原文名:Efficient Compactions between Storage Tiers with PrismDB
LSM树针对冷热数据的优化。热放在3D XPoint NVM设备,冷放QLC NAND。
贡献点:
- 多层设计。 DRAM + NVM + flsah.
- Popularity scoring方式, 文中的MSC指标用作compaction选择的依据。
总结:相比 Mutant, 用MSC作为转冷的指标感觉更好。读采用了DRAM Btree和NVM加速,写用NVM slab做buffer,flash上采用sst加速。
PrismDB Design·
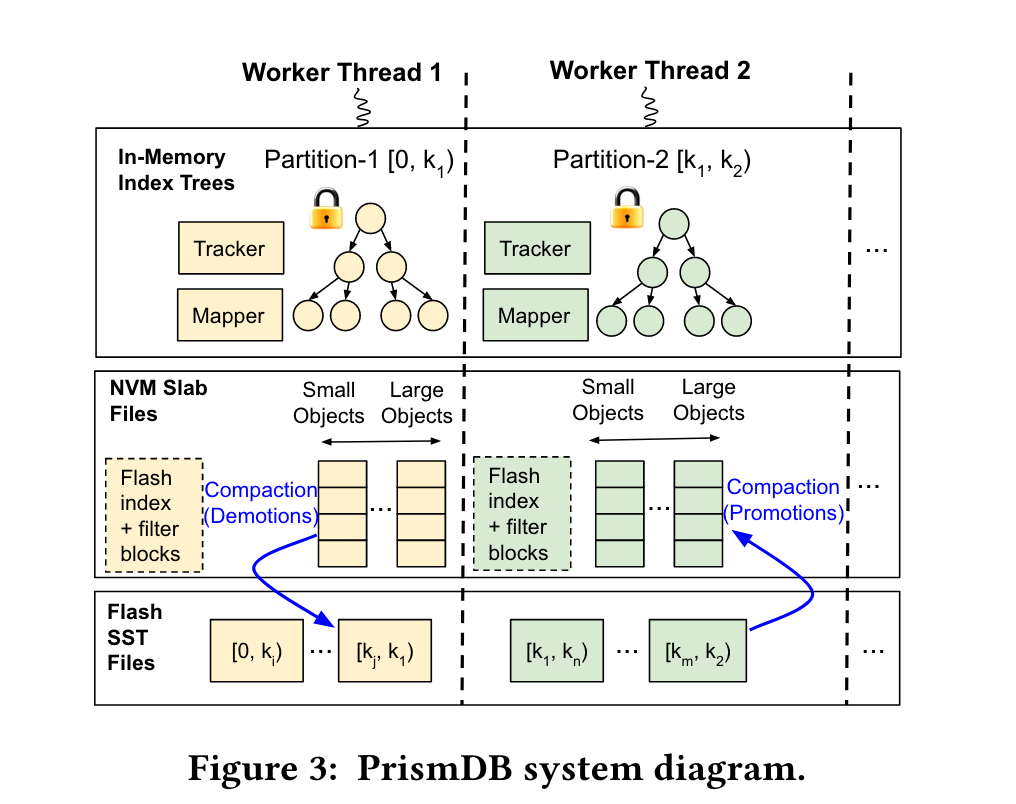
整体架构·
PrismDB采用key分区实现shard-nothing,保证无锁,避免过多同步开销。 (笔者注:估计是根据key分区拆成多个cf?)但是分区策略交给用户决定,key range或者hash range。
所有metadata(index、bloom filter)都存在当DRAM和NVM中。NVM数据是unsorted的,Flash的数据是sorted。每个分区在DRAM中有两个组件:tracker和mapper。
tracker用于评估key的流行度,使用clock算法。
mapper决策value在不同的device的placement。把NVM中最old的一部分数据搬移到flash中。搬移使用 multi-tiered storage compaction(MSC)算法。
内存结构·
下面介绍各device的数据结构:
- in mem: mem使用B tree作为index,用于索引nvm中的数据。每个索引保存key和key所对应的nvm地址(1字节slab id+字节page offset)。 此外还有tracker维护的clock算法,每个tracker entry是key和1字节的clock meta。
文中还描述了这样一句话,暂时不理解是什么意思。 PrismDB does not use a userspace DRAM cache for caching frequently-read objects and instead relies on the OS page cache.
