voidSchedulingGroup::QueueRunnableEntity(RunnableEntity* entity, bool sg_local)noexcept{ FLARE_DCHECK(!stopped_.load(std::memory_order_relaxed), "The scheduling group has been stopped.");
if (FLARE_UNLIKELY(!run_queue_.Push(entity, sg_local))) { auto since = ReadSteadyClock();
while (!run_queue_.Push(entity, sg_local)) { FLARE_LOG_WARNING_EVERY_SECOND( "Run queue overflow. Too many ready fibers to run. If you're still " "not overloaded, consider increasing `flare_fiber_run_queue_size`."); FLARE_LOG_FATAL_IF(ReadSteadyClock() - since > 5s, "Failed to push fiber into ready queue after retrying " "for 5s. Gave up."); std::this_thread::sleep_for(100us); } }
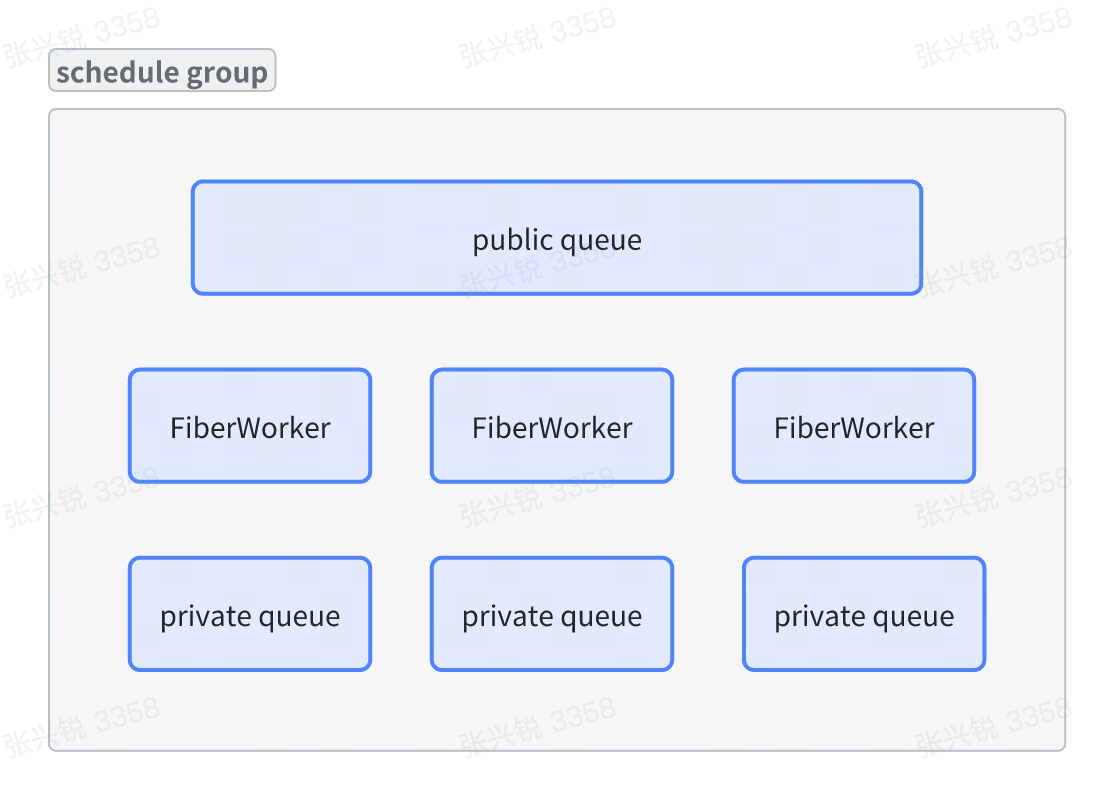
// run_queue_ is the `global` queue of a scheduling group, we call it `public_q` and we need stats of it SG_PUBLIC_QUEUE_COUNTER_INCR; if (FLARE_UNLIKELY(!WakeUpOneWorker())) { no_worker_available->Increment(); } }
boolSchedulingGroup::WakeUpOneSpinningWorker()noexcept{ // FIXME: Is "relaxed" order sufficient here? while (auto spinning_mask = spinning_workers_.load(std::memory_order_relaxed)) { // Last fiber worker (LSB in `spinning_mask`) that is spinning. auto last_spinning = __builtin_ffsll(spinning_mask) - 1; auto claiming_mask = 1ULL << last_spinning; if (FLARE_LIKELY(spinning_workers_.fetch_and(~claiming_mask, std::memory_order_relaxed) & claiming_mask)) { // We cleared the `last_spinning` bit, no one else will try to dispatch // work to it. spinning_worker_wakeups->Add(1); returntrue; // Fast path then. } Pause(); } // Keep trying until no one else is spinning. returnfalse; }
// Emit (a series of) pause(s) to relax CPU. // // This can be used to delay execution for some time, or backoff from contention // in case you're doing some "lock-free" algorithm. template <std::size_t N = 1> [[gnu::always_inline]] inlinevoidPause() { ifconstexpr (N != 0) { Pause<N - 1>(); #if defined(__x86_64__) asmvolatile("pause" ::: "memory"); // x86-64 only. #elif defined(__aarch64__) asmvolatile("yield" ::: "memory"); #elif defined(__powerpc__) // FIXME: **RATHER** slow. asmvolatile("or 31,31,31 # very low priority" ::: "memory"); #else #error Unsupported architecture. #endif } }
boolSchedulingGroup::WakeUpOneDeepSleepingWorker()noexcept{ // We indeed have to wake someone that is in deep sleep then. while (auto sleeping_mask = sleeping_workers_.load(std::memory_order_relaxed)) { // We always give a preference to workers with a lower index (LSB in // `sleeping_mask`). // // If we're under light load, this way we hopefully can avoid wake workers // with higher index at all. auto last_sleeping = __builtin_ffsll(sleeping_mask) - 1; auto claiming_mask = 1ULL << last_sleeping; if (FLARE_LIKELY(sleeping_workers_.fetch_and(~claiming_mask, std::memory_order_relaxed) & claiming_mask)) { // We claimed the worker. Let's wake it up then. // // `WaitSlot` class it self guaranteed no wake-up loss. So don't worry // about that. FLARE_CHECK_LT(last_sleeping, group_size_); wait_slots_[last_sleeping].Wake(); sleeping_worker_wakeups->Add(1); returntrue; } Pause(); } returnfalse; }
