本文采用wolia制作,原文link: https://www.wolai.com/ravenxrz/9RuzaMAipvQTqAjnGiydYn
原文名字:mClock: Handling Throughput Variability for Hypervisor IO Scheduling
作者提出一种mlock算法,用于优化VM中对IO分配。
📌一句话总结mclock算法:用户分配的带宽要么等于所设置的Reservation值,要么等于按照Weight分配的结果,要么等于Limit值。当按照Weight分配的结果大于用户所设置的Reservation时,则用户最终分配的带宽为按照Weight分配的结果;当按照Weight分配的结果小于用户所设置的Reservation时,则带宽分配的结果等于Reservation;当按照Weight分配的结果大于用户所设置的Limit时,则带宽分配的结果等于Limit。
背景·
VM使用广泛,当前VM中重点关注的是CPU和Mem的分配,关于IO的分配关注较少,而IO 调度面临共享存储设备访问、调度层次、访问局部性、IO 大小差异和突发工作负载等挑战,且 IO 吞吐量易受其他主机影响,导致 VM 的 IOPS 波动,影响应用性能。
作者做了一个实验证明:
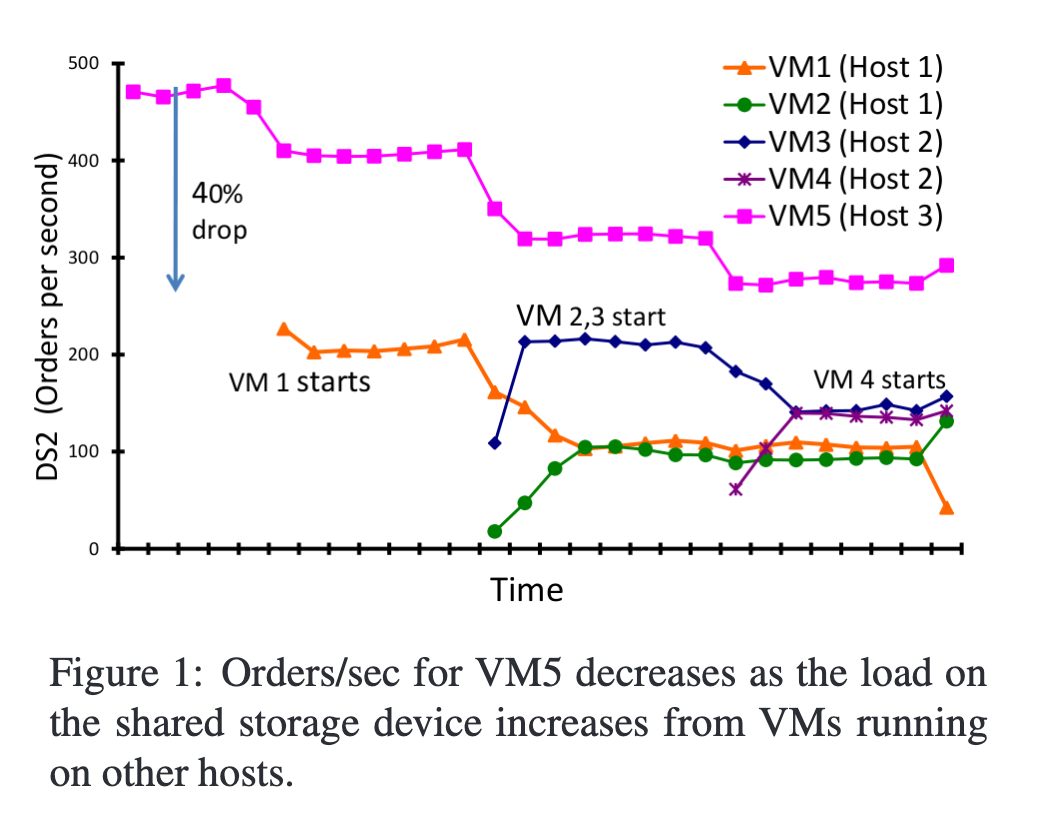
一共5台VM,3台Host,最开始VM5独占存储,性能较好,后来随着VM1-VM4开始消耗IO,VM5的IOPS降低了40%。
之前的一些算法,如PARDA存在明显缺陷,基于以上背景,作者提出了mclock算法(以及对应的分布式算法,dmclock)。mclock算法为VM提供 权重(weight), 预留(reservation)和上限(limit) 三种维度上的结合控制。
Overview·
本文之前的算法大体分三类:
- 加权平均分配算法的变种
- 加权平均+延迟感知
- 加权平均+资源预留
mclock整体设计上就是上述三类算法的结合,包含三个关键参数: 权重(weight), 预留(reservation)和上限(limit), 这些参数由用户提供(非自适应)。
