标题起得有点唬人,但问题出自公司内的一个陈年老bug,表象是"atomic 不原子"。根本原因是在给原子变量分配内存时出现了跨cacheline分配。具体见下面的例子:
有问题的代码如下。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
| #include <atomic>
#include <thread>
#include <memory>
#include <vector>
#include <cstdio>
#include <cassert>
#include <sys/mman.h>
struct Meta {
uint32_t padding;
std::atomic<uint64_t> a;
};
class RunAlowayclass {
public:
RunAlowayclass(Meta *meta) {
meta_ = meta;
meta_->a.store(0x00000000FFFFFFFF, std::memory_order_release);
}
void set_1() {
while (true) meta_->a.store(0x00000000FFFFFFFF, std::memory_order_release);
}
void set_2() {
while (true) meta_->a.store(0xFFFFFFFF00000000, std::memory_order_release);
}
Meta *meta_;
};
int main(int argc, char **argv) {
Meta * meta = (Meta *)mmap(NULL, 4 << 10, PROT_WRITE | PROT_READ, MAP_PRIVATE | MAP_ANONYMOUS, -1, 0);
printf("meta first addr:%p %%64=%lu, \n", meta, (uint64_t)meta % 64);
assert((uint64_t)meta % 8 == 0);
meta = (Meta *)((char *)meta + 52);
printf("meta second addr:%p %%64=%lu\n", meta, uint64_t(meta) % 64);
new(meta) Meta;
RunAlowayclass ra(meta);
std::thread t1(&RunAlowayclass::set_1, &ra);
std::thread t2(&RunAlowayclass::set_2, &ra);
while (true) {
auto lsn = meta->a.load(std::memory_order_acquire);
if (lsn != (uint64_t)0xFFFFFFFF00000000 && lsn != (uint64_t)0x00000000FFFFFFFF) {
printf("something wrong, %lu\n", lsn);
exit(0);
}
}
t1.join();
t2.join();
return 0;
}
|
简述下代码逻辑,给一个结构体,内部含有 atomic 变量a,起两个线程,线程1对a执行 store 0x00000000FFFFFFFF 操作, 线程2对a执行 store 0xFFFFFFFF00000000操作,在主线程上,不停观察这个原子变量,如果出现不等于 0x00000000FFFFFFFF,也不等于 0xFFFFFFFF00000000 的情况下,就一定是发生了非原子更新。
代码逻辑很简单,读者可自行拷贝一份编译并在自己电脑上跑跑试试。
说下结论: intel的CPU,上述代码会打印 something wrong, 并退出。 arm的CPU,直接报bus error。
如下讨论只讨论intel AMD64架构。
这似乎不合常理,也引起了公司团队组内成员的大量讨论,绝大数人持怀疑态度,这其中涉及一些底层硬件原子性知识和汇编知识。我们来慢慢分析。
