本次lab,malloclab,自己手写一个内存分配器。
1. 实验目的·
malloclab,简单明了的说就是实现一个自己的 malloc,free,realloc函数。做完这个实验你能够加深对指针的理解,掌握一些内存分配中的核心概念,如:如何组织heap,如何找到可用free block,采用first-fit, next-fit,best-fit? 如何在吞吐量和内存利用率之间做trade-off等。
就我个人的感受来说,malloclab的基础知识不算难,但是代码中充斥了大量的指针运算,为了避免硬编码指针运算,会定义一些宏,而定义宏来操作则会加大debug的难度(当然了,诸如linus这样的大神会觉得,代码写好了,为什么还用debug?),debug基本只能靠gdb和print,所以整体还是有难度了。
2. 背景知识·
这里简单说一下要做这个实验需要哪些背景知识。
首先,为了写一个alloctor,需要解决哪些问题。csapp本章的ppt中列出了一些关键问题:
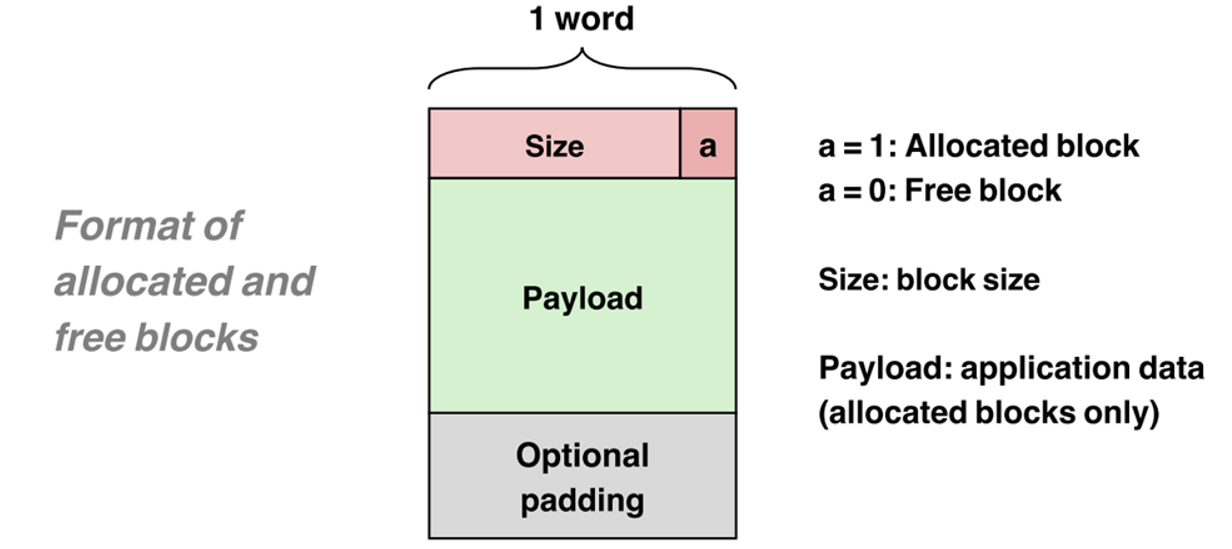
第一个问题,free(ptr)这样的routine是如何知道本次释放的block的大小的?
很显然我们需要一些额外的信息来存放block的元信息。之类的具体做法是在block的前面添加一个word,存放分配的size和是否已分配状态。
注意:这里只是给出了最简单的情况,实际操作中,额外的元数据不仅只有这些
第二个问题,如何追踪free blocks?