- in nvm: nvm中采用了slab策略保存数据,所有新数据都先插入到NVM中。slab维护了一组fixed size的slot(从100B,200B到1KB)。 此外还维护了flash数据的index,对每个flash上的文件,维护了bloom filter。 index + filter的大小 range from 100MB 到GB级别。
- in flash: 存放sst。 看NVM的大小,如果NVM很大,sst搞一层就行,如果NVM比较小,sst可以搞多层。(笔者注:这和19年的一篇韩国人FAST文章架构不是差不多一样?只不过本文加了冷热)
写入object的生命周期·
NVM容量达到98%(可调)后,启动demote流程,识别cold数据,通过compaction迁移到flash,直到容量降到95%(可调)。 如果flash上的hot object过多通过promote流程迁移到NVM。
为了避免把NVM容量撑爆,加了rate limiter.
流行度tracking·
Tracker: 轻量级tracking objects。使用clock 剔除算法(近似LRU,更好space saving),clock算法追踪的key只有全局key range的10%。
Mapper: Pinning threshold algorithm.。 根据clock 算法bits ,按rank降序,高于保留阈值的,deremote。高bit且低于保留阈值,则保留在NVM中,低bit也低于阈值的,随机丢。
Multi-Tiered Storage Compaction·
compaction两个作用:
- 回收垃圾
- 冷热迁移
Compaction cost and benefit建模:
设计目标: 尽可能将更多的cold object转移到slow storage。并且只从write角度考虑,因为write少的将保持stable。
Benifit:
定义每个对应的coldness: coldness的定义域为[0,1)。 $$ coldness(j) = \frac{1}{clock_j + 1} $$ $clock_j$ 是每个key的clock value。对于从未出现过的key,clock value 为0. 对于一个key range, 其coldness是整个key range 的coldness纸盒。
Cost
cost定义成compaction导致的flash的IO次数。
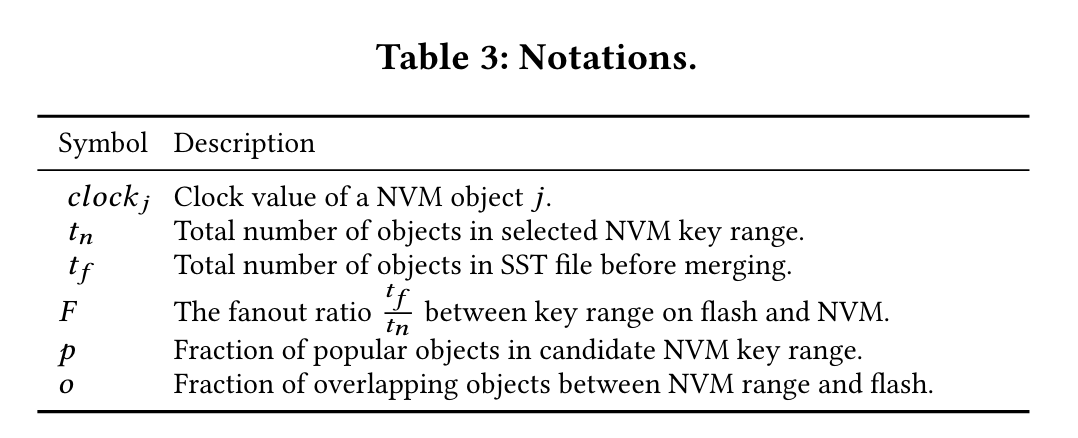
最终推导出的io cost为, (推导过程不想写了) $$ cost = F\times \frac{2- o}{ (1 - p)} + 1 $$ 各参数含义:
最终的MSC(multi-tiered storage compaction) 定义为 benefit / cost
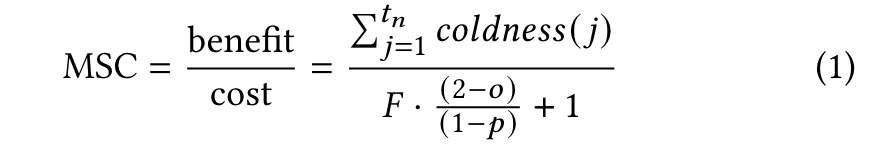
即单位io成本上的冷度。 该值越大,代表一个key range越冷,应该越先迁移(compaction)
笔者注: 在没发生compaction前,怎么提前知道NVM中的range和flash的range的overlap object个数的?
问题是上述公式如果要精确计算,需要耗费过多cpu。作者又提出了近似计算。具体做法是将一个key range进一步拆分成多个固定大小的range(称为一个bucket),对每个bucket做近似计算,然后总体的MSC value是所有bucket的加权和。
key range选择: 选择哪个key range来compaction?这里采用 power-of-k choices 算法选择,k设置为8.
“Power-of-k choices” 算法是一种用于负载均衡的策略,它通过在将任务分配给服务器时选择多个服务器中的最佳服务器来提高效率。 与其随机地将每个任务分配给一个服务器,该算法会随机选择 k 个服务器,然后将任务分配给这 k 个服务器中负载最轻的服务器。
同时为了适应read heavy workload, 添加了 read trigger compaction(笔者注:记得leveldb就有?)
