📌本文采用wolai制作,link: https://www.wolai.com/ravenxrz/ty4wvA5PaaHLbgDs4oofRE
前面几篇文章已经把muduo最核心的链路分析完成,包括事件循环、线程池、连接监听、建立,处理的全链路。本篇分析一些其他工具类,包含三个:Buffer、日志和定时器。
Buffer·
Buffer类是muduo自实现的网络缓冲,用于应用读写与socket读写速度不匹配的问题的:
类主要实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 class Buffer : public muduo::copyable {public : static const size_t kCheapPrepend = 8 ; static const size_t kInitialSize = 1024 ; explicit Buffer (size_t initialSize = kInitialSize) : buffer_(kCheapPrepend + initialSize), readerIndex_(kCheapPrepend), writerIndex_(kCheapPrepend) { assert (readableBytes () == 0 ); assert (writableBytes () == initialSize); assert (prependableBytes () == kCheapPrepend); } size_t readableBytes () const return writerIndex_ - readerIndex_; } size_t writableBytes () const return buffer_.size () - writerIndex_; } size_t prependableBytes () const return readerIndex_; } const char *peek () const return begin () + readerIndex_; } void retrieve (size_t len) assert (len <= readableBytes ()); if (len < readableBytes ()) { readerIndex_ += len; } else { retrieveAll (); } } void retrieveAll () readerIndex_ = kCheapPrepend; writerIndex_ = kCheapPrepend; } void append (const StringPiece &str) append (str.data (), str.size ()); } void append (const char * data, size_t len) ensureWritableBytes (len); std::copy (data, data + len, beginWrite ()); hasWritten (len); } void append (const void * data, size_t len) append (static_cast <const char *>(data), len); } void ensureWritableBytes (size_t len) if (writableBytes () < len) { makeSpace (len); } assert (writableBytes () >= len); } void hasWritten (size_t len) assert (len <= writableBytes ()); writerIndex_ += len; } void unwrite (size_t len) assert (len <= readableBytes ()); writerIndex_ -= len; } void prepend (const void * data, size_t len) assert (len <= prependableBytes ()); readerIndex_ -= len; const char *d = static_cast <const char *>(data); std::copy (d, d + len, begin () + readerIndex_); } ssize_t readFd (int fd, int *savedErrno) private : void makeSpace (size_t len) if (writableBytes () + prependableBytes () < len + kCheapPrepend) { buffer_.resize (writerIndex_ + len); } else { assert (kCheapPrepend < readerIndex_); size_t readable = readableBytes (); std::copy (begin () + readerIndex_, begin () + writerIndex_, begin () + kCheapPrepend); readerIndex_ = kCheapPrepend; writerIndex_ = readerIndex_ + readable; assert (readable == readableBytes ()); } } private : std::vector<char > buffer_; size_t readerIndex_; size_t writerIndex_; };
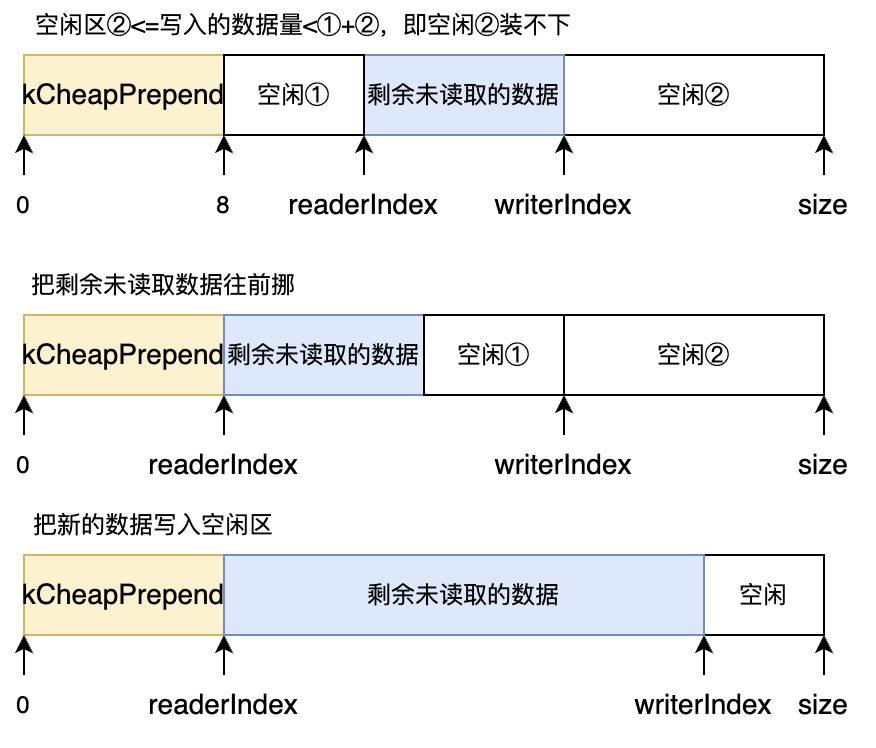
buffer的格式已经在class的注释中包括了,整个buffer分为四段,第一段是预留的8字节,第二段是已经被读取的buffer,第二段是待读取的数据readables, 第三段是已经写入到buffer的数据writeable.
1 | 预留buffer 8B | 已经读完的buffer | 待读buffer | 可写buffer |
重点关注下和读写相关的函数
写接口append·
写入 append:
1 2 3 4 5 6 7 void append (const char * data, size_t len) ensureWritableBytes (len); std::copy (data, data+len, beginWrite ()); hasWritten (len); }
1 2 3 4 5 6 7 8 void ensureWritableBytes (size_t len) if (writableBytes () < len) { makeSpace (len); } assert (writableBytes () >= len); }
当可写入的字节数小于要写入的len,需要扩容,扩容调用makeSpace:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 void makeSpace (size_t len) if (writableBytes () + prependableBytes () < len + kCheapPrepend) { buffer_.resize (writerIndex_+len); } else { assert (kCheapPrepend < readerIndex_); size_t readable = readableBytes (); std::copy (begin ()+readerIndex_, begin ()+writerIndex_, begin ()+kCheapPrepend); readerIndex_ = kCheapPrepend; writerIndex_ = readerIndex_ + readable; assert (readable == readableBytes ()); } }
笔者注:不好评价这样做是否好,扩容肯定是要copy的,但是else分支里面也要copy不是也有开销吗?那直接做成循环buffer,实在不够时再扩容不就好了吗? 不过可以知道的是,后续读数据时有点难处理,因为读的内存可能要分成两段读,memcpy之类的也不太好优化。
扩容完成后,通过std::copy函数将用户数据拷贝一份,最后通过hasWritten函数移动可写指针。
1 2 3 4 5 6 void hasWritten (size_t len) assert (len <= writableBytes ()); writerIndex_ += len; }
看下哪里有调用append:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 void TcpConnection::sendInLoop (const void * data, size_t len) assert (remaining <= len); if (!faultError && remaining > 0 ) { outputBuffer_.append (static_cast <const char *>(data)+nwrote, remaining); if (!channel_->isWriting ()) { channel_->enableWriting (); } } }
在TcpConnection的send循环中会使用到,显然是和发送数据相关了。
读接口peek & retrieve ·
有写应该就能找到读。看下怎么读的:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 void TcpConnection::send (Buffer* buf) if (state_ == kConnected) { if (loop_->isInLoopThread ()) { sendInLoop (buf->peek (), buf->readableBytes ()); buf-> retrieveAll (); } else { } }
1 2 3 4 5 6 7 8 const char * peek () const return begin () + readerIndex_; }size_t readableBytes () const return writerIndex_ - readerIndex_; }
用户通过peek函数获取当前待读的起点位置,并通过readableBytes可知当前有多少bytes没有读,最后通过retrieve函数标记当前已经读取了多少。
写接口 readFd·