csapp一共给出了4种方案。其中implicit list在书上给出了源码,我个人实现了implicit list和explicit list。segregated free list感觉利用OO思想,把explicit list封装一下也是能够实现的,红黑树同理。
第三个问题,拆分策略(详见代码的place函数)
第四个问题,一般来说有 first-fit, next-fit和best-fit策略,我这里采用了最简单的first-fit策略。(这其实是一个trade-off的问题,看你是想要吞吐量高还是内存利用率高了)
ok,下面就来看看implicit list(书上有)和explicit list两种方案是如何实现的。
3. Implicit list·
下面是一个implicit list的组织方式和一个block的具体情况,一个block采用了双边tag,保证可以前向和后向索引。
这种方案的优点:实现简单。缺点:寻找free block的开销过大。
现在说说lab中给的一些代码把:
memlib,这个文件中,给出了heap扩展的方法,除此之外,我们还可以获取当前可用heap的第一个字节,最后一个字节,heap size等。具体实现是通过一个sbrk指针来操作的。
mdriver, 这个文件不用看,只用它编译出来的可执行文件即可,用于测试我们写的allocator是否正确。
mm.c, 这个就是我们要操作的文件了,主要实现三个函数 mm_malloc,mm_free,mm_realloc,我们再额外定义自己需要的函数。
好的,下面再说说具体代码,因为代码中涉及到很多指针操作,我们对这些操作做一个峰装,用宏定义来操作:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 #define WSIZE 4 #define DSIZE 8 #define CHUNKSIZE (1<<12) #define MAX(x, y) ((x) > (y)? (x) : (y)) #define PACK(size, alloc) ((size) | (alloc)) #define GET(p) (*(unsigned int *)(p)) #define PUT(p, val) (*(unsigned int *)(p) = (val)) #define GET_SIZE(p) (GET(p) & ~0x7) #define GET_ALLOC(p) (GET(p) & 0x1) #define HDRP(bp) ((char *)(bp) - WSIZE) #define FTRP(bp) ((char *)(bp) + GET_SIZE(HDRP(bp)) - DSIZE) #define NEXT_BLKP(bp) ((char *)(bp) + GET_SIZE(((char *)(bp) - WSIZE))) #define PREV_BLKP(bp) ((char *)(bp) - GET_SIZE(((char *)(bp) - DSIZE)))
注释给出了每个宏的意义。
一些额外的定义:
1 2 3 4 5 6 static void *free_list_head = NULL ; static void *extend_heap (size_t words) ; static void *coalesce (void *bp) ; static void *find_fit (size_t size) ; static void place (void *bp, size_t size) ;
mm_init·
这个函数对mm做初始化,工作包括:
分配4个字,第0个字为pad,为了后续分配的块payload首地址能够是8字节对齐。
第1-2个字为序言块,free_list_head指向这里,相当于给list一个定义,不然我们从哪里开始search呢?
第3个字,结尾块,主要用于确定尾边界。
extend_heap, 分配一大块heap,用于后续malloc请求时分配。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 int mm_init (void ) { if ( (free_list_head = mem_sbrk(4 * WSIZE)) == (void *)-1 ){ return -1 ; } PUT(free_list_head, 0 ); PUT(free_list_head + (1 * WSIZE), PACK(DSIZE, 1 )); PUT(free_list_head + (2 * WSIZE), PACK(DSIZE, 1 )); PUT(free_list_head + (3 * WSIZE), PACK(0 , 1 )); free_list_head += (2 * WSIZE); if (extend_heap(CHUNKSIZE/WSIZE) == NULL ){ return -1 ; } return 0 ; }
