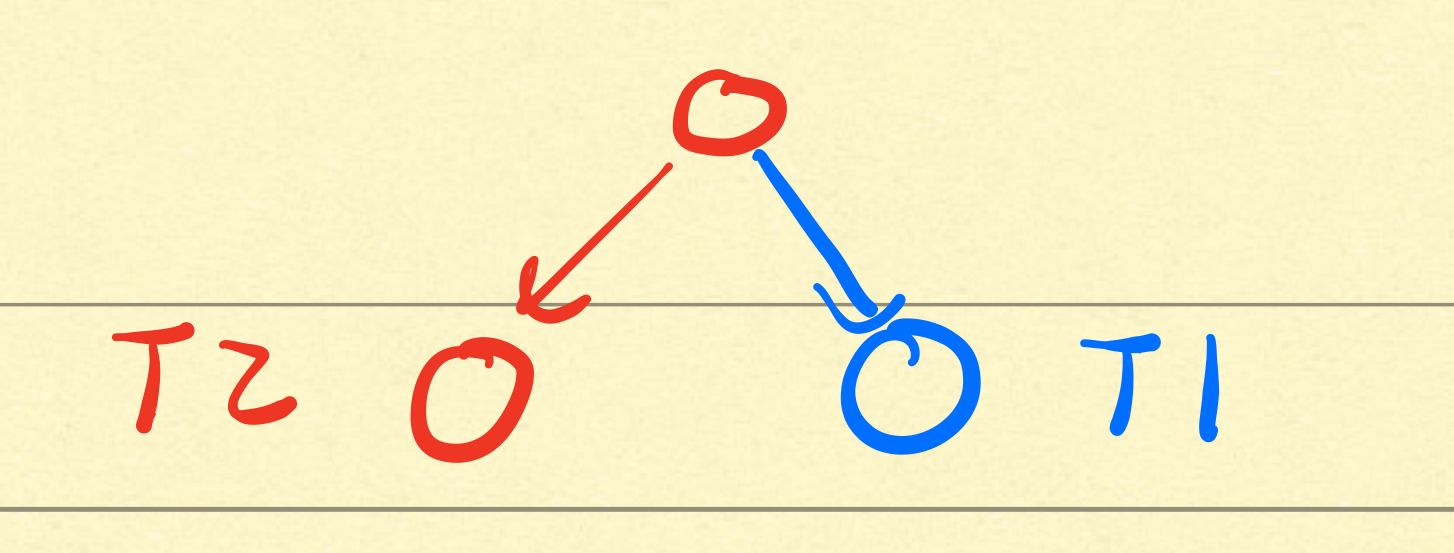
删除操作时,兄弟节点也应该加锁!考虑如下场景:
![image-20211024174634054]()
T1执行插入,并加锁蓝色节点,T2执行删除操作,正在删除旁边的红色,由于红色节点删除元素后,size小于最小size,选择和蓝色节点合并,此时如果不对蓝色节点加锁,那么蓝色节点的数据将得不到一致性保证。T2很可能从T1中拿到错误的数据,这也会造成数据异常。
4. 总结·
整个proj2原本计划两三天搞定,没想到在参考博文代码的基础上,checkpoint1就两天整,checkpoint2又是2天半,前前后后差不多一个星期就没了。实验过程中还是非常有收获的,比如以前从没写过B+树,更没写过会和disk交互的数据结构(以前所有学的数据结构都在内存中),对于并发的调试也多少有了点经验(这里感谢师兄的帮助与建议)。
额外给一点debug的建议:
- 充分利用好能够绘制出来的 dot file来可视化B+树
- 在多线程调试时,尽量找到最小的引起错误的数据量和线程数。 比如我在测试MixTest时,最开始的数据量是
1000*10(操作数据量是1000, 操作线程数是10), 后来降到了20*2, 然后通过 dot file 可视化推导出问题大致所在,最后通过一定的printf打印log,最终找到了bug。 - 多线程下发生错误时,可以尝试先使用大锁查看测试是否通过,再降低锁的粒度。如果大锁测试通过,小锁出现问题,那可能是加锁位置出现问题,此时采用gdb多线程调试其实意义不一定大,反而通过LOG分析更为有效。
最后,记录下checkpoint2满分: