i> 本科毕设题目为《基于深度学习的图像去雾方法研究与实现》
毕设总结系列:
- 毕设总结零–绪论
- 毕设总结一–传统去雾理论
- 毕设总结二–论文复现工作1–暗通道去雾(DCP)
- 毕设总结三–论文复现工作2–MSCNN去雾
- 毕设总结四–最终去雾方案的确定与实现–DeBlurGanToDehaze
- 毕设总结五–杂项
1. 前言·
上一篇文章中,我们介绍了MSCNN的去雾方法以及MSCNN的Keras实现。这篇文章中将介绍笔者的毕设中所采用的去雾结构。
2. 去雾前夕·
2.1 端到端的去雾网络·
在总结系列的一、二、三中,我们所介绍的理论和去雾方法均是以大气散射模型为基础,以估参作为重点研究过程,包括Aod-Net[1]虽然不是单独估计透射图和大气光,但仍离不开估参。已估参为主的这些去雾方法始终都有一个弊端:或多或少的都有额外的误差。
能不能建立一种端到端的映射网络呢?给网络输入一张雾图,输出得到一张去雾图。
就像总结零曾有过的一张图那样:

那什么样的网络可以实现这样的效果呢?
自2014年生成对抗网络(GAN)提出以来,GAN便以一种新式的训练思想逐渐火热。现在已经很多基于GAN的应用,如图像修补,图像风格转换等等。于是自然而然的,笔者采用了GAN来做上图中的去雾网络。
2.2 浅谈GAN·
去雾GAN的核心思想如下图:
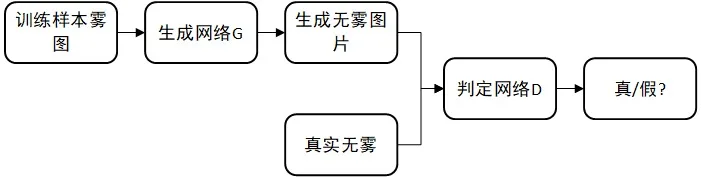
它有两个重要的子网络,一个生成网络G,一个判别网络D。现在假设我们手里有三样东西:
- 设计精良的生成网络G
- 设计精良的判定网络D
- 训练这个大网络所需要的 “ 雾图-无雾图” 多个数据对。
i> 那么这个网络的思想可这样来表达:生成网络G吃一张雾图,吐出一张“假”无雾图,从训练数据集中找到吃掉的雾图的对应“真”无雾图,判别网络D尽自己最大的可能去区分开这“真假”雾图,另一方面,生成网络G尽自己最大的可能去生成接近“真”无雾图的“假”无雾图,用来迷惑判别网络D。两者在这种竞争关系下不断进化,最后达到一种平衡。
关于GAN的文章,推荐阅读:
-
GAN学习指南:从原理入门到制作生成Demo
-
简单理解与实验生成对抗网络GAN - 我爱智能 - CSDN博客
-
Keras-GAN
-
[Isola et al_2016_Image-to-Image Translation with Conditional Adversarial Networks](Isola et al_2016_Image-to-Image Translation with Conditional Adversarial Networks.pdf)
-
Patch-GAN Image-to-Image Translation with Conditional Adversarial Networks超细致解析:使用条件Gan经行图像的转换
-
17种GAN变体的Keras实现请收好 | GitHub热门开源代码
-
GAN with Keras: Application to Image Deblurring – Sicara’s blog
-
李宏毅GAN视频教学
3. 去雾网络结构·
前文我们说了GAN有两个核心的子网络,如何分别设计两个网络的结构呢?反正我是不会设计,哈哈。嘛,总之这时候我是求助了师兄,师兄丢给了我一篇DeBlur的论文,然后我做了个Transfering Learning。没想到效果相当好,于是就这样抄过来了。
DeBlur的论文:《DeblurGAN: Blind Motion Deblurring Using Conditional Adversarial Networks》
3.1 生成网络结构·

