0. 前言·
本实验为MIT 6.s081的第六个实验,主题为 copy-on-write(cow, 写时复制)相关。实现进程在fork时的cow机制。
要求:
更改xv6内核 fork 机制,实现延迟分配物理page给子进程。具体而言,在fork时,只用创建子进程的页表,但无需拷贝实际的物理页,并同时更新父子进程对应页的PTE为 not writable。 当父或子进程对物理页进行实际更新时,CPU产生page fault, 内核此时才分配新物理页,执行拷贝和页表项重映射。
1. 原理·
本lab仍为页表的扩展应用之一,要实现本lab,至少需要搞懂以下几个问题:
fork时,如何处理父子进程的页表?
修改 uvmcopy, 将父子进程的PTE取消 PTE_W权限。
产生缺页中断时,如何识别是COW的缺页中断,而不是平常的错误缺页?
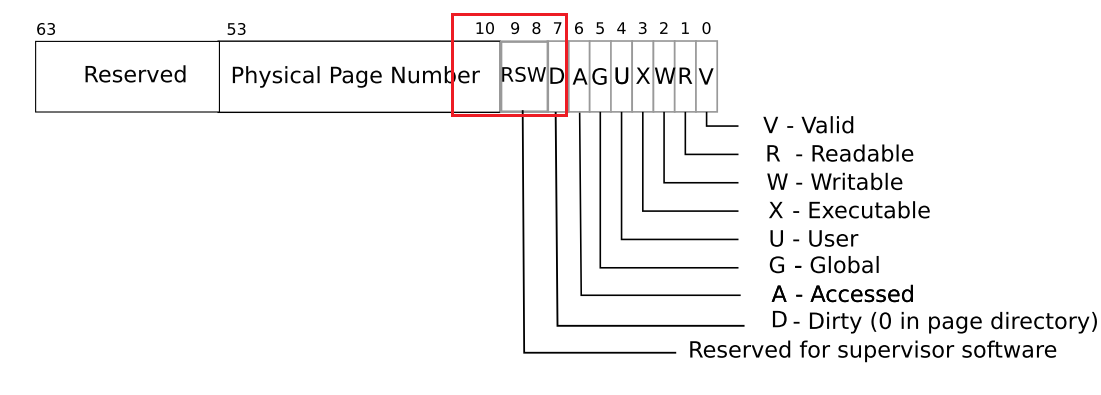
可以利用RISCV对PTE的保留bit,来标记当前PTE对应page是COW时的page。如下图中的RSW位,选择其一用于标记即可。
采用引用计数对每个可用物理进行计数,只有当引用计数变为0时,才回收page。问题是如何表示每个页的引用情况?
这里有两种做法,一种是将引用计数内嵌到每个page中,修改kalloc,每次申请内存为4KB+引用计数所占字节的空间。这种做法类似csapp的malloclab。
另一种做法是将所有page的引用计数单独用一个连续内存空间来执行保存,形成类似数组的数据结构。之后可通过数组下标=物理地址/4K来进行索引。
个人做法为数组类型做法。
2. 实现·
首先在riscv.h中增加一个 PTW_COW flag:
1 #define PTE_COW (1L << 8)
接着修改 uvmcopy:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 int uvmcopy (pagetable_t old, pagetable_t new, uint64 sz) { pte_t *pte; uint64 pa, i; uint flags; for (i = 0 ; i < sz; i += PGSIZE){ if ((pte = walk(old, i, 0 )) == 0 ) panic("uvmcopy: pte should exist" ); if ((*pte & PTE_V) == 0 ) panic("uvmcopy: page not present" ); *pte = ((*pte) & (~PTE_W)) | PTE_COW; pa = PTE2PA(*pte); pg_ref((void *)pa); flags = (PTE_FLAGS(*pte) & (~PTE_W)) | PTE_COW; if (mappages(new, i, PGSIZE, pa, flags) != 0 ) { goto err; } } return 0 ; err: uvmunmap(new, 0 , i / PGSIZE, 1 ); return -1 ; }
这里有两个改动:
修改父进程的pte,取消写权限,增加COW标记
不分配实际物理页给子进程,修改flag
这里的 pg_ref暂时忽略,后文再说。
接着在 usertrap 中处理 page fault:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 if (r_scause() == 13 || r_scause() == 15 ) { uint64 va = r_stval(); va = PGROUNDDOWN(va); pte_t *pte = walk(p->pagetable, va, 0 ); if (pte == 0 ) { p->killed = 1 ; goto killed; } if (!(*pte & PTE_COW)) { p->killed = 1 ; goto killed; } char * mem = kalloc(); if (mem == 0 ) { p->killed = 1 ; goto killed; } uint64 pa = PTE2PA(*pte) ; uint flag = (PTE_FLAGS(*pte) & (~PTE_COW)) | PTE_W ; memcpy (mem, (char *)pa, PGSIZE); uvmunmap(p->pagetable, va, 1 , 1 ); mappages(p->pagetable, va, PGSIZE, (uint64)mem, flag); } else { printf ("usertrap(): unexpected scause %p pid=%d\n" , r_scause(), p->pid); printf (" sepc=%p stval=%p\n" , r_sepc(), r_stval()); p->killed = 1 ; } killed: if (p->killed) exit (-1 );
13和15为 scause 中的page fault标志,这部分在 lazy allocation lab中已经提到过。通过 walk 函数找到 va 对应的pte。 如果没有对应的pte,则kill当前进程。 否则判定pte中是否有 COW标志,如果有则分配新的内存页,初始化,加映射。 这里有个注意点, 分配的新物理页,不应再带 COW 标志,否则会在后续对 copy_out函数的处理中,反复分配新页。(如果不理解,看完对 copyout的处理后,再来看这句话应该就能理解了)。