// This class guarantees no wake-up loss by keeping a "wake-up count". If a wake // operation is made before a wait, the subsequent wait is immediately // satisfied without actual going to sleep. classalignas(hardware_destructive_interference_size) SchedulingGroup::WaitSlot { public: voidWake()noexcept{ ScopedDeferred _([start = ReadTsc()] { wakeup_sleeping_worker_latency->Report(TscElapsed(start, ReadTsc())); });
if (wakeup_count_.fetch_add(1, std::memory_order_relaxed) == 0) { FLARE_PCHECK(syscall(SYS_futex, &wakeup_count_, FUTEX_WAKE_PRIVATE, 1, 0, 0, 0) >= 0); } // If `Wait()` is called before this check fires, `wakeup_count_` can be 0. FLARE_CHECK_GE(wakeup_count_.load(std::memory_order_relaxed), 0); }
voidWait()noexcept{ if (wakeup_count_.fetch_sub(1, std::memory_order_relaxed) == 1) { do { // TODO(luobogao): I saw spurious wake up. But how can it happen? If // `wakeup_count_` is not zero by the time `futex` checks it, the only // values it can become is a positive one, which in this case is a // "real" wake up. // // We need further investigation here. auto rc = syscall(SYS_futex, &wakeup_count_, FUTEX_WAIT_PRIVATE, 0, 0, 0, 0); FLARE_PCHECK(rc == 0 || errno == EAGAIN); } while (wakeup_count_.load(std::memory_order_relaxed) == 0); } FLARE_CHECK_GT(wakeup_count_.load(std::memory_order_relaxed), 0); }
voidPersistentWake()noexcept{ // Hopefully this is large enough. wakeup_count_.store(0x4000'0000, std::memory_order_relaxed); FLARE_PCHECK(syscall(SYS_futex, &wakeup_count_, FUTEX_WAKE_PRIVATE, INT_MAX, 0, 0, 0) >= 0); }
// Memory locations within the same cache line are subject to destructive // interference, also known as false sharing, which is when concurrent // accesses to these different memory locations from different cores, where at // least one of the concurrent accesses is or involves a store operation, // induce contention and harm performance. // // Microbenchmarks indicate that pairs of cache lines also see destructive // interference under heavy use of atomic operations, as observed for atomic // increment on Sandy Bridge. // // We assume a cache line size of 64, so we use a cache line pair size of 128 // to avoid destructive interference. // // mimic: std::hardware_destructive_interference_size, C++17