写接口readFd是相对Buffer本身而言的,含义是我们从fd中read一部分数据写到buffer中。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 ssize_t Buffer::readFd (int fd, int * savedErrno) char extrabuf [65536 ]; struct iovec vec[2 ]; const size_t writable = writableBytes (); vec[0 ].iov_base = begin ()+writerIndex_; vec[0 ].iov_len = writable; vec[1 ].iov_base = extrabuf; vec[1 ].iov_len = sizeof extrabuf; const int iovcnt = (writable < sizeof extrabuf) ? 2 : 1 ; const ssize_t n = sockets:: readv (fd, vec, iovcnt); if (n < 0 ) { *savedErrno = errno; } else if (implicit_cast <size_t >(n) <= writable) { writerIndex_ += n; } else { writerIndex_ = buffer_.size (); append (extrabuf, n - writable); } return n; }
这里有个值得借鉴的技巧,muduo在stack上开了一个64kb的stack buffer,如果当前可写size小于64k,则直接拿内存中std::vector表示的那段可写buffer去读,否则带上额外的stack buffer去读。这样一次sockets::readv最多读 64k-1 + 64k=128k-1的长度。
从这里也可以推断出,muduo一定是使用的 epoll + LT的工作模式,因为并没有完全读完,后续的读通过LT模式的epoll_wait事件继续回来读。
思考Buffer的优缺点·
优点:从例子来看优点, 还是以TcpConnection::sendInLoop来分析:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 void TcpConnection::sendInLoop (const void * data, size_t len) loop_->assertInLoopThread (); ssize_t nwrote = 0 ; size_t remaining = len; bool faultError = false ; if (state_ == kDisconnected) { LOG_WARN << "disconnected, give up writing" ; return ; } if (!channel_->isWriting () && outputBuffer_.readableBytes () == 0 ) { nwrote = sockets::write (channel_->fd (), data, len); if (nwrote >= 0 ) { remaining = len - nwrote; if (remaining == 0 && writeCompleteCallback_) { loop_->queueInLoop (std::bind (writeCompleteCallback_, shared_from_this ())); } } else { nwrote = 0 ; if (errno != EWOULDBLOCK) { LOG_SYSERR << "TcpConnection::sendInLoop" ; if (errno == EPIPE || errno == ECONNRESET) { faultError = true ; } } } } assert (remaining <= len); if (!faultError && remaining > 0 ) { outputBuffer_.append (static_cast <const char *>(data)+nwrote, remaining); if (!channel_->isWriting ()) { channel_->enableWriting (); } } }
如果socket write响应不过来,又没有buffer机制,可选的就是一个while循环一直死等发送,这会卡线程!,有buffer,只用将没有发送完的数据copy一份到buffer中,线程没有阻塞,可以去玩其他的。要注意这个线程可是EventLoop的线程,卡住这个线程,其他事件也被卡住了。
缺点: 数据都额外多copy的一份,有开销,有些高性能场景可能并不需要这个buffer,类似polling的模式,直接Run To Complete(不过既然配合了epoll的模式,配上buffer应该会更好)。
TODO·
[ ] kCheapPrepend 这部分预留出来的8B,用来干嘛的?