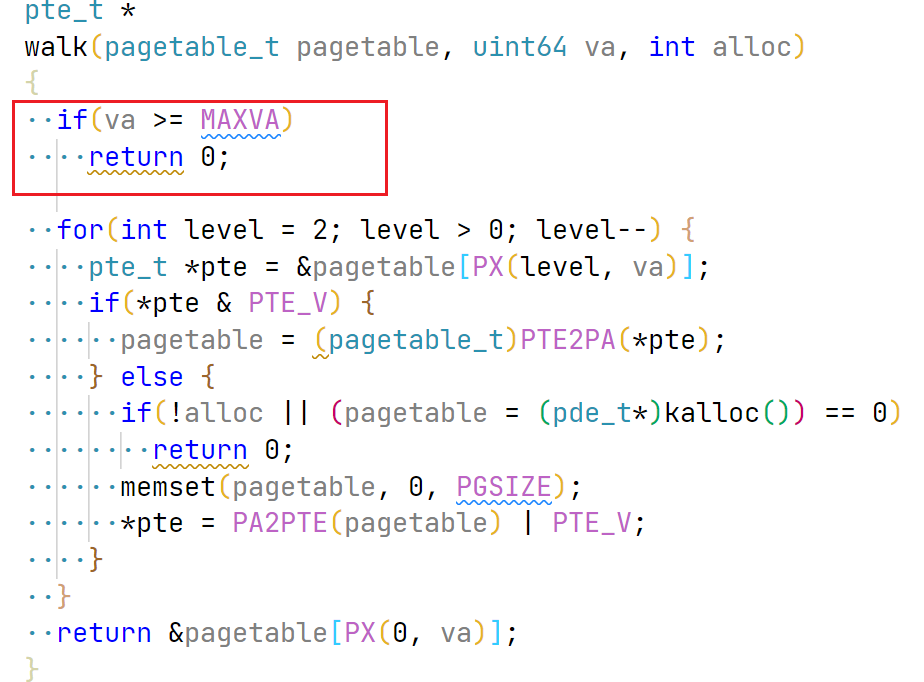
修改walk函数,增加对VA超过MAXVA的处理,这部分原因未深入研究,在usertests中会存在这样的case:
接着增加对物理页的引用计数。
前文已经提到,我采用的是单独分配一篇内存来做引用计数,每个页的引用计数宽度为一个 int。
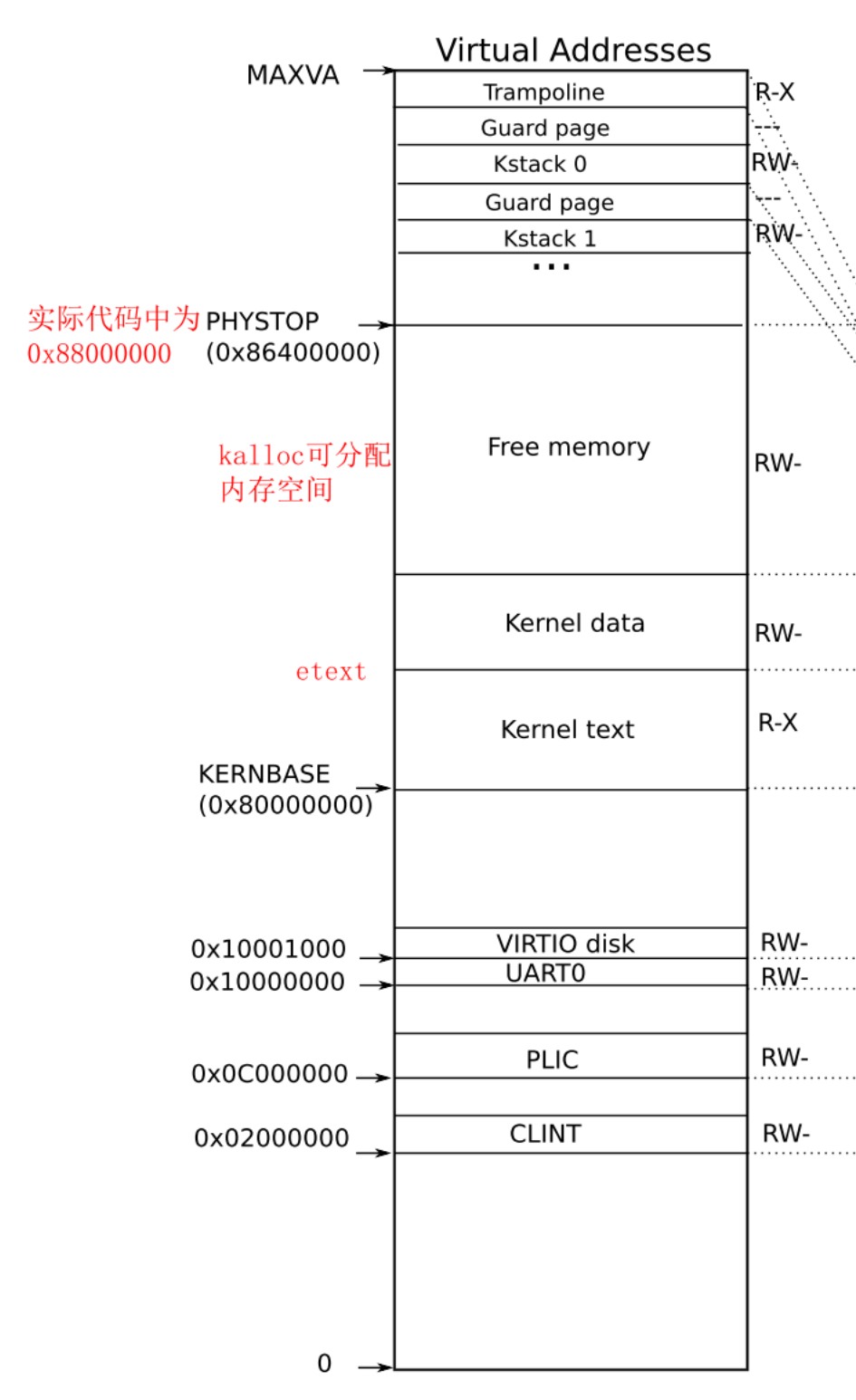
我才用的方案示意图如下:
再贴一个原xv6 kernel space映射,方便对比:
可以看到我将原xv6 space的free memory做了分割,增加了 ref array和padding两个段,ref array 为引用计数数组,padding主要是为了新的free memory是4K对齐而作的padding。
下文的所有变量和说明对应的为我个人方案图中,如free memory为个人方案图中的free memory,而不是xv6原版中的free memory
为实现本方案,在kalloc.c文件中,增加两个全局变量:
1 2 int *pg_ref_arr; char *avail_mem_start;
修改 kinit函数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 void kinit () { initlock(&kmem.lock, "kmem" ); char *pa_start = (char *)PGROUNDUP((uint64)end); char *pa_end = (char *)PGROUNDDOWN(PHYSTOP); pg_ref_arr = (int *)pa_start; avail_mem_start = (char *)PGROUNDUP((uint64)(pa_start + (pa_end - pa_start) / 1025 )); printf ("pg_ref_arr start:%p, avail mem start:%p\n" , pg_ref_arr, avail_mem_start); printf ("max page:%d\n" , (uint64)(pa_end - avail_mem_start) / 4 ); if ((uint64)avail_mem_start % PGSIZE != 0 ) { panic("avail mem is not 4K-aligned" ); } memset (pg_ref_arr, 0 , (uint64)avail_mem_start - (uint64)pg_ref_arr); freerange(avail_mem_start, pa_end); }