举个例子来证明加权分配算法的不足,设有三个应用:
- RD(远程桌面), 对时延要求高
- OLTP, 对吞吐和时延都要求高
- DM(数据迁移),对吞吐要求高,对时延不敏感
现在预设上述应用的权重分别为100、200和300, 为了延迟敏感,为RD和OLTP指定250IOPS的预留。为DM预设1000的上限。
在上述例子中,如果系统的吞吐量为 1200 IOPS,根据前面设定的weight(RD 的weight为 100 ,所有活跃虚拟机weight总和假设为 600,这里简化假设只有 RD、OLTP 和 DM 三个活跃虚拟机,weight分别为 100、200、300),那么 RD 虚拟机获得的吞吐量为200 IOPS 。然而,RD 虚拟机所需的最低吞吐量是 250 IOPS,200 IOPS 低于这个最小值。这就会导致 RD 用户的体验变差,即便系统实际上有足够的容量,能够让 RD 和 OLTP 都获得它们各自 250 IOPS 的预留量。
如果使用mclock,mclock会优先保证RD最低的250 IOPS,然后将剩余的950 IOPS按照加权(2:3)分配给OLTP和DM。下图展示了不同系统总能力下的分配结果:
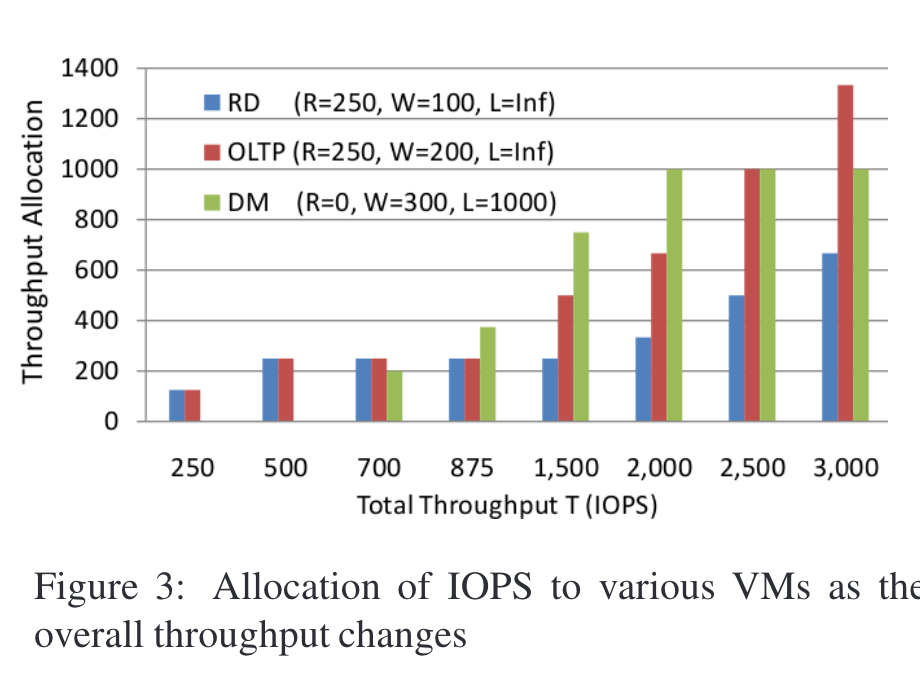
- 如果 T≥2000 IOPS,那么 DM 的吞吐量将被限制在 1000 IOPS,因为按照比例它应得的 T/2 超过了其上限,剩余的吞吐量将按照 1 : 2 的比例在 RD 和 OLTP 之间分配。
- 当 T 在 1500 至 2000 IOPS 之间时,吞吐量按照 RD、OLTP 和 DM 的权重(1 : 2 : 3)进行分配,因为此时它们都不会超过各自的上限或低于预留值。vb
- 如果总吞吐量 T 降至 1500 IOPS 以下,RD 的分配量将降至最低 250 IOPS;
- 当 T≤875 IOPS 时,OLTP 的分配量也会降至 250 IOPS。
- 当 T<500 IOPS 时,RD 和 OLTP 的预留量无法满足,可用的吞吐量将在 RD 和 OLTP 之间平均分配(因为它们的预留量相同),而 DM 将得不到任何服务。
这是怎么算出来的?