实现·
下图展示了PrismDB的读写、后台流程。每个partition都有两个worker,前台worker处理读写,更新key热度,更新tracker和mapper。后台worker处理compaction,将cold object搬移到flash device中。
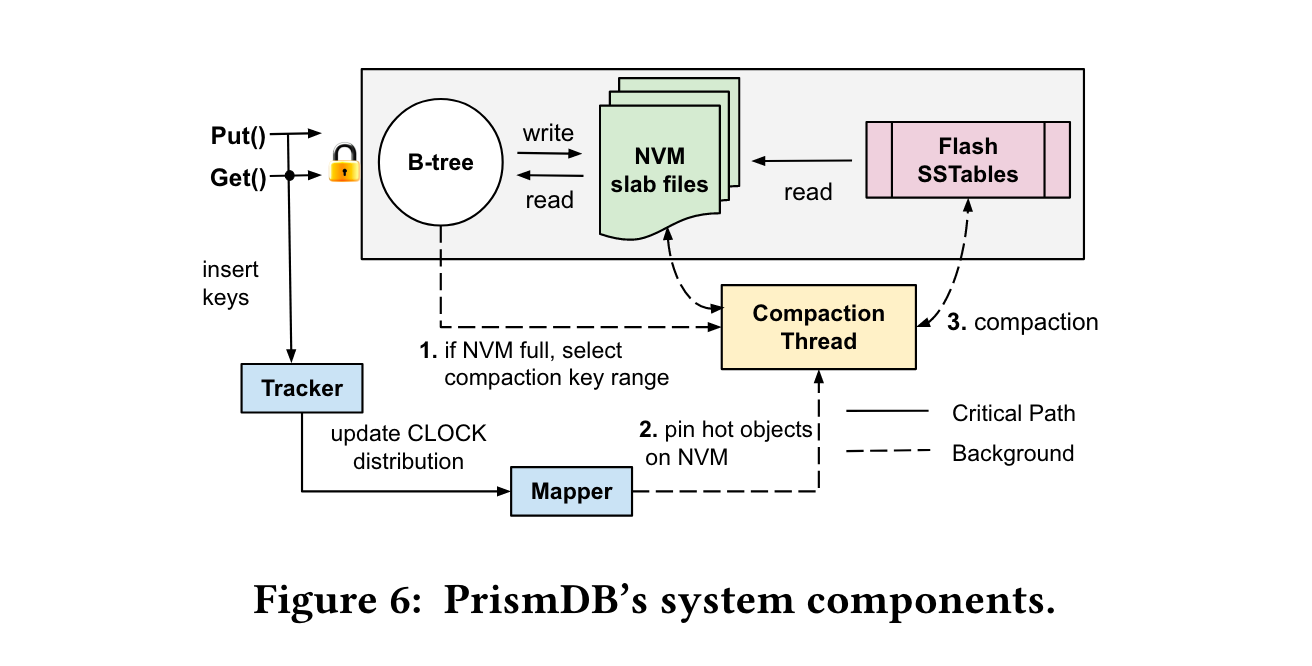
支持4种接口。 Put, Get, Delete和Scan。
Tracker和Mapper更新, Tracker由Intel TBB lib实现的并发hash map记录。key是插入的object key, value是1字节,其中2bit用于clock算法记录热度,1bit用于记录该key的位置是在NVM上还是flash上。 每次插入也可能触发eviction。 mapper是一个数组,包含四个atomic interger,每个slot记录对应clock value有多个key。
Compaction Thread: 使用MSC指标选择要compaction的range。(笔者注:结合上文所的 power of k chioces. 应该是随机选8个key range, 比较它们的MSC指标,选择最小的来compaction)
Bucket实现 每个Bucket设置为64K个keys,然后把key range划分为连续的多个bucket空间。(笔者注: 那bucket还会分裂、合并吗?文章没有提,然而这个很重要)每个bucket包含四个字段: num_nvm_keys (a counter of the number of keys present on NVM), pop_bitmap (a bitmap of key popularity), nvm_bitmap (a bitmap of keys on NVM), and flash_bitmap (a bitmap of keys on flash).
Put操作增加num_nvm_keys, compaction操作减少num_nvm_keys, Gets操作将pop_bitmap对应位置为1,eviction操作将对应位置设置为0。 nvm_bitmap 和 flash_bitmap 很直观,这两个字段作用是用来计算overlap率的。
有了这4个字段,就可以粗略计算MSC指标了。
评估·
略。