首先看下原子变量a在 release memory order下的汇编指令:
![image-20240720145439659]()
开启O2优化,AMD 64下,原子变量store + release order不过就是一条mov指令,没有任何锁总线之类的操作。我们相信,intel CPU能够用单条mov指令保证原子性更新,但基于了某种前提,如内存是否对齐或是否跨cacheline。
回到有问题的代码,如果我们将代码改成:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
| #include <atomic>
#include <thread>
#include <memory>
#include <vector>
#include <cstdio>
#include <cassert>
#include <sys/mman.h>
struct Meta {
uint32_t padding;
std::atomic<uint64_t> a;
};
class RunAlowayclass {
public:
RunAlowayclass(Meta *meta) {
meta_ = meta;
meta_->a.store(0x00000000FFFFFFFF, std::memory_order_release);
}
void set_1() {
while (true) meta_->a.store(0x00000000FFFFFFFF, std::memory_order_release);
}
void set_2() {
while (true) meta_->a.store(0xFFFFFFFF00000000, std::memory_order_release);
}
Meta *meta_;
};
int main(int argc, char **argv) {
Meta *meta = (Meta *)malloc(2 * sizeof(Meta));
printf("meta first addr:%p %%64=%lu, \n", meta, (uint64_t)meta % 64);
assert((uint64_t)meta % 8 == 0);
new(meta) Meta;
RunAlowayclass ra(meta);
std::thread t1(&RunAlowayclass::set_1, &ra);
std::thread t2(&RunAlowayclass::set_2, &ra);
while (true) {
auto lsn = meta->a.load(std::memory_order_acquire);
if (lsn != (uint64_t)0xFFFFFFFF00000000 && lsn != (uint64_t)0x00000000FFFFFFFF) {
printf("something wrong, %lu\n", lsn);
exit(0);
}
}
t1.join();
t2.join();
return 0;
}
|
则不会出问题,代码一直卡在:
1
| meta first addr:0x55f50c8a6e70 %64=48,
|
根据cpp标准对struct的内存布局要求, sizeof(Meta) = 16。 从上述打印中可知,meta的地址取余64=48,意味着原子变量处在48+8=56B偏移处,56可被8整除,说明a的地址是8B对齐的,且没有跨cacheline。
实际上,meta的地址取余64并不恒等于48, 不同的操作系统上,可能会有不同的结果,但**GNU malloc保证64位系统上,分配出来的地址是16B对齐的**。 也就是说,变量a的地址一定是8B对齐的,同样也意味着变量a不会跨cacheline。
和有问题的代码对比,不同的地方在于内存分配:
1
2
3
4
5
6
7
8
|
Meta * meta = (Meta *)mmap(NULL, 4 << 10, PROT_WRITE | PROT_READ, MAP_PRIVATE | MAP_ANONYMOUS, -1, 0);