muduo采用了流式日志,一个典型的用法如下:
1 2 3 4 LOG_INFO << conn->peerAddress ().toIpPort () << " -> " << conn->localAddress ().toIpPort () << " is " << (conn->connected () ? "UP" : "DOWN" );
看下实现:
1 2 3 #define LOG_INFO if (muduo::Logger::logLevel() <= muduo::Logger::INFO) \ muduo::Logger(__FILE__, __LINE__).stream()
转调用:
1 2 LogStream& stream () { return impl_.stream_; }
impl_实现类:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 class Impl { public : typedef Logger::LogLevel LogLevel; Impl (LogLevel level, int old_errno, const SourceFile& file, int line); void formatTime () void finish () Timestamp time_; LogStream stream_; LogLevel level_; int line_; SourceFile basename_; }; Impl impl_;
所以职责转到了LogStream:
LogStream·
实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 class LogStream : noncopyable{ typedef LogStream self; public : typedef detail::FixedBuffer<detail::kSmallBuffer> Buffer; self& operator <<(bool v) { buffer_.append (v ? "1" : "0" , 1 ); return *this ; } self& operator <<(short ); self& operator <<(unsigned short ); self& operator <<(int ); self& operator <<(unsigned int ); self& operator <<(long ); self& operator <<(unsigned long ); self& operator <<(long long ); self& operator <<(unsigned long long ); self& operator <<(const void *); self& operator <<(float v) { *this << static_cast <double >(v); return *this ; } self& operator <<(double ); self& operator <<(char v) { buffer_.append (&v, 1 ); return *this ; } self& operator <<(const char * str) { if (str) { buffer_.append (str, strlen (str)); } else { buffer_.append ("(null)" , 6 ); } return *this ; } self& operator <<(const unsigned char * str) { return operator <<(reinterpret_cast <const char *>(str)); } self& operator <<(const string& v) { buffer_.append (v.c_str (), v.size ()); return *this ; } self& operator <<(const StringPiece& v) { buffer_.append (v.data (), v.size ()); return *this ; } self& operator <<(const Buffer& v) { *this << v.toStringPiece (); return *this ; } void append (const char * data, int len) append (data, len); } const Buffer& buffer () const return buffer_; } void resetBuffer () reset (); } private : void staticCheck () template <typename T> void formatInteger (T) ; Buffer buffer_; static const int kMaxNumericSize = 48 ; };
其实这个类就是重载了各种类型的<<符号。重点成员是Buffer,这个Buffer和前文提到的Buffer不是一个东西,具体定义为:
1 2 3 4 typedef detail:: FixedBuffer <detail::kSmallBuffer> Buffer;const int kSmallBuffer = 4000 ;
默认buffer大小为4000(笔者注:为什么不是对齐的4k?), 基本所有的<<都转到了buffer的append函数,打开看下。
FixedBuffer·
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 template <int SIZE>class FixedBuffer : noncopyable{ public : void append (const char * buf, size_t len) { if (implicit_cast <size_t >(avail ()) > len) { memcpy (cur_, buf, len); cur_ += len; } } private : void (*cookie_)(); char data_[SIZE]; char * cur_; };
append就是个memcpy。
同步落盘·
问题来了:什么时候落盘的?如果avail不够len了,直接丢日志了?
回头再看下:
1 2 #define LOG_INFO if (muduo::Logger::logLevel() <= muduo::Logger::INFO) \ muduo::Logger(__FILE__, __LINE__).stream()
ok,这个类每次都在栈上生成一个临时对象,所以一次append不超过4k就没问题。那什么时候落盘,转而看看析构函数:
1 2 3 4 5 6 7 8 9 10 11 Logger::~Logger () { impl_.finish (); const LogStream::Buffer& buf (stream().buffer()) g_output (buf.data (), buf.length ()); if (impl_.level_ == FATAL) { g_flush (); abort (); } }
看到个g_output, 默认:
1 2 3 4 5 6 7 8 Logger::OutputFunc g_output = defaultOutput; void defaultOutput (const char *msg, int len) { size_t n = fwrite(msg, 1 , len, stdout ); (void )n; }
看样子默认是同步写入的。
异步落盘·
muduo提供了setOutput接口:
1 2 3 4 5 void Logger::setOutput (OutputFunc out) g_output = out; }
在AsyncLogging_test.cc中发现了调用:
1 2 3 4 void asyncOutput (const char * msg, int len) g_asyncLog ->append (msg, len); }
这就是我关心的异步刷盘怎么玩的了,相关类是AsyncLogging
这个类的成员变量如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 const int kLargeBuffer = 4000 *1000 ;typedef muduo::detail::FixedBuffer<muduo::detail::kLargeBuffer> Buffer; typedef std::vector<std::unique_ptr<Buffer>> BufferVector;typedef BufferVector::value_type BufferPtr;const int flushInterval_;std::atomic<bool > running_; const string basename_;const off_t rollSize_;muduo::Thread thread_; muduo::CountDownLatch latch_; muduo::MutexLock mutex_; muduo::Condition cond_ GUARDED_BY (mutex_) ; BufferPtr currentBuffer_ GUARDED_BY (mutex_) ; BufferPtr nextBuffer_ GUARDED_BY (mutex_) ;BufferVector buffers_ GUARDED_BY (mutex_) ;
比较重要的是这些buffer。晚点说它们的作用。
先看构造函数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 AsyncLogging::AsyncLogging (const string& basename, off_t rollSize, int flushInterval) : flushInterval_ (flushInterval), running_ (false ), basename_ (basename), rollSize_ (rollSize), thread_ (std::bind (&AsyncLogging::threadFunc, this ), "Logging" ), latch_ (1 ), mutex_ (), cond_ (mutex_), currentBuffer_ (new Buffer), nextBuffer_ (new Buffer), buffers_ () { currentBuffer_->bzero (); nextBuffer_->bzero (); buffers_.reserve (16 ); }
有两个buffer,看下append中是怎么用的
ping-pong写·
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 void AsyncLogging::append (const char *logline, int len) muduo::MutexLockGuard lock (mutex_) ; if (currentBuffer_->avail () > len) { currentBuffer_->append (logline, len); } else { buffers_.push_back (std::move (currentBuffer_)); if (nextBuffer_) { currentBuffer_ = std::move (nextBuffer_); } else { currentBuffer_.reset (new Buffer); } currentBuffer_->append (logline, len); cond_.notify (); } }
从上述代码可知,muduo的异步log刷盘中内存至少有两个buffer, currentBuffer_ 和 nextBuffer_, 当写log过快时,可能会申请多个buffer。
后台刷盘线程:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 void AsyncLogging::threadFunc () assert (running_ == true ); latch_.countDown (); LogFile output (basename_, rollSize_, false ) ; BufferPtr newBuffer1 (new Buffer) ; BufferPtr newBuffer2 (new Buffer) ; newBuffer1->bzero (); newBuffer2->bzero (); BufferVector buffersToWrite; buffersToWrite.reserve (16 ); while (running_) { assert (newBuffer1 && newBuffer1->length () == 0 ); assert (newBuffer2 && newBuffer2->length () == 0 ); assert (buffersToWrite.empty ()); { muduo::MutexLockGuard lock (mutex_) ; if (buffers_.empty ()) { cond_.waitForSeconds (flushInterval_); } buffers_.push_back (std::move (currentBuffer_)); currentBuffer_ = std::move (newBuffer1); buffersToWrite.swap (buffers_); if (!nextBuffer_) { nextBuffer_ = std::move (newBuffer2); } } assert (!buffersToWrite.empty ()); for (const auto & buffer : buffersToWrite) { output.append (buffer->data (), buffer->length ()); } if (buffersToWrite.size () > 2 ) { buffersToWrite.resize (2 ); } if (!newBuffer1) { assert (!buffersToWrite.empty ()); newBuffer1 = std::move (buffersToWrite.back ()); buffersToWrite.pop_back (); newBuffer1->reset (); } if (!newBuffer2) { assert (!buffersToWrite.empty ()); newBuffer2 = std::move (buffersToWrite.back ()); buffersToWrite.pop_back (); newBuffer2->reset (); } buffersToWrite.clear (); output.flush (); } output.flush (); }
步骤:
初始化两个buffer
等待 buffers_ 中有待写buffer,或者等到3s。
这里等待3s就周期刷盘可能有两个原因:
1. 内存的buffer,可能比较满,但是没有到4M,这种刷盘后,给内存预留足够空间。
2. 周期刷盘,如果进程因为某种原因crash,没有周期刷盘,这段不满4M的日志就丢了。
buffersToWrite交换buffers_, 避免临界区太长(避免写文件系统的时候还在加锁)
补充前台的两个buffer,如果有必要的话
刷盘
在buffersToWrite中预留两个buffer,用于后期和前台交换,避免反复申请内存。
很明显了典型的ping-pong写buffer实现。
唯一想说的一点是,等待3s后,是不是检查下buffer_是否为空,以及currentBuffer_是否真的有数据?
