Linux文件系统基础知识·
Linux文件系统基础知识
本文整理自《鸟哥的Linux私房菜-基础学习篇》
我们都知道,在Linux下,文件除了文件本身的数据外,还有非常多的其他属性(如文件的权限,所属者,时间参数等等)。Linux文件系统是如何实现它们的呢?
1. Linux文件系统特性·
文件系统通常会将这两部分的数据分别存放在不同的区块中,权限与属性放置到 inode 中,至于实际数据则放置到 data block 区块中 ,除此之外,还有一个超级区块 (superblock) 会记录整个文件系统的整体信息,包括 inode 与 block 的总量、使用量、剩余量等。
i> tips: 通过dumpe2fs + 设备名 查看文件系统的信息。如 dumpe2fs /dev/sda1
每个 inode 与 block 都有编号,至于这三个数据的意义可以简略说明如下:
- superblock:记录此 filesystem 的整体信息,包括inode/block的总量、使用量、剩余量, 以及文件系统的格式与相关信息等;
- inode:记录文件的属性,一个文件占用一个inode,同时记录此文件的数据所在的 block 号码;
- block:实际记录文件的内容,若文件太大时,会占用多个 block 。
我们将inode和block的存储方式用图来说明一下:
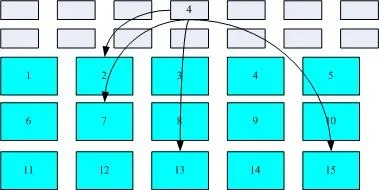
上图的灰色区块表示的是inode区块,蓝青色(是这个色???)区块表示的是block区块。4号inode区块将存储文件的属性及权限信息,同时还包含了实际存储文件内容的block编号。通过读取inode,我们可以一次性将所有block编号得到,操作系统就能够据此来排列磁盘的读取顺序,可以一口气将四个 block 内容读出来 !
i> tips: inode+block的这种存储方式被称为索引式文件系统。
为说明inode+block的这种方式的优势,我们拿FAT为例进行对比。它的存储方式如下图:
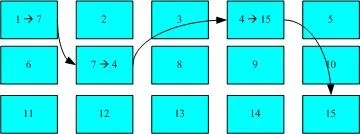
FAT是无法将这个文件的所有block一开始就读取出来的,它更像是一个链表,只要读到一块才能知道下一块在哪里。这样的致命缺点是,当数据在磁盘上分布得过于分散时,磁盘将多转几圈才能完整的读取到这个文件的内容。
i> tips: 要解决FAT由于数据分布过散而导致的性能降低问题,我们常常会使用“磁盘重组“技术,通过重组将同一个文件所属的 blocks 汇整在一起,这样数据的读取会比较容易啊!
2. Linux 的 EXT2 文件系统(inode)·
如同前一小节所说的,inode 的内容在记录文件的权限与相关属性,至于 block 区块则是在记录文件的实际内容。 而且文件系统一开始就将 inode 与 block 规划好了,除非重新格式化(或者利用 resize2fs 等指令变更文件系统大小),否则 inode 与 block 固定后就不再变动。但是如果仔细考虑一下,如果我的文件系统高达数百GB时, 那么将所有的 inode 与 block 通通放置在一起将是很不智的决定,因为 inode 与block 的数量太庞大,不容易管理 。所以**Ext2采用了多个区块群组 (block group )**来进行管理。如下图:
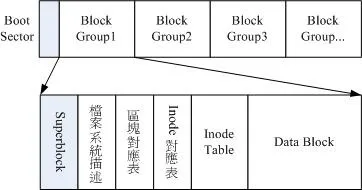
每个区块群组都有独立的inode/block/superblock 系统。
- 文件系统的最开始Boot Sector(开机山区)其实和我们存储数据没多大关系,但是这个开机扇区可以安装开机管理程序,这样我们就可以将不同的开机管理程序安装到个别的文件系统了。这样不用覆盖整个磁盘唯一的MBR,才能制作多重开机环境啊。
现在我们再来详细的解释每个区群里面的内容。
2.1 data block (数据区块)·
data block 是用来放置文件内容数据地方,在 Ext2 文件系统中所支持的 block 大小有 1K, 2K 及 4K 三种 ,在格式化时 block 的大小就固定了,且每个 block 都有编号,以方便 inode 的记录。由于 block 大小的差异,会导致该文件系统能够支持的最大磁盘容量与最大单一文件大小并不相同。 因为 block 大小而产生的 Ext2 文件系统限制如下 :
| Block 大小 | 1KB | 2KB | 4KB |
|---|---|---|---|
| 最大单一文件限制 | 16GB | 256GB | 2TB |
| 最大文件系统总容量 | 2TB | 8TB | 16TB |
至于为什么会出现这样的现象,得在了解了inode结构之后才能解释。
除此之外 Ext2 文件系统的 block 还有什么限制呢?有的!基本限制如下:
- 原则上,block 的大小与数量在格式化完就不能够再改变了(除非重新格式化);
- 每个 block 内最多只能够放置一个文件的数据;
- 承上,如果文件大于 block 的大小,则一个文件会占用多个 block 数量;
- 承上,若文件小于 block ,则该 block 的剩余容量就不能够再被使用了(磁盘空间会浪费)。
2.2 inode table(inode表)·
现在来谈谈inode吧。它记录了文件的属性以及实际存储文件的block的编号。特性包含以下几点:
- 每个 inode 大小均固定为 128 Bytes (新的 ext4 与 xfs 可设置到 256 Bytes);
- 每个文件都仅会占用一个 inode 而已;
- 承上,因此文件系统能够创建的文件数量与 inode 的数量有关;
- 系统读取文件时需要先找到 inode,并分析 inode 所记录的权限与使用者是否符合,若符合才能够开始实际读取 block 的内容。
细心的读者应该有注意到inode大小仅有128字节,这么点大小却要存放相当多的内容。我们来简单的举个例子说明一下:假设存放一个block需要4字节的大小,现有一个400M的文件,并假定文件系统格式化时指定的block大小为4k,那我们需要十万笔block编号才能存储这样文件!