关键的计算为:
1 avail_mem_start = (char *)PGROUNDUP((uint64)(pa_start + (pa_end - pa_start) / 1025 ));
计算公式为:
$$
\frac{free_memory}{4096} = \frac{ref_array}{4}
$$
因为ref_array为int,xv6为64位系统,所以这里除4。
$$
free_memory = pa_end - pa_start - ref_array - padding
$$
代入后,可求得:
$$
ref_array = (pa_end - pa_start) / 1025
$$
这里直接向下取整,代表对padding的处理。
同时增加 pg_ref 和 pg_unref函数,用于引用计数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 void pg_ref (void * pa) { if ((char *)pa < avail_mem_start) { panic("pg_ref: pa is less than avil_mem_start" ); } acquire(&kmem.lock); int idx = ((uint64)pa - (uint64)avail_mem_start) / PGSIZE; pg_ref_arr[idx]++; release(&kmem.lock); } void pg_unref (void * pa) { if ((char *)pa < avail_mem_start) { panic("pg_ref: pa is less than avil_mem_start" ); } acquire(&kmem.lock); int idx = ((uint64)pa - (uint64)avail_mem_start) / PGSIZE; pg_ref_arr[idx]--; if (pg_ref_arr[idx] == 0 ) { release(&kmem.lock); kfree(pa); } else { release(&kmem.lock); } }
这里的注意点是加解锁问题(虽然感觉不处理应该也能过),因为可能存在同时加减引用计数,所以需要使用锁保护(或许可以使用一个单独的lock?)。