参考:https://juejin.cn/post/6844904015856140301总结这个算法:
用户分配的带宽要么等于所设置的Reservation值,要么等于按照Weight分配的结果,要么等于Limit值。当按照Weight分配的结果大于用户所设置的Reservation时,则用户最终分配的带宽为按照Weight分配的结果;当按照Weight分配的结果小于用户所设置的Reservation时,则带宽分配的结果等于Reservation;当按照Weight分配的结果大于用户所设置的Limit时,则带宽分配的结果等于Limit。
一个典型的错误认知为:先按照预留分配,之后按照权重分配。

正确的认知是,一个应用所分配得到的带宽或IOPS是一次性分配出来的,要么是预留值,要么是上限值,要么是按某个剩余带宽乘以权重比值分配出来的。这点从论文给出的分配公式也可以看出来:

其中:
- vi代表第i个vm
- ri 代表分配的是预留
- li 代表分配的是上线
- Tp 为当前减去已分配给r和l后的剩余带宽
- yi为给vi分配的带宽
明显yi一共就三种取值,正是上文中所提到的三种值。
下面再举个例子来说明如何计算预留带宽能力:
看T =700的例子:
- 由于RD的预留+OLTP的预留=500, 所以可以满足预留分配。
- 先按权重分配,则RD=700/6=116, 不满足R=250的需求,所以直接给RD分配250,剩余450的T。
- 再看剩余两个OLTP和DM,如果按权重分配, OLTP=450*2/5=180, 不满足R=250的需求,所以直接给OLTP分配250,剩余200 T.
- 剩余的200分配给DM。
再看T=1500的例子:
- 由于RD的预留+OLTP的预留=500, 所以可以满足预留分配。
- 按照权重分配,RD=1500/6=250, 满足R=250的需求。OLTP=1500*2/6=500, 满足R=250的需求。DM=1500/2=750, 满足小于L=1000的需求。 分配完成。
再看T=2500的例子:
- 由于RD的预留+OLTP的预留=500, 所以可以满足预留分配。
- 按照权重分配,DM=2500/2=1250, 超过L=1000,截断只分配1000,剩余1500在RD和OLTP中按权重分配,即RD=1500/3=500, OLTP=1500*2/3=1000。
最后看T=250的例子:
1. 由于RD的预留+OLTP的预留=500,已经超过总能力250。
2. 所以直接按照各应用的预留比值来分配,所以RD分得250*1/2=125, OLTP分得125, DM分得0.
详细算法设计·
Tag-based的调度算法是公平调度器的基础。一种算法可以为客户端i的连续请求分配间隔为1/wi的标签;如果所有请求都按照标签值的顺序进行调度,那么客户端将按照的比例wi获得服务。mclock扩展了这个概念,基于三种控制使用多个标签,并动态决定使用哪个标签。
mClock使用两个核心概念:
- 多个实时时钟:每个tag对应一个时钟(笔者注:理解成多个维度的队列即可)
- 动态时钟选择:根据多个tag来动态选择要服务的是哪个request。
mclock为每个vm io都分配3个tag,一个用于预留R,一个用于上限L,一个用于权重分配P。
Tag分配:
以预留R为例,解释下每个Tag是怎么分配的。假设Vi在时刻t来了一个io,则R tag取值为:
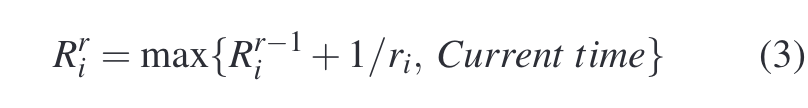
其中 i代表第几个vm,r代表第几个request。
怎么理解这个公式?
ri 是系统管理员为VMi预设的值,所以对于一个VM来说,如果不考虑max(R, current time),其资源分配应该是等距分布的,但这会带来的一个问题,不考虑时间因素,一个host上有多个vm,某些vm临时空闲后又恢复active,会导致其他vm上的request得不到响应。如下图:
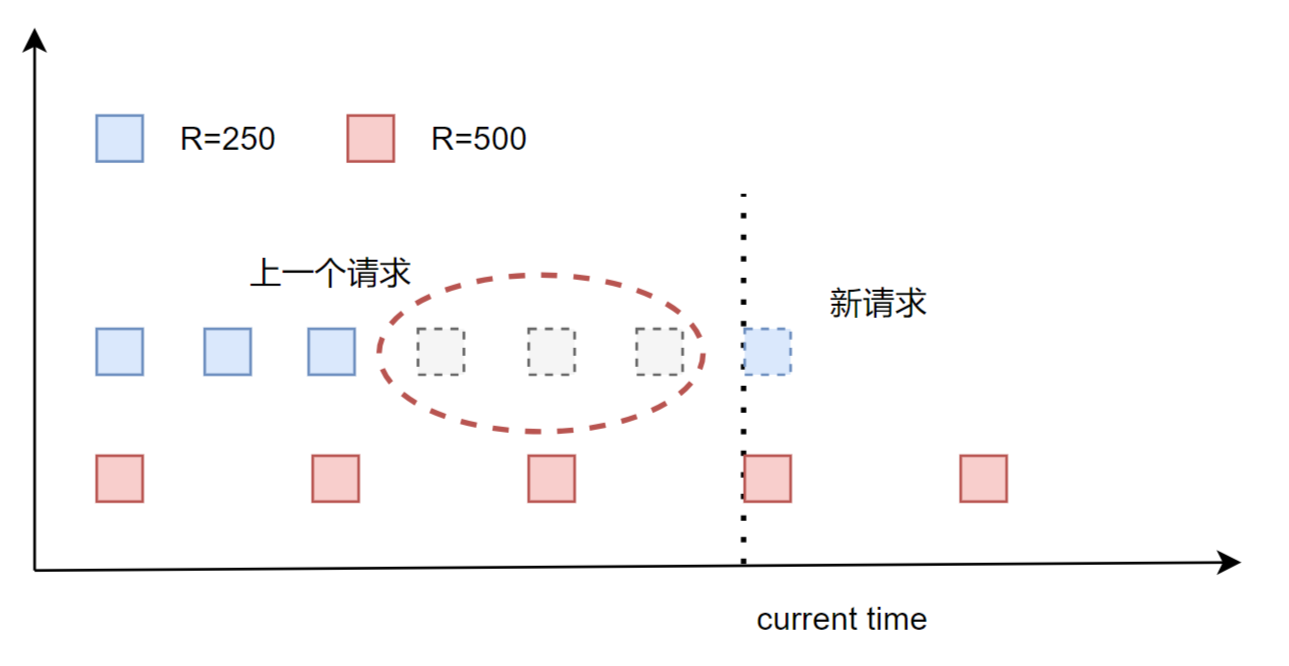
该图摘抄自:https://zhuanlan.zhihu.com/p/683804930 红蓝VM的R值应该取反了,蓝色的R=500, 红色的R=250
假设上述框选的部分,VM1(蓝色部分)临时idle,在current time时刻又来了新request,如果把新reuqest分布到框选的第一个时刻,就会导致vm2(红色部分)在一段时间内得不到响应,所以上述公式取的是max(前一个请求+1/ri, current time).
另外两个标签L和P的分配策略是类似的。
Tag调整: 系统上电时,P tag等于当前系统时间,但是随着系统运行,P tag逐渐会变得和系统实时时间不相关,当有新虚拟机启动时,可能会导饥饿问题(笔者注:因为新虚拟机的 P 标签值可能会远小于现有虚拟机的 P 标签值)。 所以需要对现有的P tag进行调整,使最小的P tag与新VM的到达时间匹配,同时要保证他们之间的相对间隔,具体实现中,当一个新VM进入时,为其分配一个offset,offset等于系统当前最小P tag与当前时间之间的间隔。