extend_heap·
工作:
size更新,保证size为偶数个word
为当前分配的block添加元数据,即header和footer信息
更新尾边界
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 static void *extend_heap (size_t words) { char *bp; size_t size; size = (words % 2 ) ? (words + 1 ) * WSIZE : words * WSIZE; if ( (long )(bp = mem_sbrk(size)) == -1 ){ return NULL ; } PUT(HDRP(bp), PACK(size, 0 )); PUT(FTRP(bp), PACK(size, 0 )); PUT(HDRP(NEXT_BLKP(bp)), PACK(0 , 1 )); return coalesce(bp); }
mm_malloc·
mm_malloc也比较简单,首先更改请求size,满足8字节对齐+元数据的开销要求。接着尝试找到当前可用heap中是否有能够满足本次请求的block,有则直接place,无则需要扩展当前可用heap的大小,扩展后再place。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 void *mm_malloc (size_t size) { size_t asize; size_t extendsize; char *bp; if (size == 0 ) return NULL ; if (size <= DSIZE) { asize = 2 * DSIZE; } else { asize = DSIZE * ((size + (DSIZE) + (DSIZE - 1 )) / DSIZE); } if ((bp = find_fit(asize)) != NULL ) { place(bp, asize); } else { extendsize = MAX(asize, CHUNKSIZE); if ((bp = extend_heap(extendsize / WSIZE)) == NULL ) { return NULL ; } place(bp, asize); } #ifdef DEBUG printf ("malloc\n" ); print_allocated_info(); #endif return bp; }
find_fit·
遍历整个list,找到还未分配且满足当前请求大小的block,然后返回该block的首地址。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 static void *find_fit (size_t size) { void *bp ; for (bp = NEXT_BLKP(free_list_head); GET_SIZE(HDRP(bp)) > 0 ; bp = NEXT_BLKP(bp)) { if (GET_ALLOC(HDRP(bp)) == 0 && size <= GET_SIZE(HDRP(bp))) { return bp; } } return NULL ; }
place·
place的工作也很简单:
最小块大小(2*DSIZE) <= 当前块的大小-当前请求的块大小 ,则对当前block做split
否则,直接place即可。
现在继续看看free:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 static void place (void *bp, size_t size) { size_t remain_size; size_t origin_size; origin_size = GET_SIZE(HDRP(bp)); remain_size = origin_size - size; if (remain_size >= 2 *DSIZE) { PUT(HDRP(bp), PACK(size, 1 )); PUT(FTRP(bp), PACK(size, 1 )); PUT(HDRP(NEXT_BLKP(bp)), PACK(remain_size, 0 )); PUT(FTRP(NEXT_BLKP(bp)), PACK(remain_size, 0 )); }else { PUT(HDRP(bp), PACK(origin_size, 1 )); PUT(FTRP(bp), PACK(origin_size, 1 )); } }
mm_free·
