1. redisObj·
redis 在实现kv数据库时,并不直接使用前一章提到的数据结构,而是在其上封装了一个redisObject:
1 | /* A redis object, that is a type able to hold a string / list / set */ |
1. type·
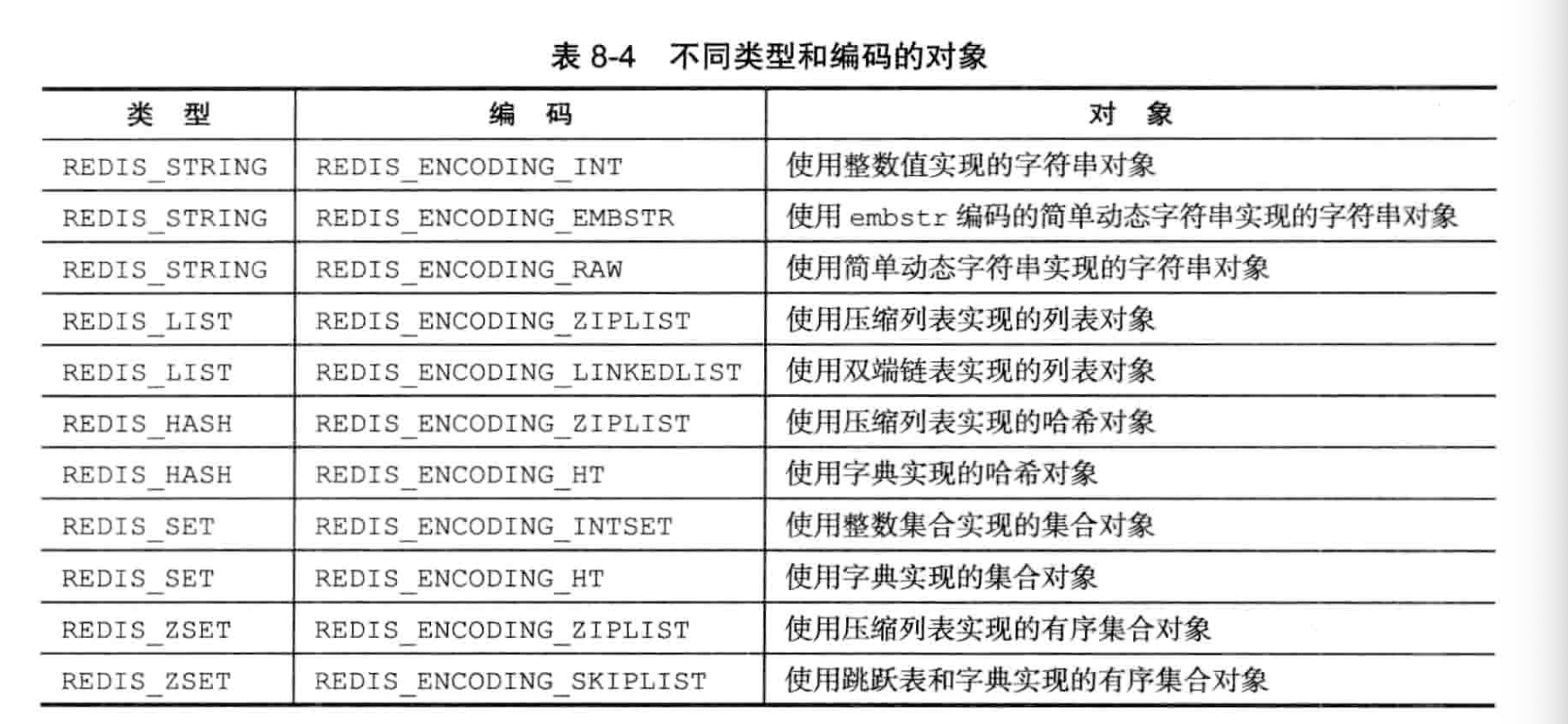
type 4bits, 包含如下:
- REDIS_STRING
- REDIS_LIST
- REDIS_HASH
- REDIS_SET
- REDIS_ZSET
kv中,key总是字符串type,redisObject中的type总是说value的type 笔者注:实际上3bits已经够了,可能是多预留?