还是看例子来理解:
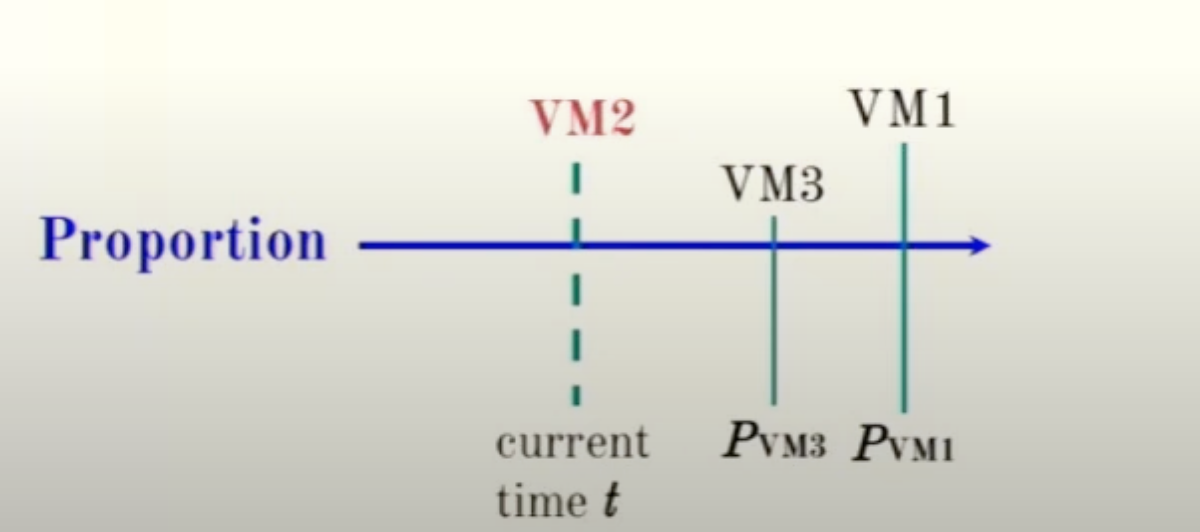
假设VM2一直处于idle,按照P tag,之后会调度的VM3和VM1。如果VM2恢复到active,就会抢占VM3和VM1,且如果VM2的P tag间隔很短,就会导致VM3和VM1处于饥饿状态。
为了处理这种场景,mclock将VM2的所有io处理时机向后delay一段时间,这段时间等于系统当前最小P tag与当前时间的间隔。 (或者换个角度思考,VM2被延后了,等同于其余所有VM io都提前了,如下伪代码,采用的是将其余VM io时间都提前一段时间)

我们还是从延后角度去看,延后的结果是,VM2的第一个io处理时间被延后到了VM3,因为minPtag - t 就是VM3到VM2之间的间隔,由此可以解决VM2抢占VM3和VM1而带来的饥饿问题。
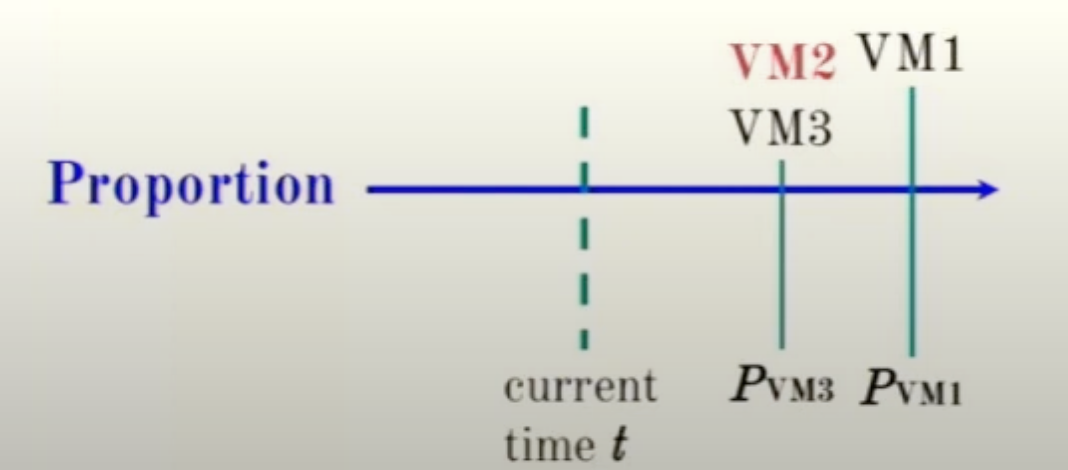
调度:
mClock需要检查上述三个Tag来决定调度:
- 第一阶段, constaint-based phase, 首先检查系统中的R tag低于当前时间的VM,找到最小的R tag来提供服务,直到系统中所有小于当前时间的R tag VM都提供完服务。 此步骤保证预留资源优先得到满足。
