本次lab Proxylab。 也是csapp的最后一个lab。
1.实验目的·
proxylab, 从最终目的来看,我们实现的是一个代理服务器。proxy接收来client的请求,转发给server,并从server中取得数据后,返回给client。另外,proxy从server中取回数据后还需要做cache,这样,当另一个client请求相同的数据时,就不用从server端请求数据,降低了server的压力。
再看看一些细节的要求,要求支持多线程请求,多线程涉及一些同步的问题,所以做的时候一定要考虑哪些是互斥资源,用什么方式同步等。
2.个人实现·
下面是整个处理流程图:

client向proxy请求数据,proxy将请求放入到一个任务队列中,交由子线程处理。线程负责参数解析,首先看cache中是否有满足的数据,有则直接返回给client,没有则向server请求,server返回数据后,线程将数据插入到cache中,并返回给client。
ok,整个处理流程知道后就可以开始写代码了。
下文不会给出所有代码,具体代码已贴github:
proxy.c
1. 主线程工作·
先看看主线程做的工作,主线程的工作相对简单,除了一些必要的初始化工作外,只需要开启socket监听,一旦有新连接就将该连接的文件描述符(fd)放入到任务队列中:
1 |
|
2. 子线程工作·
子线程从任务队列中获取一个“任务“,然后doit
1 | static void *thread_routinue(void *vargs) |
doit就复杂些了,因为基本包含了所有工作:
- 负责获取client请求
- 解析client请求
- 转换成可以发送给server的请求
- 获取数据,可能从cache中获取,也可能从server中获取
1 | static void doit(int fd) |
整个流程就是这样,处理起来不算来。下面我们主要看看整个流程中设计到的一些互斥资源。
- sbuf,互斥队列,这个是csapp提供了,我们可以直接用,内部采用“生产者-消费者”的思想+信号量的实现。
- cache,典型的”读写锁“实现,个人这里采用的是写优先的读写锁信号量实现。
3. cache的实现·
那下面就说一下cache的实现吧。
文中定义了cache的最大size和一个object的最大size。为了简单起见,我们按照max object size来分块,然后采用LRU算法来替换cache block。
首先看看用到的数据结构:
1 | typedef struct{ |
cache_item定义了一个cache block的数据及元数据。
cache则由多个cache_item组成了。
然后是要用到的一些函数:
1 | int cache_init(cache *cp); |
接口很简单,就get、put。
先看看简单的init和deinit:
1 | /** |
说get和put之前,先说说读写锁-写优先的操作。
- 写-写互斥
- 写-读互斥
- 读-读共享
- 读加锁时,后续有读线程又有写线程时,写线程优先。
看PV实现:
1 | int read_counter = 0; // 记录读者数 |
ok, 有了以上基础知识,写cache_get和cache_put就会很简单了。
1 | /** |
4. cache实现的额外想法·
其实cache最开始我是准备用Log-Strucutre的实现,但是发现实现起来很复杂,而且csapp的测试跑不了太久,Log-Sturcutre的优点没法充分利用。下面简单说一下思路。Log-Strucutre的特点就是Only-Append. 题目的要求是缓存从server返回的数据,而这些数据的大小不一,如果按照上文的实现,必然会导致很多内部碎片。而采用only-append的思想,则不存在内部碎片的问题,如下图:
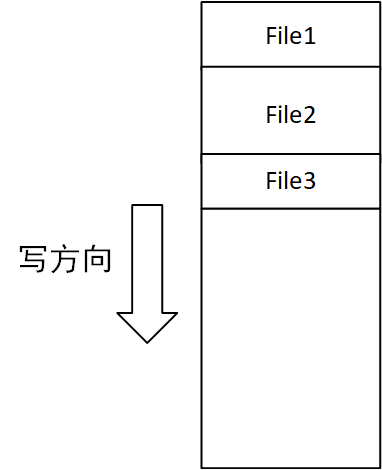
但是这样又会存在一个新问题,那就是cache空间是有限的,我们最后总会evict掉某些块,**那就很容产生外部碎片问题,**这该怎么解决呢?开启一个compact线程就好了,compact线程可以周期性的对整个内存空间做压缩处理,去掉外部碎片问题。compact的触发点可以有两个:
- 周期性触发
- 当前cache已满
但是每次compact可能也会成为cache的读写性能瓶颈。 所以现在又该怎么办?
可以考虑**“分页思想”,**操作系统里面最经典的知识之一,要想提高系统的内存利用率,降低外部碎片和内部碎片,那就将内存分页,将每个取回的file进行分页,然后插入到“虚拟内存页”,不过这样需要维护页表了。实现难度较大,所以我也没做了,实在没时间继续耗在csapp上,不过还是想将这个思路写在这里,说不定未来我就回来写了呢。
3. 总结·
这个实验涉及的知识较多,网络编程(c语言的socket一言难尽啊,特别写过python和java后。。。),多线程并发,同步信号量,cache替换策略,每一个都是重要的知识点。所以也还是挺有收获的。
当然了,这也是csapp的最后一个lab,也就意味着我的csapp之旅告一段落了,但是csapp这本书是真的值得每个程序员多看几遍的,里面的每个知识点都相当重要。