2. encoding·
ptr指向实际的对象,而具体的对象类型,由encoding决定:
1 |
不同type可对应的底层encoding·
使用 OBJECT ENCODING [key] 查看编码类型
2. 字符串对象·
字符串对象的编码可以是 int, raw 或者 embstr
- int, 如果通过SET命令存储的value是一个long类型可保存的值,那么直接保存,在使用的时候,直接通过强转
ptr得到该值。 - raw, 如果存储的value长度大于32字节,那么使用SDS保存。
- embstr, 如果存储的value长度小于等于32字节,那么字符串对象使用embstr保存
embstr和raw相比,少一次内存分配。 raw对象会分配redisObj和ptr指向的SDS对象,共计2次。embstr是一次性分配redisObj和ptr指向的SDS对象.
笔者注: 和cpp中shared_ptr一样,new方式和make_shared的区别。
浮点型也是字符串内省,但是可以执行一些数字运算。只不过在计算时,首先将字符串转为数字,计算后,又将数字转为字符串。

编码转换条件·
- int -> embstr/raw: 只要出现不是数字,或者长度超过一定阈值(TODO(zhangxingrui): 阈值是多少?)
- embsr -> raw: 长度超过32位,或者原本是embstr,但是对embstr对象做了修改, 如:

字符串命令的实现·

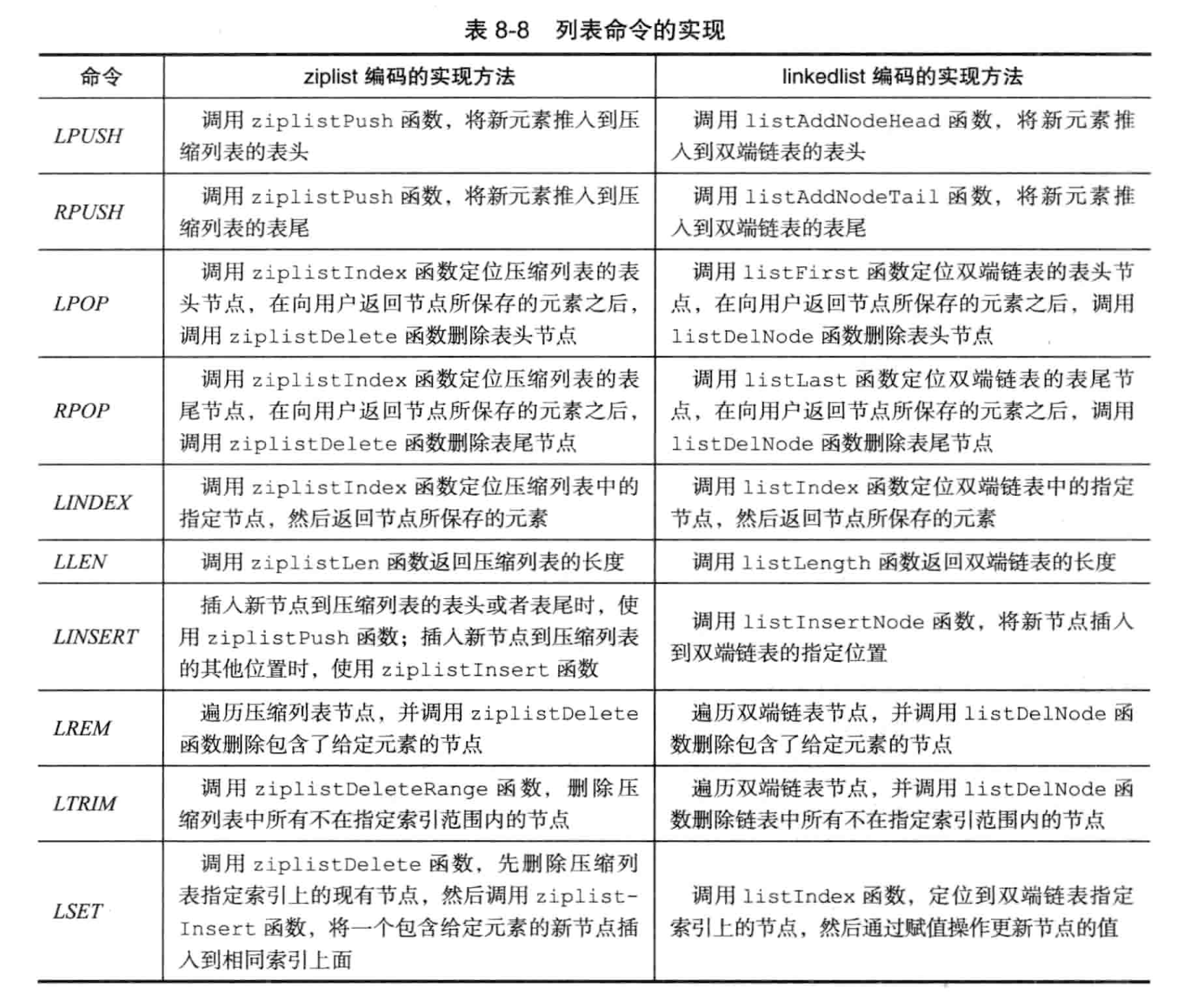
3. 列表对象·