可以看到,free也是相当简单的,将当前block的分配状态从1更新到0即可。然后做coalesce操作:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 void mm_free (void *ptr) { size_t size = GET_SIZE(HDRP(ptr)); PUT(HDRP(ptr), PACK(size, 0 )); PUT(FTRP(ptr), PACK(size, 0 )); coalesce(ptr); #ifdef DEBUG printf ("free\n" ); print_allocated_info(); #endif }
coalesce·
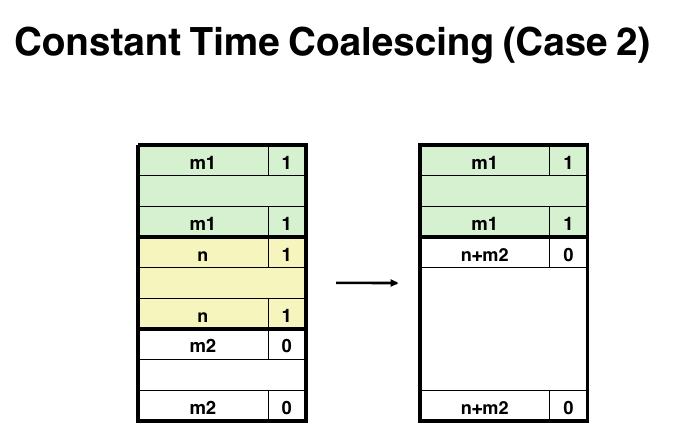
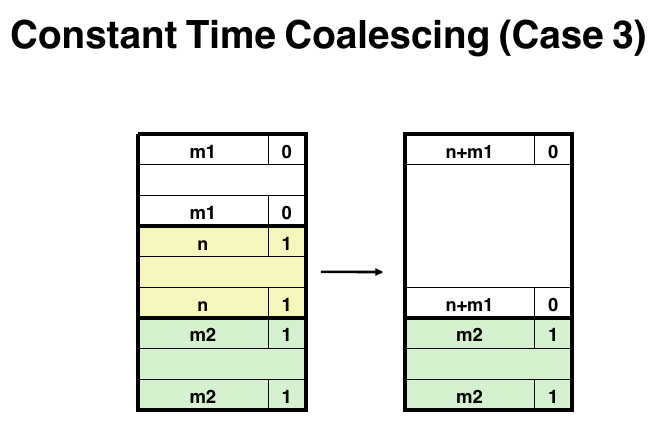
free block后要考虑前后是否也有free block, 如果存在free block需要进行合并.下面给出了4种情况:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 static void *coalesce (void *bp) { size_t pre_alloc = GET_ALLOC(HDRP(PREV_BLKP(bp))); size_t next_alloc = GET_ALLOC(HDRP(NEXT_BLKP(bp))); size_t size = GET_SIZE(HDRP(bp)); if (pre_alloc && next_alloc){ return bp; } else if (pre_alloc && !next_alloc){ void *next_block = NEXT_BLKP(bp); size += GET_SIZE(HDRP(next_block)); PUT(HDRP(bp), PACK(size, 0 )); PUT(FTRP(next_block), PACK(size, 0 )); } else if (!pre_alloc && next_alloc){ size += GET_SIZE(HDRP(PREV_BLKP(bp))); PUT(FTRP(bp), PACK(size, 0 )); PUT(HDRP(PREV_BLKP(bp)), PACK(size, 0 )); bp = PREV_BLKP(bp); } else { size += GET_SIZE(HDRP(PREV_BLKP(bp))) + GET_SIZE(FTRP(NEXT_BLKP(bp))); PUT(HDRP(PREV_BLKP(bp)), PACK(size, 0 )); PUT(FTRP(NEXT_BLKP(bp)), PACK(size, 0 )); bp = PREV_BLKP(bp); } return bp; }
mm_realloc·
realloc函数实现也很简单, 重新分配size大小的块,然后将旧块内容复制到新块内容上. 注意这里也考虑了block变小的情况.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 void *mm_realloc (void *ptr, size_t size) { void *oldptr = ptr; void *newptr; size_t copySize; newptr = mm_malloc(size); if (newptr == NULL ) return NULL ; copySize = GET_SIZE(HDRP(oldptr)); if (size < copySize) copySize = size; memcpy (newptr, oldptr, copySize); mm_free(oldptr); return newptr; }
ok, 以上就是implicit list的所有内容, 下面我们开始讲解explicit list的实现.
4. explicit list·
explicit list和implicit list的区别在于前者在 逻辑空间 中维护一个free list, 里面只保存free的blocks, 而后者则是在 虚拟地址空间 中维护整个list,里面即包含了free blocks也包含了allocated blocks. 当然了, explicit list底层也是虚拟地址空间.下面这张图给出了explicit list的上层结构:
下面给出implicit和explicit的每一块的具体结构对比:
可以看到,explicit比较implicit,每一个块只是多了两个字段,用于保存下一个free block的地址(next)和上一个free block的地址(prev).
想一下,explict的优点: 大大提高搜索free block的效率. 但是实现复杂度比implicit难,因为多一个逻辑空间的操作.
首先第一个问题,next和prev占用多大空间? 对于32位的os来说,地址空间的编址大小的32位(4字节), 64位的os则位64位(8字节). 为了简单起见,本文中只考虑32位的情况(gcc编译时加上-m32的参数,默认的makefile已经给出).
