public: // Create a new SkipList object that will use "cmp" for comparing keys, // and will allocate memory using "*arena". Objects allocated in the arena // must remain allocated for the lifetime of the skiplist object. explicitSkipList(Comparator cmp, Arena* arena);
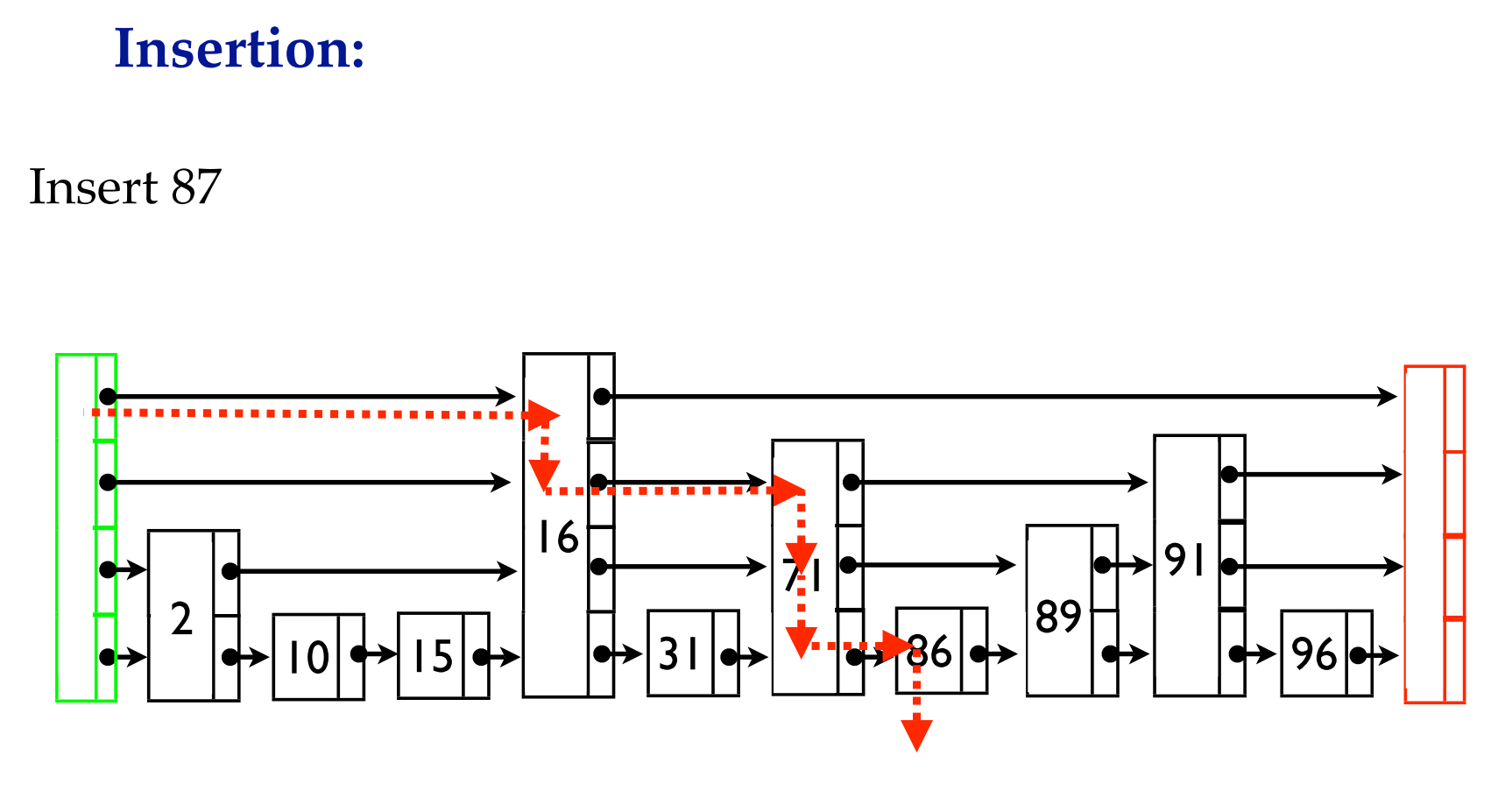
template <typename Key, classComparator> void SkipList<Key, Comparator>::Insert(const Key& key) { // TODO(opt): We can use a barrier-free variant of FindGreaterOrEqual() // here since Insert() is externally synchronized. // prev存放搜索路径 Node* prev[kMaxHeight]; // 设置搜索路径 Node* x = FindGreaterOrEqual(key, prev);
// 不允许出现相同节点 // Our data structure does not allow duplicate insertion assert(x == nullptr || !Equal(key, x->key));
// 采用随机height确定新节点能插入的最高高度 int height = RandomHeight(); if (height > GetMaxHeight()) { for (int i = GetMaxHeight(); i < height; i++) { prev[i] = head_; } // 更新最高高度 // It is ok to mutate max_height_ without any synchronization // with concurrent readers. A concurrent reader that observes // the new value of max_height_ will see either the old value of // new level pointers from head_ (nullptr), or a new value set in // the loop below. In the former case the reader will // immediately drop to the next level since nullptr sorts after all // keys. In the latter case the reader will use the new node. max_height_.store(height, std::memory_order_relaxed); }
// 插入新节点 x = NewNode(key, height); for (int i = 0; i < height; i++) { // NoBarrier_SetNext() suffices since we will add a barrier when // we publish a pointer to "x" in prev[i]. x->NoBarrier_SetNext(i, prev[i]->NoBarrier_Next(i)); prev[i]->SetNext(i, x); } }
// Iteration over the contents of a skip list classIterator { public: // Initialize an iterator over the specified list. // The returned iterator is not valid. explicitIterator(const SkipList* list);
// Returns true iff the iterator is positioned at a valid node. boolValid()const;
// Returns the key at the current position. // REQUIRES: Valid() const Key& key()const;
// Advances to the next position. // REQUIRES: Valid() voidNext();
// Advances to the previous position. // REQUIRES: Valid() voidPrev();
// Advance to the first entry with a key >= target voidSeek(const Key& target);
// Position at the first entry in list. // Final state of iterator is Valid() iff list is not empty. voidSeekToFirst();
// Position at the last entry in list. // Final state of iterator is Valid() iff list is not empty. voidSeekToLast();
template <typename Key, classComparator> inlinevoid SkipList<Key, Comparator>::Iterator::Prev() { // Instead of using explicit "prev" links, we just search for the // last node that falls before key. assert(Valid()); node_ = list_->FindLessThan(node_->key); if (node_ == list_->head_) { node_ = nullptr; }