修改 kalloc和 kfree函数, 增加对引用计数的处理:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 void kfree (void *pa) { struct run *r ; if (((uint64)pa % PGSIZE) != 0 || (char *)pa < end || (uint64)pa >= PHYSTOP) panic("kfree" ); acquire(&kmem.lock); int idx = ((uint64)pa - (uint64)avail_mem_start) / PGSIZE; if (pg_ref_arr[idx] != 0 ) { release(&kmem.lock); printf ("kfree: pa:%p, idx:%d, ref cnt:%d\n" , pa, idx, pg_ref_arr[idx]); panic("kfree a page with ref cnt being non-zero" ); } memset (pa, 1 , PGSIZE); r = (struct run*)pa; r->next = kmem.freelist; kmem.freelist = r; release(&kmem.lock); } void *kalloc (void ) { struct run *r ; acquire(&kmem.lock); r = kmem.freelist; if (r) kmem.freelist = r->next; release(&kmem.lock); if (r) { memset ((char *)r, 5 , PGSIZE); pg_ref((void *)r); } return (void *)r; }
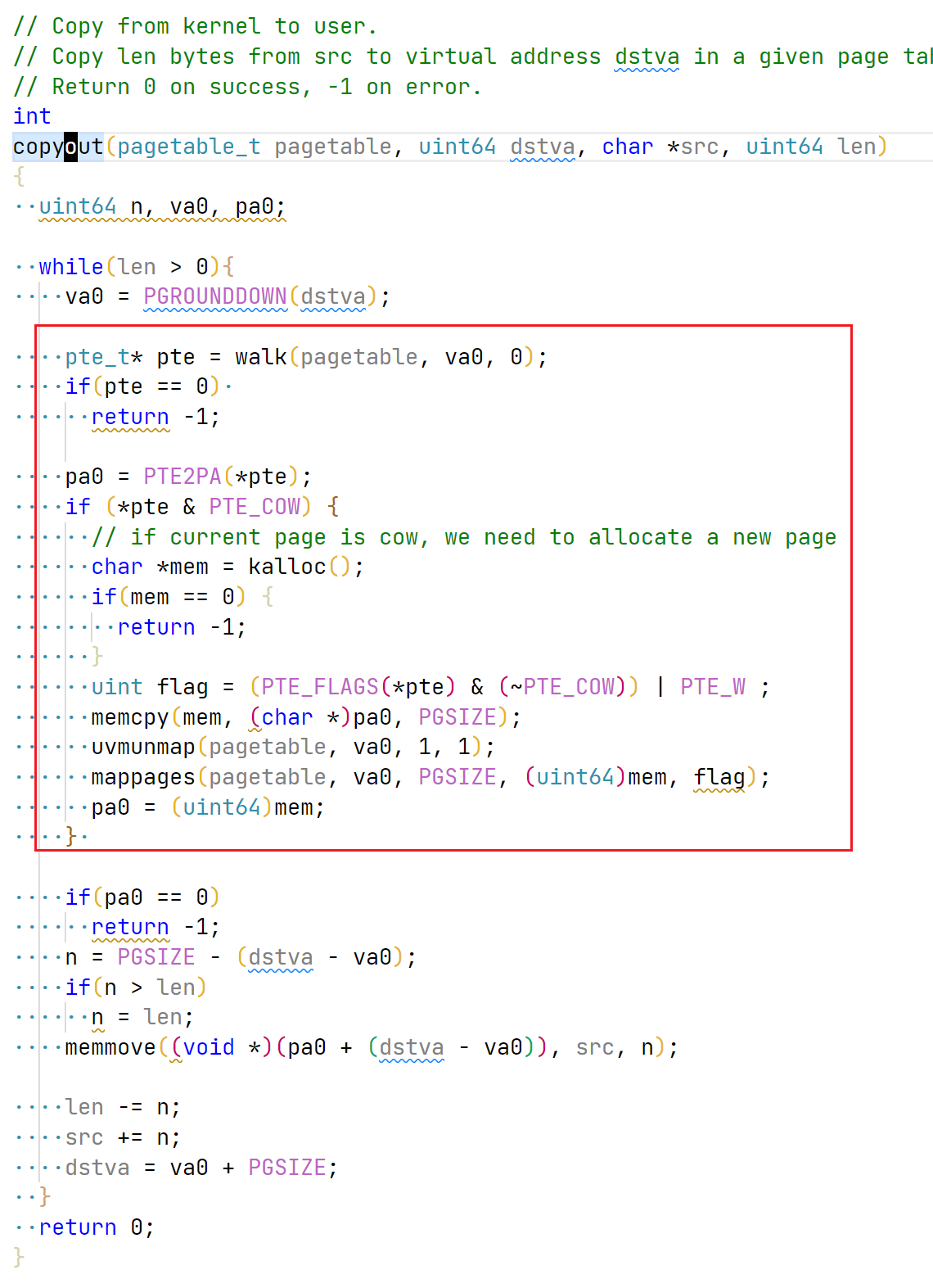
最后修改 copyout,将内核空间的内存拷贝到用户空间,处理方式和之前的page fault一致。
可能有同学会问,为什么需要单独处理 copyout, 而不是用page fault handler统一处理,因为此时处于内核空间,采用的是内核页表,对于 dstva的读写,并不会引起page fault。另外,即使引起了page fault,也不会采用usertrap处理,而是使用kerneltrap处理。所以此处需要单独做处理。
3. 总结·
cow可以极大减少一些不必要的拷贝,是page table的扩展应用之一,目前也被许多OS实现。从实现来看,也不算难,唯一的疑问在于对每一个物理页都采用一个引用计数的开销是不是比较大?不过暂时不做深入研究。