MAP_SHARED: Share this mapping. Updates to the mapping are visible to other processes mapping the same region, and (in the case of file-backed mappings) are carried through to the underlying file. 即更新对其他process可见,更新会写会被映射的文件。
MAP_PRIVATE: Create a private copy-on-write mapping. Updates to the mapping are not visible to other processes mapping the same file, and are not carried through to the underlying file. It is unspecified whether changes made to the file after the mmap() call are visible in the mapped region. 即更新对其他process是不可见的,更新不会写回被映射的文件,更新采用都会在自身独有的copy上执行。
if (argint(1, &len) < 0 || argint(2, &prot) < 0 || argint(3, &flags) < 0 || argint(4, &fd) < 0 || argint(5, &off) < 0) return-1; // check whether the file is opened or not cur_proc = myproc(); if (fd < 0 || fd >= NOFILE || cur_proc->ofile[fd] == 0) { return-1; } // check whether the perm of prot is the subset of the perm of the file or not file = cur_proc->ofile[fd]; if (prot & PROT_READ) { if (!file->readable) { return-1; } } if ((flags & MAP_SHARED) && (prot & PROT_WRITE)) { // MAP_SHARED flag with PROT_WRITE indicates file must be writeable if (!file->writable) { return-1; } }
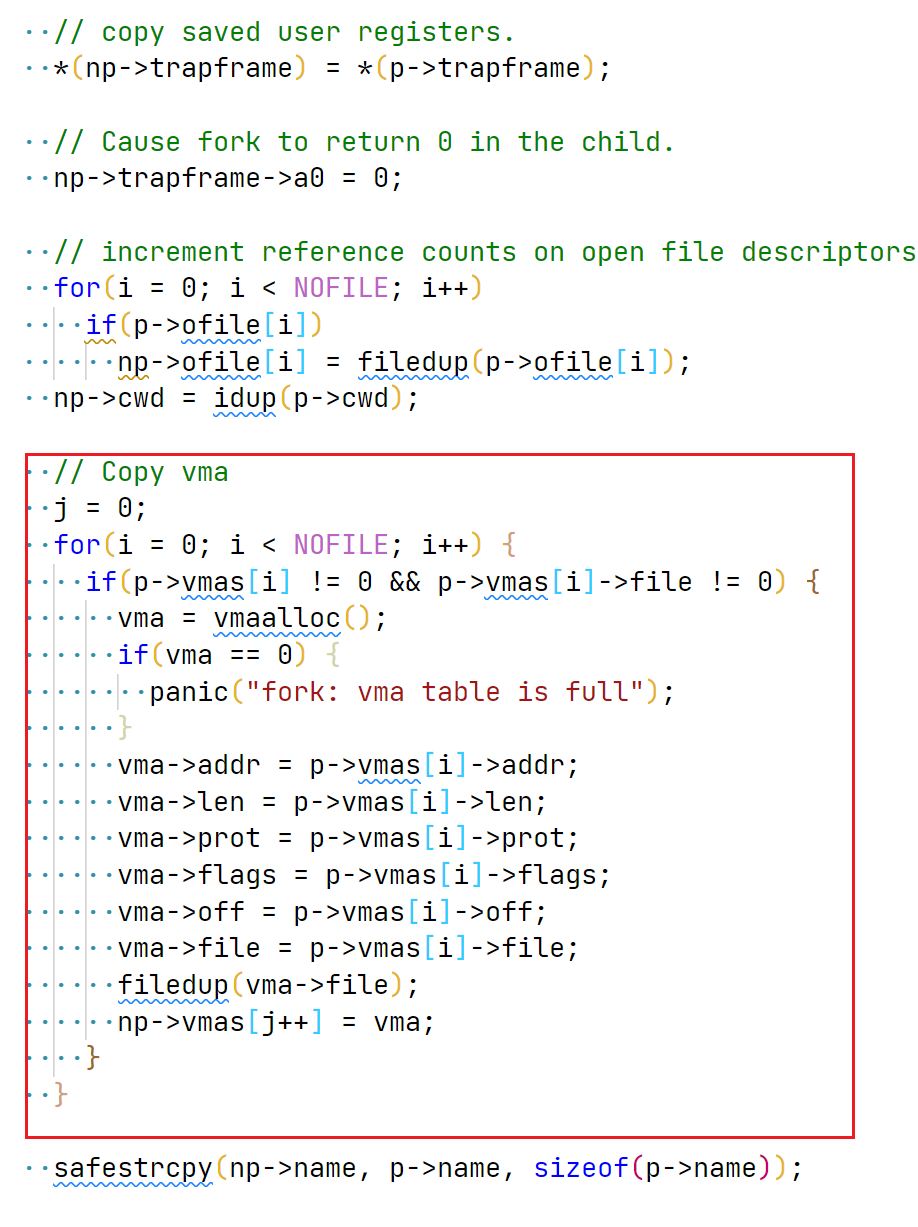
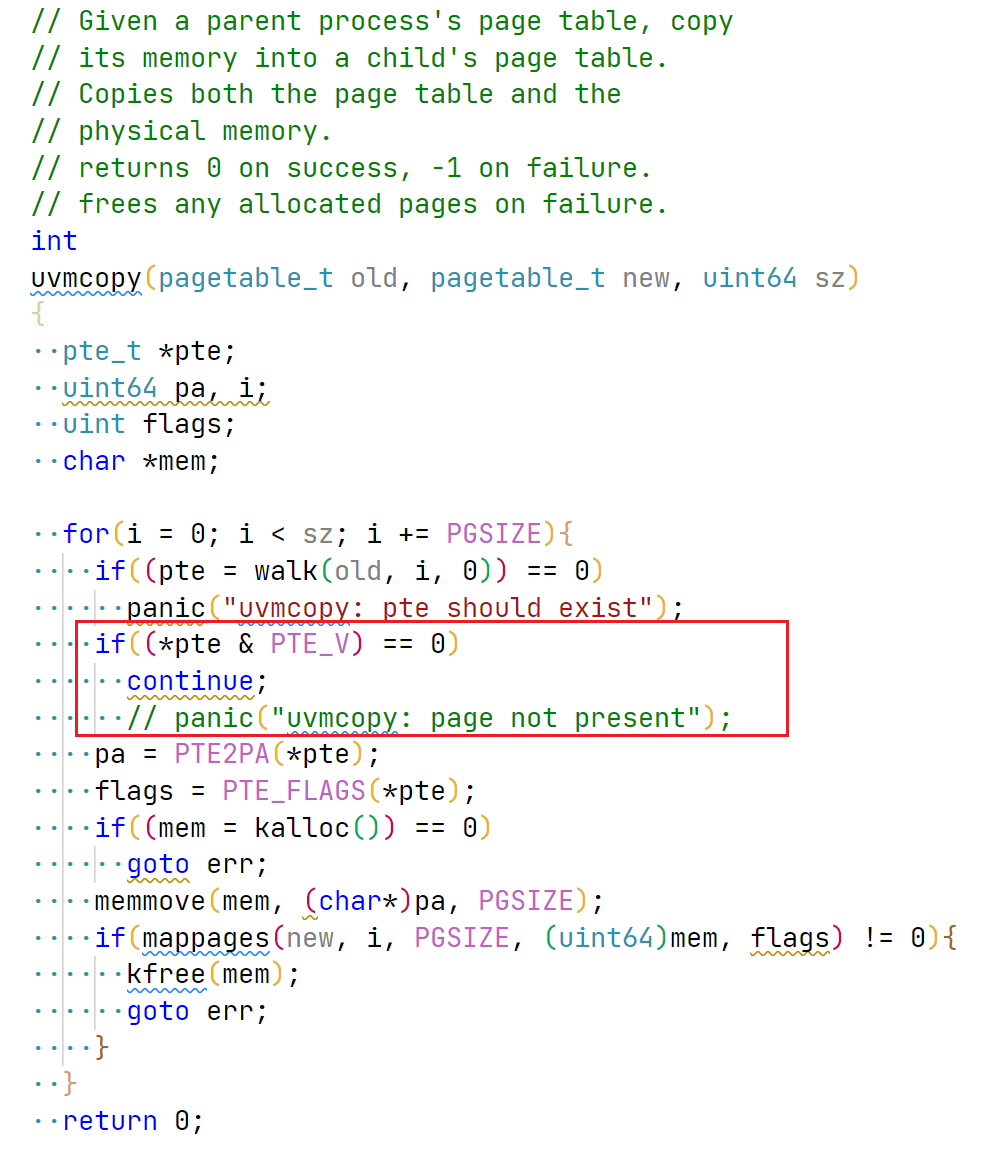