好在Ext2的设计者们早就想到了解决办法,很聪明的将 inode 记录 block 号码的区域定义为12个直接,一个间接, 一个双间接与一个三间接记录区 。结构可见下图:
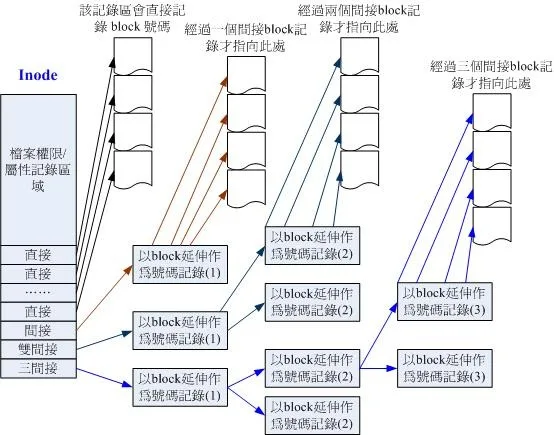
图最左边为 inode 本身 (128 Bytes),里面有 12 个直接指向 block 号码的对照,这 12 笔记录就能够直接取得 block 号码啦! 至于所谓的间接就是再拿一个 block 来当作记录 block 号码的记录区,如果文件太大时, 就会使用间接的 block 来记录号码。如上图当中间接只是拿一个 block 来记录额外的号码而已。 同理,如果文件持续长大,那么就会利用所谓的双间接,第一个 block 仅再指出下一个记录号码的 block 在哪里, 实际记录的在第二个 block 当中。依此类推,三间接就是利用第三层 block 来记录号码啦!
i> 这像不像多级页表呢?
好了,看到这里,我们就可以解释为什么不同block的大小会导致最大单一文件限制以及最大文件系统限制了
以Block大小为1KB为例,我们来计算一波:
- 12个直接记录: 12*1K = 12K
- 一级间接记录:在inode中每个block编号项需要4Bytes,那么1个间接记录block为1K,则有1K/4Bytes项Block编号,最后乘上Block大小即可。也就是:1K/4Bytes x 1K = 256 K
- 二级间接记录:同上解释,256 x 256 x 1K =$ 256^2 $K
- 三级间接记录:同上解释,256 x 256 x 256 x 1K =$ 256^3 $K
所以将所有记录相加,可得:12 + 256 + 256256 + 256256*256 (K) = 16GB 。这就是为什么block size =1 K的时候,最大单一文件只能有16G了。
2.3 Superblock (超级区块)·
Superblock 是记录整个 filesystem 相关信息的地方, 他记录的信息主要有:
- block 与 inode 的总量;
- 未使用与已使用的 inode / block 总数量;
- block 与 inode 的大小 (block 为 1, 2, 4K,inode 为 128Bytes 或 256Bytes);
- filesystem 的挂载时间、最近一次写入数据的时间、最近一次检验磁盘 (fsck) 的时间等文件系统的相关信息;
- 一个 valid bit 数值,若此文件系统已被挂载,则 valid bit 为 0 ,若未被挂载,则 valid bit 为 1 。
x> superblock记录的是文件系统的信息,如果 superblock 死掉了, 你的文件系统可能就坏掉咯。在第二节开头我们说过,每个区块群组都有独立的inode/block/superblock 系统。 这就有点矛盾了,因为superblock只用记录文件系统的信息。
事实上除了第一个 block group 内会含有 superblock 之外,后续的 block group 不一定含有 superblock , 而若含有 superblock 则该 superblock主要是做为第一个 block group 内 superblock 的备份咯,这样可以进行 superblock 的救援呢!