printf("meta first addr:%p %%64=%lu, \n", meta, (uint64_t)meta % 64);
assert((uint64_t)meta % 8 == 0);
meta = (Meta *)((char *)meta + 52);
printf("meta second addr:%p %%64=%lu\n", meta, uint64_t(meta) % 64);
new(meta) Meta;
|
这里采用了mmap分配内存,为保证了分配出来的地址4K对齐,方便操作。我们将meta的首地址偏了52B, 并在偏了52B处做了placement new。此时原子变量a的前4B处在一个cacheline中,后4B处在另一个cacheline中。变量a跨了cacheline! 这就有问题了。所以会打印"something wrong"。
除了跨cacheline有问题外**,我们进一步探究了如果原子变量a不按照8B对齐是否有问题**,如下代码:
1
2
3
4
5
6
7
8
|
Meta * meta = (Meta *)mmap(NULL, 4 << 10, PROT_WRITE | PROT_READ, MAP_PRIVATE | MAP_ANONYMOUS, -1, 0);
printf("meta first addr:%p %%64=%lu, \n", meta, (uint64_t)meta % 64);
assert((uint64_t)meta % 8 == 0);
meta = (Meta *)((char *)meta + 47);
printf("meta second addr:%p %%64=%lu\n", meta, uint64_t(meta) % 64);
new(meta) Meta;
|
把偏52,改偏47。 这样变量a的首地址为55, 非8B对齐。 但结果是变量a依然是原子更新的。 这似乎不合乎我们的潜意识:”intel下,8B以内的数据如果是自然对齐,则保证可原子操作,如果不对齐则不是原子“的原则。
自然对齐:按照变量本身type对齐,如uint32_t则按4B对齐,uint64_t按8B对齐。
为了进一步确认intel 64架构下到底什么场景才能保证普通指令的原子性,我翻了intel的白皮书。白皮书里这样写到:
![image-20240720153330816]()
原来对齐与否对原子性的影响还得看CPU。 在P6 family 之后的CPU即使不是对齐的,也能保证原子性,只要在同一个cacheline即可。不过为了可移植性以及性能的考虑,我们始终应该让mem对齐来操作。
看到这里,有些读者可能会疑惑为什么会有这么奇怪的用法,malloc出来还要偏一个offset来placement new对象。 读者可以想象成我们自己做了一个内存分配器,分配了一大片内存,然后切分内存给要分配内存的对象,问题就出在这里的切分未保证对齐性。
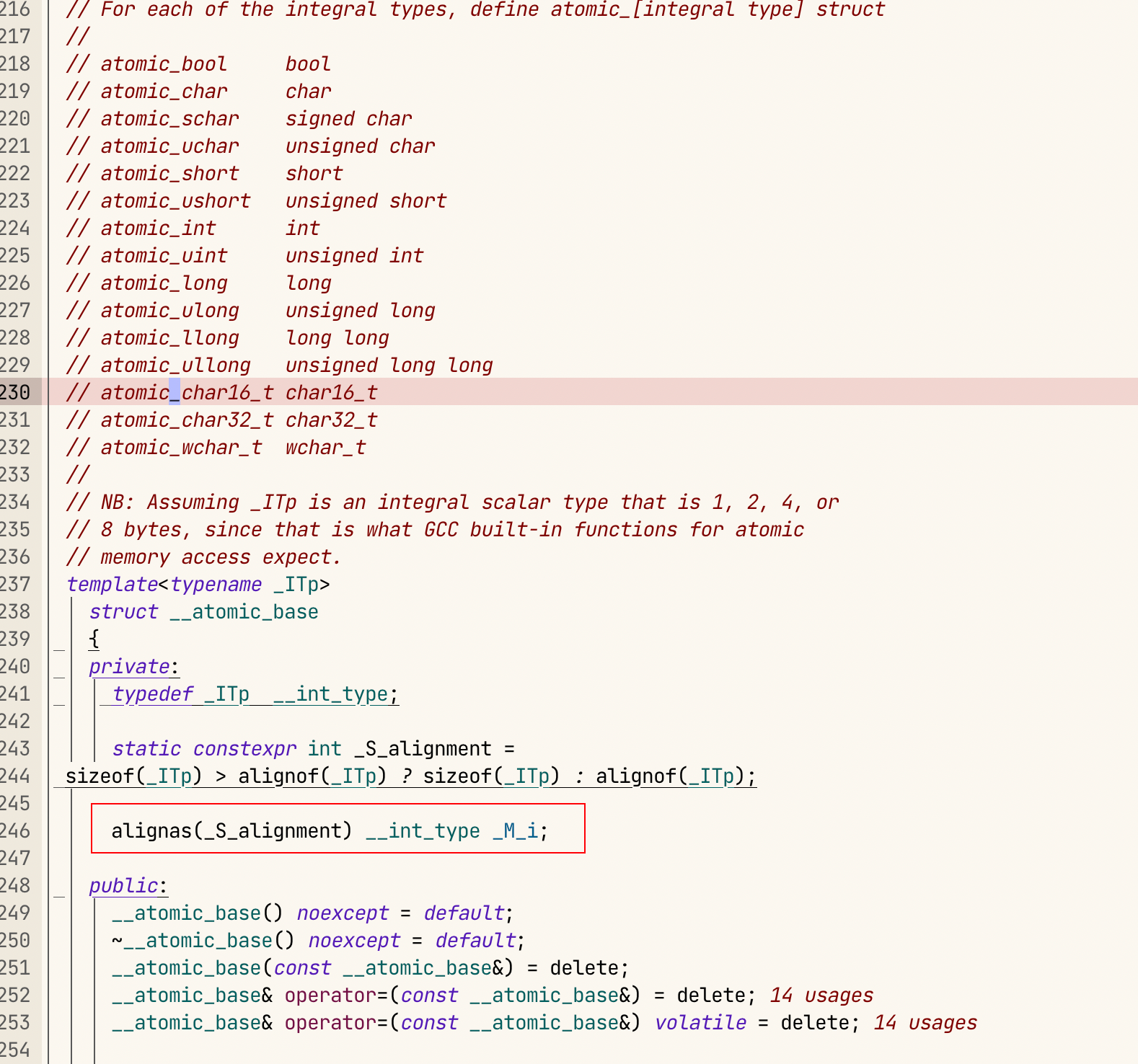
除了以上分析外,我们还看了std::atomic的源码实现:
![image-20240720161632848]()
std::atomic 源码里,使用了 alignas 关键字要求 _M_i 对齐, 可惜我们的malloc+偏移操作打破了这一约束,导致这成了一个 undefined behavoir, 而这个UB,在Linux GNU 编译器+intel P6 family后的CPU,演变成了如果不在同一个cacheline分配,则不保证原子性。 而在其他平台,如arm就是一个bus error了。
简单总结下:
- std::atomic的使用中,要注意内存对齐,编译器在stack上分配和heap内存分配器已经考虑了对齐,通常我们不需要关心,但如果有自定义分配器的操作,需要考虑对齐
- intel CPU的原子性在不同CPU下有不同保证,但是64位架构,如果内存分配时保证了8B对齐,则能保证操作的原子性。