// allocate a vma if((vma = vmaalloc()) == 0) { panic("vmaalloc failed"); return-1; } vma->addr = 0; // init addr: see code below vma->len = len; vma->prot = prot; vma->flags = flags; vma->off = off; vma->file = file; filedup(vma->file); // increase file refcnt so that it's impossible to free the file
acquire(&cur_proc->lock); // find the first continuous addr space in user page table so that this mapping can be mapped successfully uint64 sz = cur_proc->sz; // 向上页对齐, 如果不对齐,后续的page fualt handler使用的va可能低于addr uint64 start_addr = PGROUNDUP(sz); if(lazy_growproc(cur_proc, len + start_addr - sz) < 0) { release(&cur_proc->lock); fileclose(vma->file); vmafree(vma); return-1; } vma->addr = start_addr;
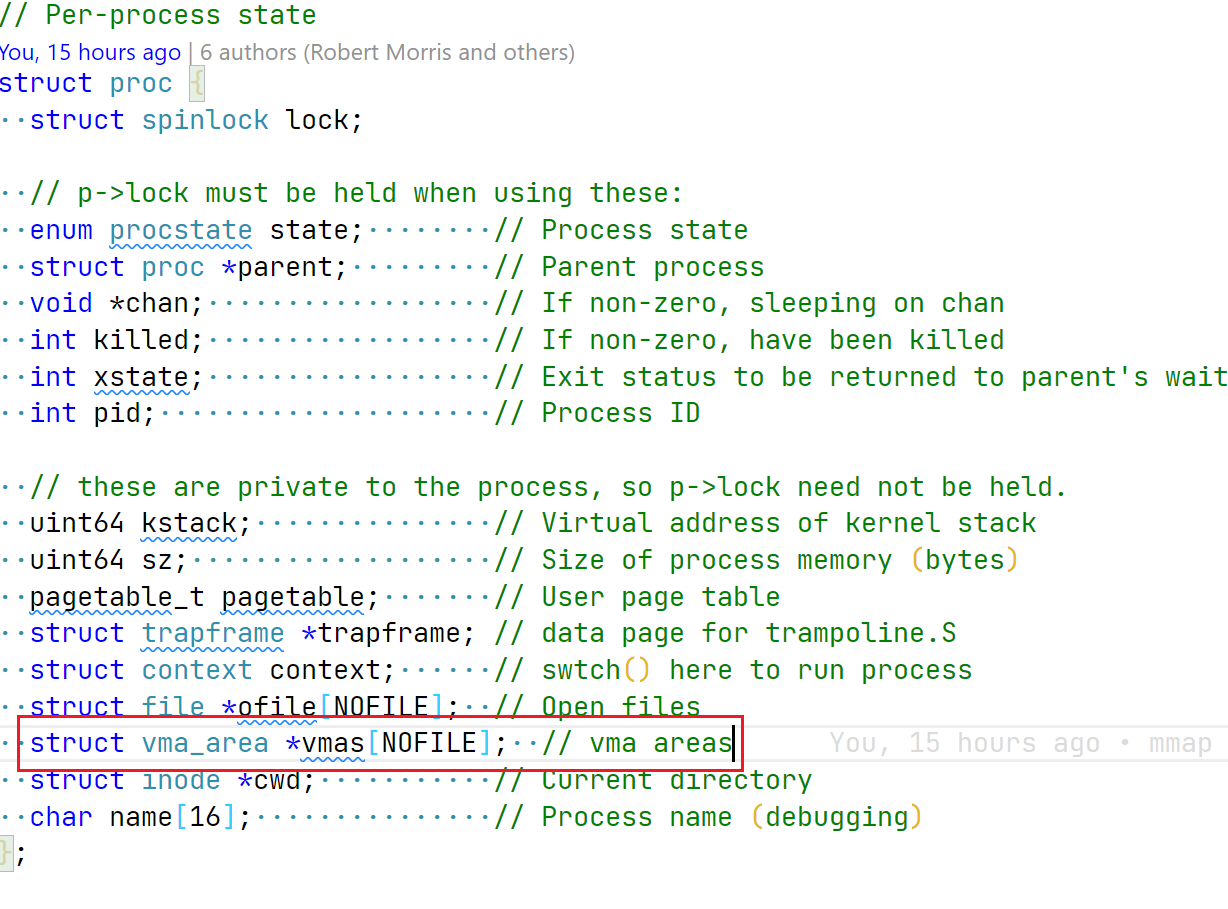
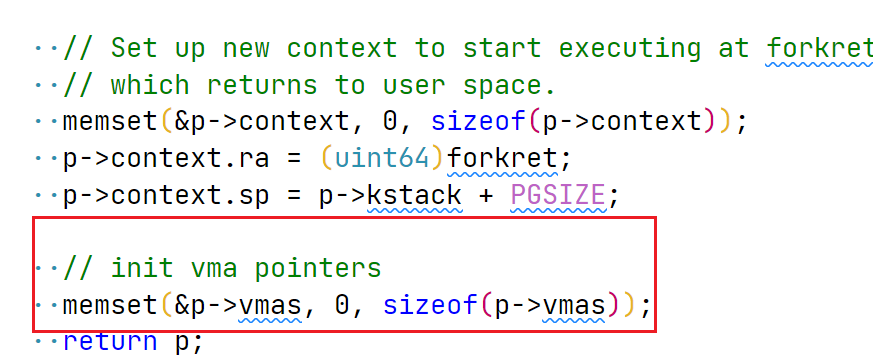
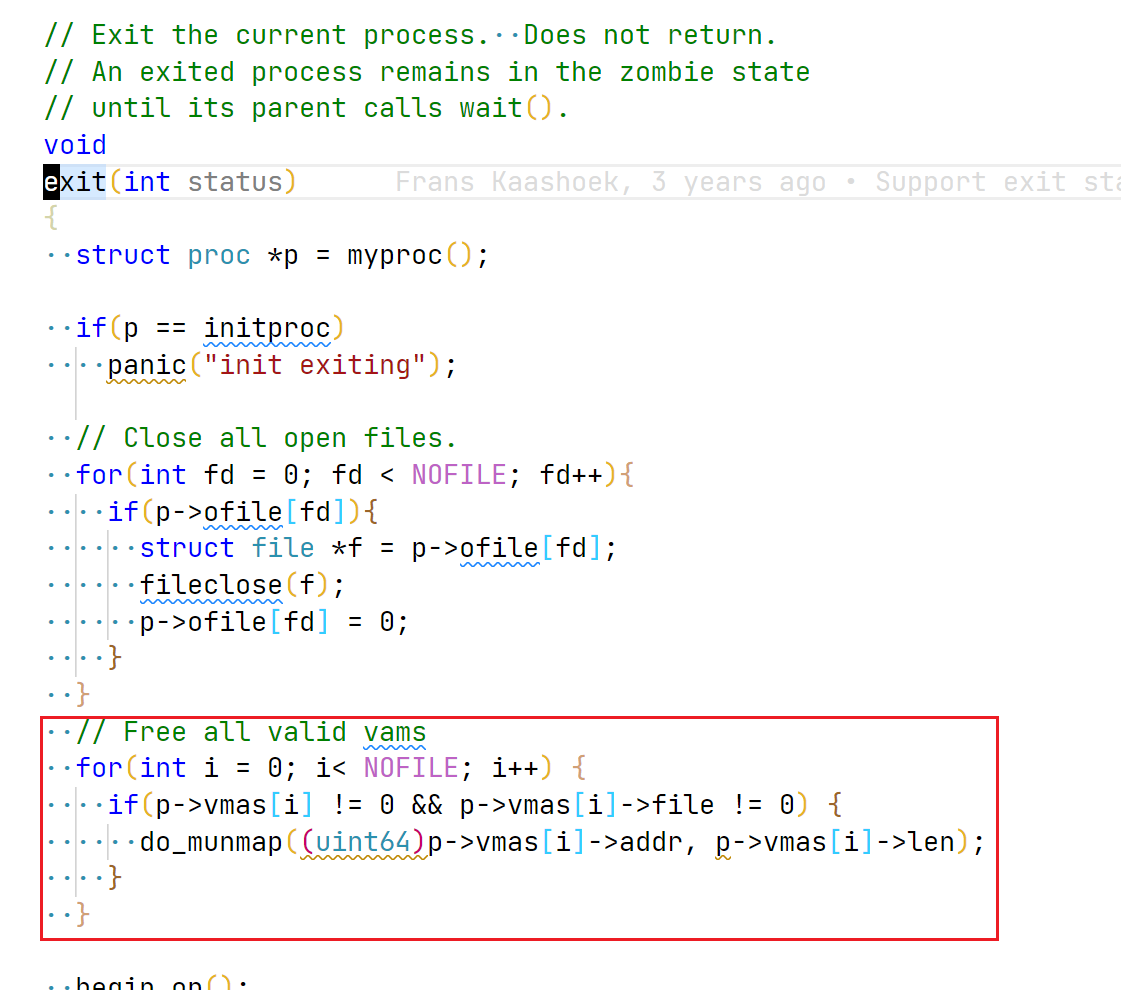
// put the vam structure into proc structure int i; for(i = 0; i< NOFILE; i++) { if(cur_proc->vmas[i] == 0) { cur_proc->vmas[i] = vma; break; } } release(&cur_proc->lock); if(i == NOFILE) { panic("the vmas in proc is full"); return-1; } return start_addr; }
// Increase proc used addr space without allocating physical pages // Return 0 on success, -1 on failure. // NOTE: n must be larger than 0. // NOTE: p.lock should be held intlazy_growproc(struct proc *p, int n) { if(n <= 0) { return-1; } p->sz += n; return0; }