2.4 Filesystem Description (文件系统描述说明)·
这个区段可以描述每个 block group 的开始与结束的 block 号码
2.5 block bitmap (区块对照表)·
如果你想要新增文件时总会用到 block 吧!那你要使用哪个 block 来记录呢?当然是选择“空的 block ”来记录新文件的数据啰。 那你怎么知道哪个 block 是空的?这就得要通过 block bitmap 的辅助了。从 block bitmap 当中可以知道哪些 block 是空的,因此我们的系统就能够很快速的找到可使用的空间来处置文件啰。同样的,如果你删除某些文件时,那么那些文件原本占用的 block 号码就得要释放出来, 此时在 block bitmap 当中相对应到该 block 号码的标志就得要修改成为“未使用中”啰!这就是 bitmap 的功能。
2. 6 inode bitmap (inode 对照表)·
同block bitmap相似,inode bitmap 则是记录使用与未使用的 inode 号码啰!
3. inode+block与目录树的关系·
3.1 目录·
要知道目录树,首先得知道什么是目录。目录本质上也是一种文件(要知道linux一切皆文件,虽然网卡先生表示不服),当我们在 Linux 下的文件系统创建一个目录时,文件系统会分配一个 inode 与至少一块 block 给该目录。其中,inode 记录该目录的相关权限与属性,并可记录分配到的那块 block 号码; 而 block 则是记录在这个目录下的文件名与该文件名占用的 inode 号码数据。 目录存储信息结构可见下图:

i> 查看inode信息,可使用 ls -i命令
3.2 文件·
当我们在 Linux 下的 ext2 创建一个一般文件时, ext2 会分配一个 inode 与相对于该文件大小的 block 数量给该文件。
3.3 目录树读取·
通过对目录的说明,你应该知道了文件本身并不存储文件名,文件名仅存放在目录之中,于是当我们通过文件名去访问一个文件时,就必然会经过目录,通过目录的文件名与文件inode的映射关系知道该文件的inode,再进行下一步的操作。现在我们以一个例子来对目录树读取进行说明。
执行lll -di / /etc /etc/passwd 命名,系统会做哪些操作呢?

1./ 的 inode:
通过挂载点的信息找到 inode 号码为 128 的根目录 inode,且 inode 规范的权限让我们可以读取该 block 的内容(有与 x) ;
2./ 的 block:
经过上个步骤取得 block 的号码,并找到该内容有 etc/ 目录的 inode 号码 (33595521);
3.etc/ 的 inode:
读取 33595521 号 inode 得知 dmtsai 具有 r 与 x 的权限,因此可以读取 etc/ 的 block 内容;
4.etc/ 的 block:
经过上个步骤取得 block 号码,并找到该内容有 passwd 文件的 inode 号码 (36628004);
5.passwd 的 inode:
读取 36628004 号 inode 得知 dmtsai 具有 r 的权限,因此可以读取 passwd 的 block 内容;
6.passwd 的 block:
最后将该 block 内容的数据读出来。
其实基本上就是:通过文件名找文件inode->比对inode信息,查看是否有权限访问->找到inode对应的block->反复
4. 日志式文件系统·
i> 日志式文件系统是为了解决数据的不一致状态
4.1 写入数据时的操作·
- 先确定使用者对于欲新增文件的目录是否具有 w 与 x 的权限,若有的话才能新增;
- 根据 inode bitmap 找到没有使用的 inode 号码,并将新文件的权限/属性写入;
- 根据 block bitmap 找到没有使用中的 block 号码,并将实际的数据写入 block 中,且更新 inode 的 block 指向数据;
- 将刚刚写入的 inode 与 block 数据同步更新 inode bitmap 与 block bitmap,并更新 superblock 的内容。
4.2 数据不一致状态·
在一般正常的情况下,上述的新增动作当然可以顺利的完成。但是如果有个万一怎么办? 例如你的文件在写入文件系统时,因为不知名原因导致系统中断(例如突然的停电啊、 系统核心发生错误啊~等等的怪事发生时),所以写入的数据仅有 inode table 及 data block 而已,最后一个同步更新中介数据的步骤并没有做完,此时就会发生 metadata 的内容与实际数据存放区产生不一致 (Inconsistent) 的情况了。
4.3 日志式文件系统 (Journaling filesystem)·
为了避免上述提到的文件系统不一致的情况发生,因此我们的前辈们想到一个方式, 如果在我们的 filesystem 当中规划出一个区块,该区块专门在记录写入或修订文件时的步骤, 那不就可以简化一致性检查的步骤了?也就是说:
- 预备:当系统要写入一个文件时,会先在日志记录区块中纪录某个文件准备要写入的信息;
- 实际写入:开始写入文件的权限与数据;开始更新 metadata 的数据;
- 结束:完成数据与 metadata 的更新后,在日志记录区块当中完成该文件的纪录。