好的现在确定了next和prev的大小,再来确定一个最小块的大小,最小块应该包含header+footer+next+prev+payload,其中payload最小为1个字节, 同时最小块应该保证8字节对齐要求,综合以上所述,一个最小块为:
$$
4+4+4+1+4=17,向上取8字节对齐,则\
MIN_BLOCK = 24
$$
ok,现在再说明代码中做的一些规定:
find策略,采用first-fit策略
对于free后的block应该如何重新插入free list, 本文采用LIFO策略
对齐约定, 8字节对齐
有了以上的说明, 差不多就可以写代码了,先从定义的宏出发:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 #define ALIGNMENT 8 #define ALIGN(size) (((size) + (ALIGNMENT - 1)) & ~0x7) #define SIZE_T_SIZE (ALIGN(sizeof(size_t))) #define WSIZE 4 #define DSIZE 8 #define CHUNKSIZE (1 << 12) #define MAX(x, y) ((x) > (y) ? (x) : (y)) #define PACK(size, alloc) ((size) | (alloc)) #define GET(p) (*(unsigned int *)(p)) #define PUT(p, val) (*(unsigned int *)(p) = (unsigned int)(val)) #define GET_SIZE(p) (GET(p) & ~0x7) #define GET_ALLOC(p) (GET(p) & 0x1) #define HDRP(bp) ((char *)(bp)-3 * WSIZE) #define FTRP(bp) ((char *)(bp) + GET_SIZE(HDRP(bp)) - 4 * WSIZE) #define NEXT_PTR(bp) ((char *)(bp)-2 * WSIZE) #define PREV_PTR(bp) ((char *)(bp)-WSIZE) #define NEXT_FREE_BLKP(bp) ((char *)(*(unsigned int *)(NEXT_PTR(bp)))) #define PREV_FREE_BLKP(bp) ((char *)(*(unsigned int *)(PREV_PTR(bp)))) #define NEXT_BLKP(bp) ((char *)(bp) + GET_SIZE(HDRP(bp))) #define PREV_BLKP(bp) ((char *)(bp)-GET_SIZE(HDRP(bp) - WSIZE))
可以看到, 基本上和implicit的宏差不多, 只是多了NEXT_FREE_BLKP这类宏, 由于调整了每个block的具体layout(多了next和prev), 所以一些运算,如HDRP等需要对应调整.
然后就是各个函数:
NOTE: 再次注意存在逻辑空间和虚拟地址空间两个空间.
mm_init·
这个函数的主要工作包括:
分配 一个word+ MIN_BLOCK
第一个word是做pad用,用于保证后续分配的block能够8字节对齐,和implicit一样.
后面的MIN_BLOCK用于作为free_list_head, 和impilicit的序言块作用相同
最后分配一个CHUNK,分配函数的内部会将这个chunk块插入到free list 中.
整体来说,explicit的mm_init和implicit的mm_init作用相同,但是组织方式发生了一些变化.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 int mm_init (void ) { char *init_block_p; if ((init_block_p = mem_sbrk(MIN_BLOCK + WSIZE)) == (void *)-1 ) { return -1 ; } init_block_p = (char *)(init_block_p) + WSIZE; free_list_head = init_block_p + 3 * WSIZE; PUT(PREV_PTR(free_list_head), NULL ); PUT(NEXT_PTR(free_list_head), NULL ); PUT(HDRP(free_list_head), PACK(MIN_BLOCK, 1 )); PUT(FTRP(free_list_head), PACK(MIN_BLOCK, 1 )); if ((allocate_from_chunk(CHUNKSIZE)) == NULL ) { return -1 ; } return 0 ; }
allocate_from_heap·
allocate_from_heap做的工作很简单, 扩展heap大小, 然后将扩展出来的block插入到free_lilst中.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 static void *allocate_from_heap (size_t size) { void *cur_bp = NULL ; size_t extend_size = MAX(size, CHUNKSIZE); if ((cur_bp = extend_heap(extend_size / WSIZE)) == NULL ) { return NULL ; } insert_to_free_list(cur_bp); return cur_bp; }
extend_heap·
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 static void *extend_heap (size_t words) { char *bp; size_t size; size = (words % 2 ) ? (words + 1 ) * WSIZE : words * WSIZE; if ((long )(bp = mem_sbrk(size)) == -1 ) { return NULL ; } bp = (char *)(bp) + 3 * WSIZE; PUT(HDRP(bp), PACK(size, 0 )); PUT(FTRP(bp), PACK(size, 0 )); return bp; }
insert_to_free_list·
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 static void insert_to_free_list (void *bp) { void *head = free_list_head; void *p = NEXT_FREE_BLKP(head); if (p == NULL ) { PUT(NEXT_PTR(head), bp); PUT(NEXT_PTR(bp), NULL ); PUT(PREV_PTR(bp), head); } else { PUT(NEXT_PTR(bp), p); PUT(PREV_PTR(bp), head); PUT(NEXT_PTR(head), bp); PUT(PREV_PTR(p), bp); } }
采用LIFO策略,将bp所指向的block插入到free_list中.