- 2个编码单元提取特征
- 9个ResBlock作为特征转换器,将它从雾图特征转到无雾特征
- 2个解码单元恢复无雾图
你要问我为什么这样设计?不好意思,我也不知道。个人觉得深度学习就是一个黑盒子,讲究的是最终效果,往往没有特别好的理论支撑。
3.2 判别网络结构·
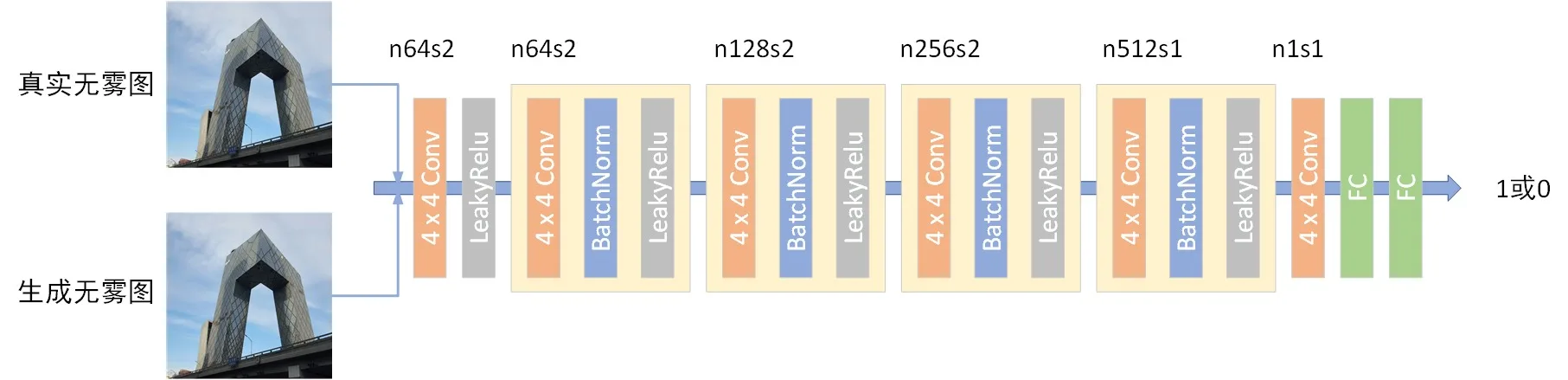
判别网络参见《Image-to-Image Translation with Conditional Adversarial Networks》中的PatchGAN。关于PatchGAN的理解 - xiaoxifei的专栏 - CSDN博客
4. 损失函数设计·
这里损失函数由两项构成: $$ L = L_{感知损失} +\lambda L_{对抗损失} $$ 在说感知损失(perception loss)前,先来看看简单的MSE损失,我们曾在MSCNN网络结构中提到过MSE损失函数。他比较的是生成图与标签图之间的像素级别均方差。 $$ L(t_i(x),t_i^{\delta}(x)) = \frac{1}{q}\sum_{i=1}{q}||t_i(x)-t_i{\delta}(x)||^2 $$ 那什么感知损失?简单的说就是将生成图和标签图在通过一个网络,得到两张图的特征图,在这两张特征图上做MSE。一般来说,通过的这个网路会选择VGG网络。感知损失的计算公式如下: $$ L_{感知损失} = \frac{1}{CHW} \sum_{j=1}^{3} || \phi_j(I^{Label}) - \phi_j(G(I^{haze})) ||^2 $$
- $\phi$理解为通过网络的等效函数
- CHW分别代表图像通道数,图像高度和宽度
paper中的对抗损失采用的是WGAN-GP中的Loss,但是我通过阅读它的源码发现它只采用了wgan loss。虽然我后期想自己修改为wgan-gp loss,但是无奈,WGAN-GP后面的理论真的好多,加上时间已经不够且当时基于WGAN中的loss效果已经很好了,所以最后未能完成修改。
关于WGAN 和 WAGN-GP推荐阅读:
- GAN — Wasserstein GAN & WGAN-GP – Jonathan Hui – Medium
- DCGAN、WGAN、WGAN-GP、LSGAN、BEGAN原理总结及对比 - Double_V的博客 - CSDN博客
- WassersteinGAN-GP
5. 实现代码参考·
5.1 构建生成器代码·
1 | def generator_model(): |
5.2 构建判别器·
1 | def discriminator_model(): |
5.3 构建整个网络结构·
1 | def generator_containing_discriminator_multiple_outputs(generator, discriminator): |
5.4 训练网络·
1 | def train(batch_size, epochs, critic_updates=5): |
和MSCNN一样,代码中还有很多需要注意的地方,可自行参考文末的开源链接。
5.5 参数设置·
不懂这些参数的,可自行参考代码。
- epochs = 50
- batch size = 2
- critic_updates = 4
- Adam 优化器
在GTX1060 的显卡上跑了8个小时。
6. 实现效果展示·



除此之外,我还做了一个Android App,电脑作为服务器,Android端上传雾图进行去雾,服务处理后回馈,Android显示。视频Demo:
!!! !!!7. 结语·
虽然是copy的Deblur结构,但是自己实现出来的时候还是非常高兴的。
所有源代码地址:https://github.com/raven-dehaze-work/DeblurGanToDehaze