- 第二阶段,weight-based phase, 到这个节点,所有VM都已经获取了预留资源量,此时系统选择具有最小的P tag(但是排除已经超过了limit的VM,即L tag大于当前时钟的request不会被处理), 调度vi的请求,并且将vi没有完成请求的R标签值减少1/ri, 用于确保R标签之间的间隔保持在1/ri。
怎么理解第二阶段,为什么使用P tag调度后,需要调整R tag?看下图:
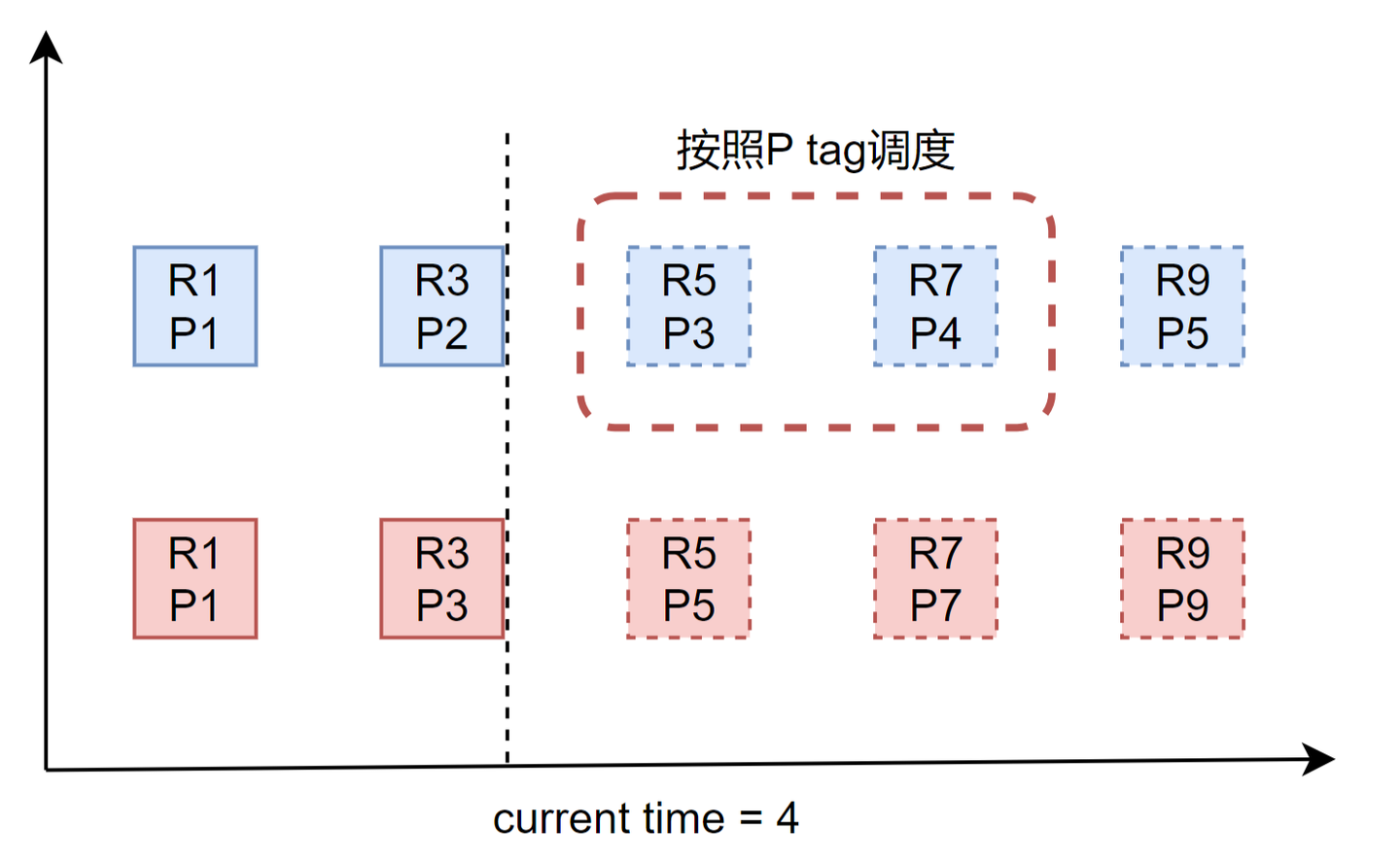
当前时钟等于4,所有R tag都大于4,所以进行P tag调度,选择了红色虚线框中两个请求,如果不对 R9:P5进行的R tag进行调整,时钟前进9之前,R tag调度都不会进行公平调度,也就是R9:P5得不到调度,反映到Qos上就是预留给蓝色VM的带宽会偏低。
下面是整个mclock算法的伪代码:
- RequestArrival: 是为每个io分配tag的算法
- ScheduleRequest: 是基于tag调度要服务的io的算法

参考·
- https://zhuanlan.zhihu.com/p/683804930
- https://juejin.cn/post/6844904015856140301