mm_malloc·
注释中说了本函数的工作. 首先从free_list中看有没有适合的块, 否则从heap中分配.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 void *mm_malloc (size_t size) { size_t asize; char *bp; if (size == 0 ) return NULL ; asize = ALIGN(2 * DSIZE + size); if ((bp = find_fit(asize)) != NULL ) { place(bp, asize); } else { if ((bp = allocate_from_heap(asize)) == NULL ) { return NULL ; } place(bp, asize); } #ifdef DEBUG printf ("malloc\n" ); debug(); #endif return bp; }
find_fit·
从free list中找到第一个满足需求size的free block并返回该block的payload首地址.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 static void *find_fit (size_t size) { void *bp; for (bp = NEXT_FREE_BLKP(free_list_head); bp != NULL && GET_SIZE(HDRP(bp)) > 0 ; bp = NEXT_FREE_BLKP(bp)) { if (GET_ALLOC(HDRP(bp)) == 0 && size <= GET_SIZE(HDRP(bp))) { return bp; } } return NULL ; }
place·
本函数实现,将bp所指向的free block在可能的情况下做split.具体来说,是当当前free block的size >= 请求size+最小block时会做split.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 static void place (void *bp, size_t size) { size_t origin_size; size_t remain_size; origin_size = GET_SIZE(HDRP(bp)); remain_size = origin_size - size; if (remain_size >= MIN_BLOCK) { char *remain_blockp = (char *)(bp) + size; PUT(HDRP(remain_blockp), PACK(remain_size, 0 )); PUT(FTRP(remain_blockp), PACK(remain_size, 0 )); char *prev_blockp = PREV_FREE_BLKP(bp); char *next_blockp = NEXT_FREE_BLKP(bp); PUT(NEXT_PTR(remain_blockp), next_blockp); PUT(PREV_PTR(remain_blockp), prev_blockp); PUT(NEXT_PTR(prev_blockp), remain_blockp); if (next_blockp != NULL ) { PUT(PREV_PTR(next_blockp), remain_blockp); } PUT(HDRP(bp), PACK(size, 1 )); PUT(FTRP(bp), PACK(size, 1 )); PUT(NEXT_PTR(bp), NULL ); PUT(PREV_PTR(bp), NULL ); } else { PUT(HDRP(bp), PACK(origin_size, 1 )); PUT(FTRP(bp), PACK(origin_size, 1 )); delete_from_free_list(bp); } }
delete_from_free_list·
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 static void delete_from_free_list (void *bp) { void *prev_free_block = PREV_FREE_BLKP(bp); void *next_free_block = NEXT_FREE_BLKP(bp); if (next_free_block == NULL ) { PUT(NEXT_PTR(prev_free_block), NULL ); } else { PUT(NEXT_PTR(prev_free_block), next_free_block); PUT(PREV_PTR(next_free_block), prev_free_block); PUT(NEXT_PTR(bp), NULL ); PUT(PREV_PTR(bp), NULL ); } }
mm_free·
这里的free函数和implicit list的free函数一致,重点在coalesce函数.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 void mm_free (void *ptr) { size_t size = GET_SIZE(HDRP(ptr)); PUT(HDRP(ptr), PACK(size, 0 )); PUT(FTRP(ptr), PACK(size, 0 )); coalesce(ptr); #ifdef DEBUG printf ("free\n" ); debug(); #endif }
coalesce·