列表对象(type: REDIS_LIST), 底层实现有 ziplist 和 linkedlist 。
转换条件·
在以下条件时使用 ziplist:
- 列表保存的字符串元素的长度都小于64 字节;
- 列表对象保存的元素数量小于512个。
上述两个条件都可以修改ia。 see list-max-ziplist-value 和 list-max-zilist-entries
list命令实现·
4. hash table对象·
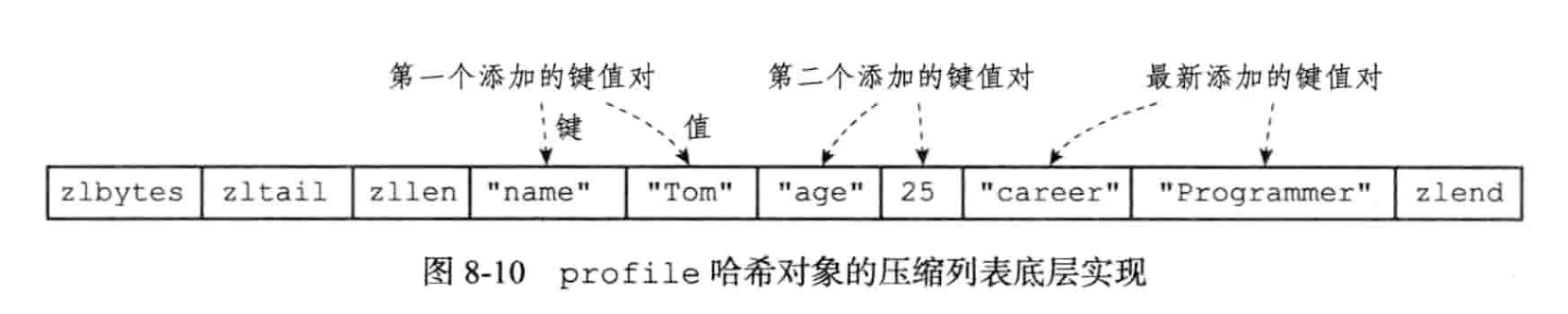
hash table 的编码可以是ziplist和 hashtable
hashtable实现hash table对象很好理解。 这里说下 ziplist 是如何实现hashtable的。 对于每次插入hashtable的元素,每次都将kv分别依次插入到ziplist的表尾,所以ziplist实现的hashtable的同一个kv对总是挨在一起。
转换条件·
和list的ziplist一样,满足:
- 列表保存的字符串元素的长度都小于64 字节;
- 列表对象保存的元素数量小于512个。
上述两个条件都可以修改ia。 see hash-max-ziplist-value 和 hash-max-zilist-entries
hashtable命令的实现·

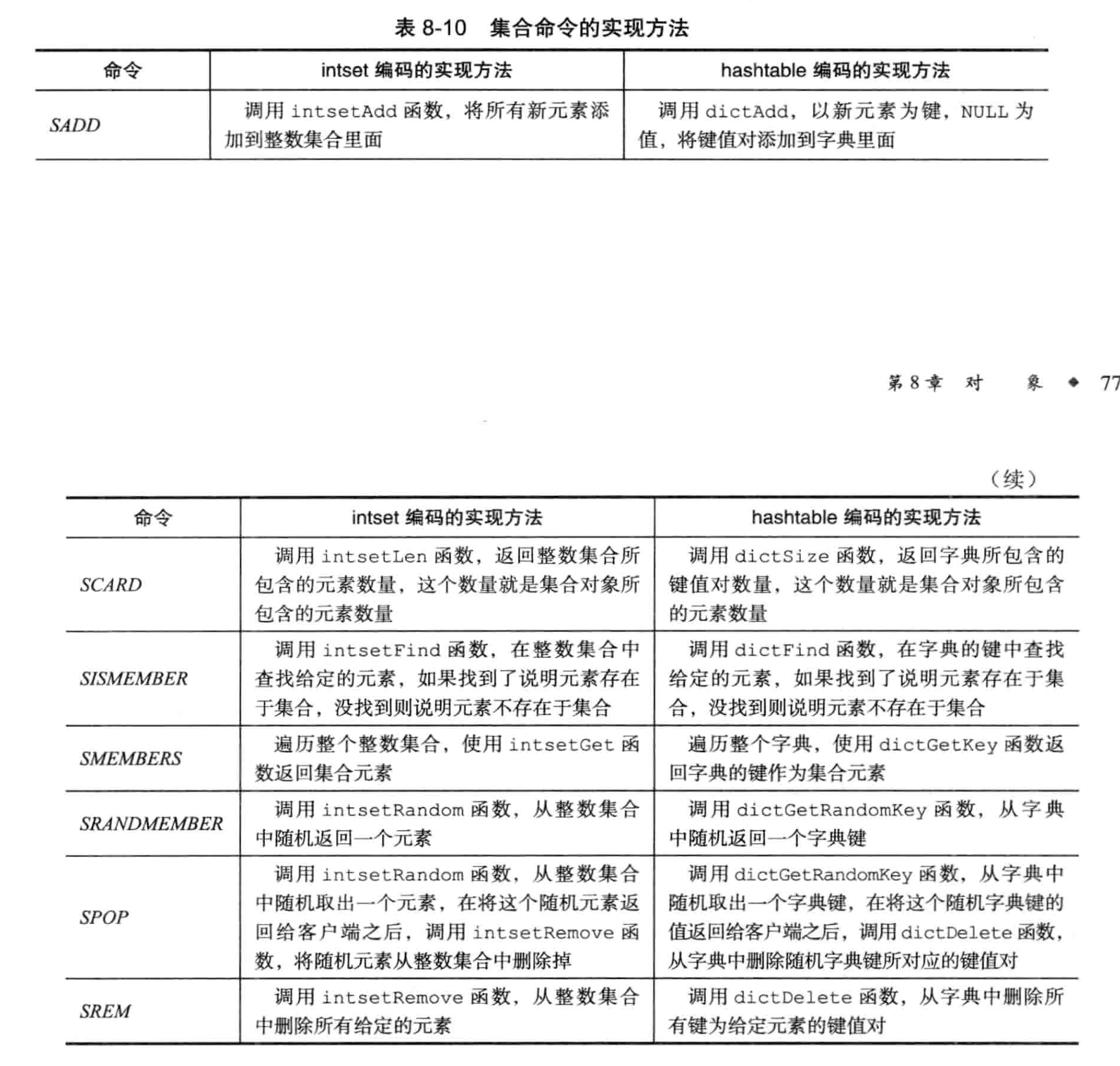
5. 集合对象·
集合对象的编码可以是intset或者hashtable.
转换条件·
使用intset的条件:
- 集合所有保存的对象都是整数
- 集合对象保存的元素数据量不超过512个
第二个条件是可以修改的, see set-max-intset-entries
集合实现·
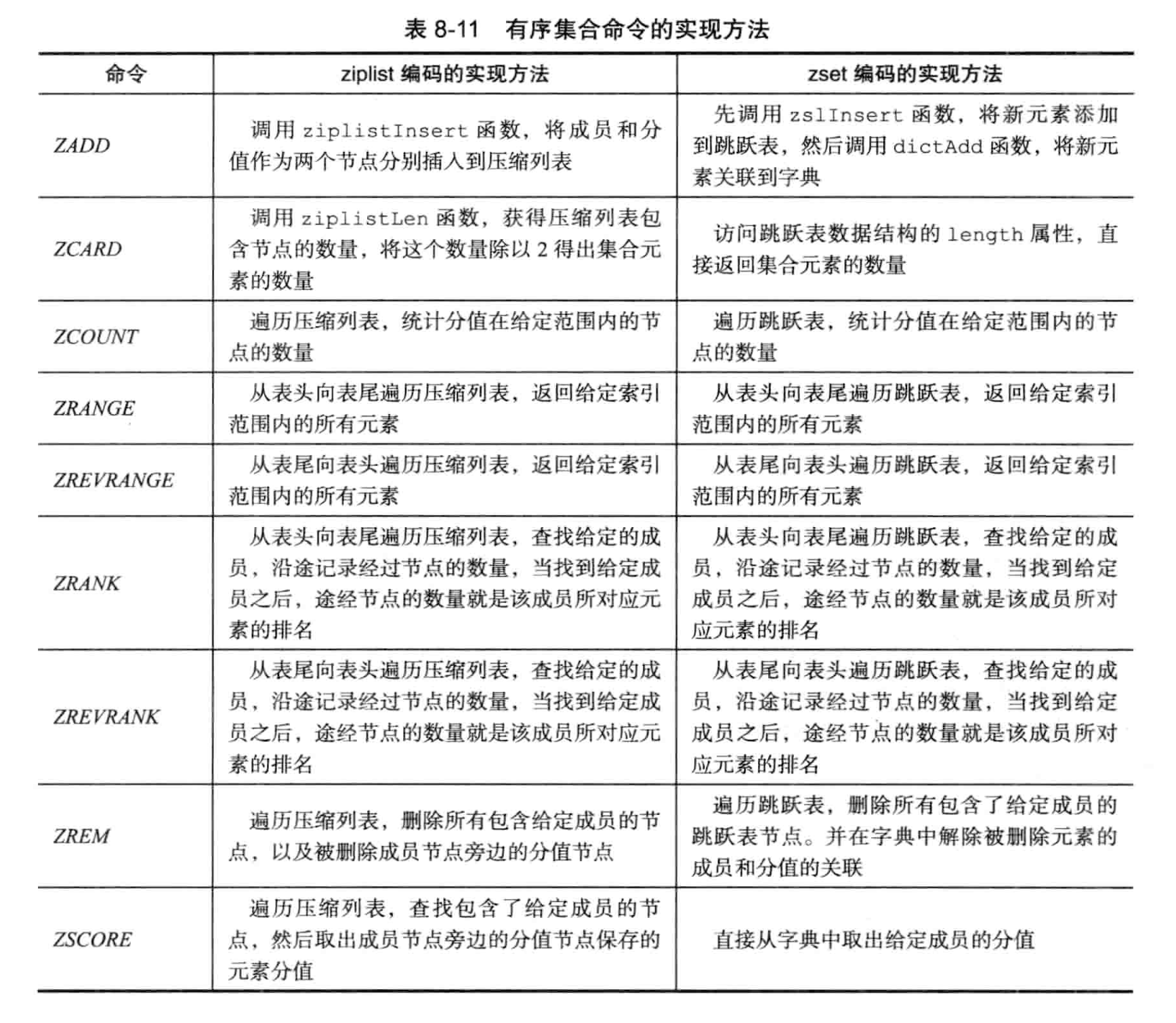
6. 有序集合对象·
有序集合底层采用ziplist或skiplist实现。
ziplist实现时,成员member和score紧挨在一起,并且按照score排序。
skiplist时,用zset结构表示:
1 | /* |
实际用同时用了两个数据结构, dict和zskiplist,一个用于O(1)查询,一个用于排序。
编码转换·
ziplist条件:
- 有序集合保存的元素数量小于128
- 有序集合保存的所有元素成员的长度都小于64字节
上述条件可修改, see zset-max-ziplist-entries 和 zset-max-ziplist-value
有序集合实现·
思考·
上述内容很简单,唯一让我思考的地方在于某个类型从一个数据结构转换到另一个数据结构时的开销,毕竟数据转移+内存分配时耗时的。 在实际使用上就可能出现毛刺。 得看看源码的实现。下面结合list实现的ziplist -> linkedlist 的源码分析:
分析函数 listTypePush:
1 | void listTypePush(robj *subject, robj *value, int where) { |
函数listTypeTryConversion:
1 | void listTypeTryConversion(robj *subject, robj *value) { |
这里可以看到:
-
如果已经不是ziplist编码,直接返回
-
检查当前sds对象的长度是否比
list_max_zilist_value还长,如果满足则转换1
list_max_ziplist_value -> #define REDIS_LIST_MAX_ZIPLIST_VALUE 64
另一个条件是:
1 | if (subject->encoding == REDIS_ENCODING_ZIPLIST && |
如果整个ziplist的个数大于 list_max_ziplist_entries , 那么则转换。
再来分析 listTypeConvert:
1 | void listTypeConvert(robj *subject, int enc) { |
很明显,一个迭代器+while循环,将原ziplist -> linkedlist。 所以没什么特别的优化。
对象共享·
redis对整数0-9999之间的整数对象做了内存池,后续用引用技术共享。 这10k个对象是在redis服务初始化时就创建的。
使用 OBJECT REFCOUNT obj_name 来查询一个对象的引用计数
redis只对整数对象共享,字符串共享不太可行,因为字符串共享需要比较整个字符串,cpu开销过大。
lru字段·
在redisObject中,lru字段保存这该对象上次访问的时间戳,用于后续缓存剔除。
使用 OBJECT IDLETIME obj_name 查询一个对象的空闲时间, 该时间为 当前时间 - lru记录的值