定时器·
在muduo源码分析1-事件循环(上) 中,有一个对象和定时有关,当时没有分析:
1 2 std::unique_ptr<TimerQueue> timerQueue_;
相关的函数有:
1 2 3 4 5 TimerId EventLoop::runAt (Timestamp time, TimerCallback cb) return timerQueue_->addTimer (std::move (cb), time, 0.0 ); }
1 2 3 4 5 6 TimerId EventLoop::runAfter (double delay, TimerCallback cb) Timestamp time (addTime(Timestamp::now(), delay)) ; return runAt (time, std::move (cb)); }
看样子可以用来实现delay。
1 2 3 4 5 6 7 TimerId EventLoop::runEvery (double interval, TimerCallback cb) Timestamp time (addTime(Timestamp::now(), interval)) ; return timerQueue_->addTimer (std::move (cb), time, interval); }
这个是无限定时器。
1 2 3 4 5 void EventLoop::cancel (TimerId timerId) return timerQueue_->cancel (timerId); }
这其中的关键类是 TimerQueue
TimerQueue·
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 class TimerQueue : noncopyable {public : TimerId addTimer (TimerCallback cb, Timestamp when, double interval) void cancel (TimerId timerId) private : EventLoop* loop_; const int timerfd_ ; Channel timerfdChannel_; TimerList timers_ ; ActiveTimerSet activeTimers_; bool callingExpiredTimers_; ActiveTimerSet cancelingTimers_; };
重点对象已高亮。看下addTimer怎么玩的:
1 2 3 4 5 6 7 8 9 TimerId TimerQueue::addTimer (TimerCallback cb, Timestamp when, double interval) Timer * timer = new Timer (std::move (cb), when, interval); loop_->runInLoop ( std::bind (&TimerQueue::addTimerInLoop, this , timer)); return TimerId (timer, timer->sequence ()); }
定时信息转到了Timer中,然后调用addTimerInLoop:
1 2 3 4 5 6 7 8 9 10 void TimerQueue::addTimerInLoop (Timer* timer) loop_->assertInLoopThread (); bool earliestChanged = insert (timer); if (earliestChanged) { resetTimerfd (timerfd_, timer->expiration ()); } }
看下insert:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 bool TimerQueue::insert (Timer* timer) loop_->assertInLoopThread (); assert (timers_.size () == activeTimers_.size ()); bool earliestChanged = false ; Timestamp when = timer->expiration (); TimerList::iterator it = timers_.begin (); if (it == timers_.end () || when < it->first) { earliestChanged = true ; } { std::pair<TimerList::iterator, bool > result = timers_.insert (Entry (when, timer)); assert (result.second); (void )result; } { std::pair<ActiveTimerSet::iterator, bool > result = activeTimers_.insert (ActiveTimer (timer, timer->sequence ())); assert (result.second); (void )result; } assert (timers_.size () == activeTimers_.size ()); return earliestChanged; }
如果timers_是空,或者当前记录的最小超时的比新加入的超时时间还要大。则标记earliestChanged=true,然后保存新传入的timer信息。
这里的timers_和activeTimers_都是一个set,里面保存的类型分别是Entry和ActiveTimer.
1 2 3 4 5 6 typedef std::pair<Timestamp, Timer*> Entry;typedef std::set<Entry> TimerList;typedef std::pair<Timer*, int64_t > ActiveTimer;typedef std::set<ActiveTimer> ActiveTimerSet;
关注下它们的比较函数,std::pair自身的比较规则是,先比较first,如果first相同再比较second。
所以对于timers_来说,先看Timestamp:
1 2 3 4 5 6 7 8 9 10 11 12 inline bool operator <(Timestamp lhs, Timestamp rhs){ return lhs.microSecondsSinceEpoch () < rhs.microSecondsSinceEpoch (); } inline bool operator ==(Timestamp lhs, Timestamp rhs){ return lhs.microSecondsSinceEpoch () == rhs.microSecondsSinceEpoch (); }
如果timestamp相同,则对比Timer *指针。
再看activeTimers_则直接比较Timer *,如果指针相同,则比较timer sequence
回到主线,如果插入timer成功,且当前插入的定时是最新会被触发的定时。则调用resetTimerfd:
1 2 3 4 if (earliestChanged){ resetTimerfd (timerfd_, timer->expiration ()); }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 void resetTimerfd (int timerfd, Timestamp expiration) struct itimerspec newValue; struct itimerspec oldValue; memZero (&newValue, sizeof newValue); memZero (&oldValue, sizeof oldValue); newValue.it_value = howMuchTimeFromNow (expiration); int ret = ::timerfd_settime (timerfd, 0 , &newValue, &oldValue); if (ret) { LOG_SYSERR << "timerfd_settime()" ; } }
ok,看到了定时器的底层实现了。底层实际上用了 内核提供的定时器api。不同点在于muduo只用了一个fd来表示所有定时功能(所以也不那么精准)。一旦定时器事件到达,epoll就会返回,muduo通过channel来监听epoll, 看下在哪里生成的:
1 2 3 4 5 6 7 8 9 10 11 12 13 TimerQueue::TimerQueue (EventLoop* loop) : loop_ (loop), timerfd_ (createTimerfd ()), timerfdChannel_ (loop, timerfd_), timers_ (), callingExpiredTimers_ (false ) { timerfdChannel_.setReadCallback ( std::bind (&TimerQueue::handleRead, this )); timerfdChannel_.enableReading (); }
一旦fd上有定时事件到达,回调handleRead:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 void TimerQueue::handleRead () loop_->assertInLoopThread (); Timestamp now (Timestamp::now()) ; readTimerfd (timerfd_, now); std::vector<Entry> expired = getExpired (now); callingExpiredTimers_ = true ; cancelingTimers_.clear (); for (const Entry& it : expired) { it.second->run (); } callingExpiredTimers_ = false ; reset (expired, now); }
根据回调回来的当前时间,从timers_ 获取expired的定时器entry(通过getExpired)。接着逐一回调。最后重新reset定时器。
看下reset逻辑:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 void TimerQueue::reset (const std::vector<Entry>& expired, Timestamp now) Timestamp nextExpire; for (const Entry& it : expired) { ActiveTimer timer (it.second, it.second->sequence()) ; if (it.second->repeat () && cancelingTimers_.find (timer) == cancelingTimers_.end ()) { it.second->restart (now); insert (it.second); } else { delete it.second; } } if (!timers_.empty ()) { nextExpire = timers_.begin ()->second->expiration (); } if (nextExpire.valid ()) { resetTimerfd (timerfd_, nextExpire); } }
遍历刚才已经触发过expire的entry,找到是需要repeat的entry,重新把它们加回定时器。最后根据定时器中第一个会超时的时间,重新reset timerfd_即可。
笔者注: 如果nextExpire刚好处于一个边界,比之前expire的entry的时间都大,但是在reset之前刚好又比now小,也就是reset之前它也应该触发回调,内核的接口如果设置了一个超时时间比当前时间还小的case,是怎么处理的?会立即产生事件吗?
又看了下源码,muduo作者是考虑了这个场景的:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 void resetTimerfd (int timerfd, Timestamp expiration) struct itimerspec newValue; struct itimerspec oldValue; memZero (&newValue, sizeof newValue); memZero (&oldValue, sizeof oldValue); newValue.it_value = howMuchTimeFromNow (expiration); int ret = ::timerfd_settime (timerfd, 0 , &newValue, &oldValue); if (ret) { LOG_SYSERR << "timerfd_settime()" ; } } struct timespec howMuchTimeFromNow (Timestamp when){ int64_t microseconds = when.microSecondsSinceEpoch () - Timestamp::now ().microSecondsSinceEpoch (); if (microseconds < 100 ) { microseconds = 100 ; } struct timespec ts; ts.tv_sec = static_cast <time_t >( microseconds / Timestamp::kMicroSecondsPerSecond); ts.tv_nsec = static_cast <long >( (microseconds % Timestamp::kMicroSecondsPerSecond) * 1000 ); return ts; }
所以不存在我提出的这个问题。
总结定时器·
muduo采用了内核提供timerfd_xxx 一组api,提供最基础的定时功能,并在其之上,自己维护了一个set,set按照过期时间排序,每次按照最快会过时的定时事件来设置内核超时时间,并在内核通知时,收割这个set,之后查看剩余的set中最新会超时的时间,循环设置。
至此,muduo源码基本分析完毕,下篇写个总结。