coalesce是每种分配器的重点,需要考虑如何合并在虚拟地址空间中的相邻blocks之间的关系, 和implicit一样,explicit也有4种情况:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 static void coalesce (void *bp) { char *prev_blockp = PREV_BLKP(bp); char *next_blockp = NEXT_BLKP(bp); char *mem_max_addr = (char *)mem_heap_hi() + 1 ; size_t prev_alloc = GET_ALLOC(HDRP(prev_blockp)); size_t next_alloc; if (next_blockp >= mem_max_addr) { if (!prev_alloc) { case3(bp); } else { case1(bp); } } else { next_alloc = GET_ALLOC(HDRP(next_blockp)); if (prev_alloc && next_alloc) { case1(bp); } else if (!prev_alloc && next_alloc) { case3(bp); } else if (prev_alloc && !next_alloc) { case2(bp); } else { case4(bp); } } }
case1·
1 2 3 4 5 6 7 8 9 10 11 static void *case1 (void *bp) { insert_to_free_list(bp); return bp; }
case2·
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 static void *case2 (void *bp) { void *next_blockp = NEXT_BLKP(bp); void *prev_free_blockp; void *next_free_blockp; size_t size = GET_SIZE(HDRP(bp)) + GET_SIZE(HDRP(next_blockp)); PUT(HDRP(bp), PACK(size, 0 )); PUT(FTRP(next_blockp), PACK(size, 0 )); prev_free_blockp = PREV_FREE_BLKP(next_blockp); next_free_blockp = NEXT_FREE_BLKP(next_blockp); if (next_free_blockp == NULL ) { PUT(NEXT_PTR(prev_free_blockp), NULL ); } else { PUT(NEXT_PTR(prev_free_blockp), next_free_blockp); PUT(PREV_PTR(next_free_blockp), prev_free_blockp); } insert_to_free_list(bp); return bp; }
case3·
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 static void *case3 (void *bp) { char *prev_blockp = PREV_BLKP(bp); char *prev_free_blockp; char *next_free_blockp; size_t size = GET_SIZE(HDRP(bp)) + GET_SIZE(HDRP(prev_blockp)); PUT(HDRP(prev_blockp), PACK(size, 0 )); PUT(FTRP(prev_blockp), PACK(size, 0 )); next_free_blockp = NEXT_FREE_BLKP(prev_blockp); prev_free_blockp = PREV_FREE_BLKP(prev_blockp); if (next_free_blockp == NULL ) { PUT(NEXT_PTR(prev_free_blockp), NULL ); } else { PUT(NEXT_PTR(prev_free_blockp), next_free_blockp); PUT(PREV_PTR(next_free_blockp), prev_free_blockp); } insert_to_free_list(prev_blockp); return bp; }
case4·
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 static void *case4 (void *bp) { void *prev_blockp; void *prev1_free_blockp; void *next1_free_blockp; void *next_blockp; void *prev2_free_blockp; void *next2_free_blockp; size_t size; prev_blockp = PREV_BLKP(bp); next_blockp = NEXT_BLKP(bp); size_t size1 = GET_SIZE(HDRP(prev_blockp)); size_t size2 = GET_SIZE(HDRP(bp)); size_t size3 = GET_SIZE(HDRP(next_blockp)); size = size1 + size2 + size3; PUT(HDRP(prev_blockp), PACK(size, 0 )); PUT(FTRP(next_blockp), PACK(size, 0 )); bp = prev_blockp; prev1_free_blockp = PREV_FREE_BLKP(prev_blockp); next1_free_blockp = NEXT_FREE_BLKP(prev_blockp); if (next1_free_blockp == NULL ) { PUT(NEXT_PTR(prev1_free_blockp), NULL ); } else { PUT(NEXT_PTR(prev1_free_blockp), next1_free_blockp); PUT(PREV_PTR(next1_free_blockp), prev1_free_blockp); } prev2_free_blockp = PREV_FREE_BLKP(next_blockp); next2_free_blockp = NEXT_FREE_BLKP(next_blockp); if (next2_free_blockp == NULL ) { PUT(NEXT_PTR(prev2_free_blockp), NULL ); } else { PUT(NEXT_PTR(prev2_free_blockp), next2_free_blockp); PUT(PREV_PTR(next2_free_blockp), prev2_free_blockp); } insert_to_free_list(bp); return bp; }
其余debug用的函数·
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 static void debug () { print_allocated_info(); print_free_blocks_info(); consistent_check(); } static void print_allocated_info () { char *bp; size_t idx = 0 ; char *mem_max_addr = mem_heap_hi(); printf ("=============start allocated info===========\n" ); for (bp = NEXT_BLKP(free_list_head); bp < mem_max_addr && GET_SIZE(HDRP(bp)) > 0 ; bp = NEXT_BLKP(bp)) { if (GET_ALLOC(HDRP(bp)) == 1 ) { ++idx; printf ("block%d range %p %p size=%d, payload %p %p block size=%d\n" , idx, HDRP(bp), FTRP(bp) + WSIZE, FTRP(bp) - HDRP(bp) + WSIZE, (char *)bp, FTRP(bp), FTRP(bp) - (char *)(bp)); } } printf ("=============end allocated info===========\n\n" ); } static void consistent_check () { char *bp; char *mem_max_heap = mem_heap_hi(); for (bp = NEXT_FREE_BLKP(free_list_head); bp != NULL ; bp = NEXT_FREE_BLKP(bp)) { if (GET_ALLOC(HDRP(bp))) { printf ("%d free list中存在块已分配\n" , __LINE__); } } for (bp = NEXT_BLKP(free_list_head); bp <= mem_max_heap; bp = NEXT_BLKP(bp)) { if (!GET_ALLOC(HDRP(bp)) && !is_in_free_list(bp)) { printf ("%d 存在free block %p 不在free list中\n" , __LINE__, bp); } } } static int is_in_free_list (void *bp) { void *p; for (p = NEXT_FREE_BLKP(free_list_head); p != NULL ; p = NEXT_FREE_BLKP(p)) { if (p == bp) { return 1 ; } } return 0 ; }
上面就是整个explicit list的实现了. 最终实现的效果是,跑完所有trace file,得分 83/100. 算是个良水平吧. 要想实现优秀水平,可以考虑做做segregated list或者red block tree list.
再谈一些优化:
空间优化,对于分配的block, 可以不存储NEXT和PREV指针, 从而扩大payload空间,提高空间利用率.
封装整个free list, 然后改用segregated list.
现在search策略是从头search到尾部, ,比较慢,可以针对每个free block建立index, index数据结构选择rbtree, 应该可以大大提高分配吞吐量.
5. 总结·
嗯, 个人觉得这个lab仅次于cachelab, 但是它的难点不在于思路,而在于如何调试,毕竟像我这样的菜鸡,不debug是不可能,这辈子都不可能不debug的, 而这次lab有很多macros, 就很难在gdb中调试,gdb中也只能通过exam命令查看连续的地址内存空间, 但是当trace file中给定的malloc size过大时, exam命令也很难快速查看, 所以个人在做的时候, 将trace file的malloc size手动改小了(当然后面还是改回去了的),然后debug就会相对轻松一些.
再谈谈收获, 总算清晰的知道了什么是虚拟内存,页表,TLB,为什么要设计它们,它们有什么好处. 也知道了malloc的基本工作原理, 现在想想这些技术也不是离我们那么遥远, 继续加油吧, 下一个lab是网络相关的了, 不过下一次lab又得暂停一阵子了, 项目的事情让人心累…