voidWait()noexcept{ if (wakeup_count_.fetch_sub(1, std::memory_order_relaxed) == 1) { do { // TODO(luobogao): I saw spurious wake up. But how can it happen? If // `wakeup_count_` is not zero by the time `futex` checks it, the only // values it can become is a positive one, which in this case is a // "real" wake up. // // We need further investigation here. auto rc = syscall(SYS_futex, &wakeup_count_, FUTEX_WAIT_PRIVATE, 0, 0, 0, 0); FLARE_PCHECK(rc == 0 || errno == EAGAIN); } while (wakeup_count_.load(std::memory_order_relaxed) == 0); } FLARE_CHECK_GT(wakeup_count_.load(std::memory_order_relaxed), 0); }
if (wakeup_count_.fetch_add(1, std::memory_order_relaxed) == 0) { FLARE_PCHECK(syscall(SYS_futex, &wakeup_count_, FUTEX_WAKE_PRIVATE, 1, 0, 0, 0) >= 0); } // If `Wait()` is called before this check fires, `wakeup_count_` can be 0. FLARE_CHECK_GE(wakeup_count_.load(std::memory_order_relaxed), 0); }
// Notify the framework that any pending operations can be performed. NotifyThreadOutOfDutyCallbacks(); } FLARE_CHECK_EQ(GetCurrentFiberEntity(), GetMasterFiberEntity()); sg_->LeaveGroup(); }
FiberEntity* SchedulingGroup::SpinningAcquireFiber( FiberWorker* worker)noexcept{ // We don't want too many workers spinning, it wastes CPU cycles. staticconstexprauto kMaximumSpinners = 2;
FiberEntity* fiber = nullptr; auto spinning = spinning_workers_.load(std::memory_order_relaxed); auto mask = 1ULL << worker_index_; bool need_spin = false;
// Simply test `spinning` and try to spin may result in too many workers to // spin, as it there's a time windows between we test `spinning` and set our // bit in it. while (CountNonZeros(spinning) < kMaximumSpinners) { // cas操作,看能否把当前的worker index上到这个spinning中 FLARE_DCHECK_EQ(spinning & mask, 0); if (spinning_workers_.compare_exchange_weak(spinning, spinning | mask, std::memory_order_relaxed)) { need_spin = true; break; } } if (need_spin) { // 如果mark成功,说明当前worker可以进入spinning状态 staticconstexprauto kMaximumCyclesToSpin = 10'000; // Wait for some time between touching `run_queue_` to reduce contention. staticconstexprauto kCyclesBetweenRetry = 1000; auto start = ReadTsc(), end = start + kMaximumCyclesToSpin; // ReadTsc的实现为:__rdtsc, 返回cpu自启动以来的时钟周期数
ScopedDeferred _([&] { // Note that we can actually clear nothing, the same bit can be cleared by // `WakeOneSpinningWorker` simultaneously. This is okay though, as we'll // try `AcquireFiber()` when we leave anyway. spinning_workers_.fetch_and(~mask, std::memory_order_relaxed); });
do { // spinning 开始 if (auto rc = AcquireFiber(worker)) { // 尝试拿fiber entity fiber = rc; break; // 拿到就break } auto next = start + kCyclesBetweenRetry; while (start < next) { // 这个循环最多耗费 kCyclesBetweenRetry 个时钟周期,注意到工作是wakeup在睡眠的worker(如果需要的话),要么就pause,减少锁竞争 if (pending_spinner_wakeup_.load(std::memory_order_relaxed) && pending_spinner_wakeup_.exchange(false, std::memory_order_relaxed)) { // There's a pending wakeup, and it's us who is chosen to finish this // job. WakeUpOneDeepSleepingWorker(); } else { Pause<16>(); } start = ReadTsc(); } // 最多过了 kCyclesBetweenRetry 个时钟周期 } while (start < end && // spinning的最长周期没到,且没有其他人标记本fiber worker可以去拿fiber entity(这个动作在 WakeUpOneSpiningWorker函数中,上文已经分析) (spinning_workers_.load(std::memory_order_relaxed) & mask)); } else { // Otherwise there are already at least 2 workers spinning, don't waste CPU // cycles then. returnnullptr; } // 要么已经拿到fiber,要么其他人通知本fiber worker可以去拿fiber entity了 if (fiber || ((fiber = AcquireFiber(worker)))) { // 本fiber worker有事可以做,但系统内少了一个在spining的worker,所以这里标记一下 `pending_spinner_wakeup_`, 让其他在spinning的worker去唤醒另一个worker来做spinning,既可以保证本fiber可以快速去做fiber entity,又可以减少唤醒一个worker的开销。个人感觉是flare fiber调度算法里面值得借鉴的设计 // Given that we successfully grabbed a fiber to run, we're likely under // load. So wake another worker to spin (if there are not enough spinners). // // We don't want to wake it here, though, as we've had something useful to // do (run `fiber)`, so we leave it for other spinners to wake as they have // nothing useful to do anyway. if (CountNonZeros(spinning_workers_.load(std::memory_order_relaxed)) < kMaximumSpinners) { pending_spinner_wakeup_.store(true, std::memory_order_relaxed); } } return fiber; }
FiberEntity* FiberWorker::StealFiber(){ if (victims_.empty()) { returnnullptr; }
++steal_vec_clock_; while (victims_.top().next_steal <= steal_vec_clock_) { auto&& top = victims_.top(); if (auto rc = top.sg->RemoteAcquireFiber()) { // We don't pop the top in this case, since it's not empty, maybe the next // time we try to steal, there are still something for us. return rc; } victims_.push({.sg = top.sg, .steal_every_n = top.steal_every_n, .next_steal = top.next_steal + top.steal_every_n}); victims_.pop(); // Try next victim then. } returnnullptr; }
while (true) { ScopedDeferred _([&] { // If we're woken up before we even sleep (i.e., we're "woken up" after we // set the bit in `sleeping_workers_` but before we actually called // `WaitSlot::Wait()`), this effectively clears nothing. sleeping_workers_.fetch_and(~mask, std::memory_order_relaxed); // wakeup时,保证sleeping_workers对应的bit是0 }); FLARE_CHECK_EQ( // check本worker还没有sleep,并且把当前worker标记为sleep sleeping_workers_.fetch_or(mask, std::memory_order_relaxed) & mask, 0);
// We should test if the queue is indeed empty, otherwise if a new fiber is // put into the ready queue concurrently, and whoever makes the fiber ready // checked the sleeping mask before we updated it, we'll lose the fiber. if (auto f = AcquireFiber(worker)) { // 这里必须再次获取,不然可能会丢fiber // A new fiber is put into ready queue concurrently then. // // If our sleeping mask has already been cleared (by someone else), we // need to wake up yet another sleeping worker (otherwise it's a wakeup // miss.). // // Note that in this case the "deferred" clean up is not needed actually. // This is a rare case, though. TODO(luobogao): Optimize it away. if ((sleeping_workers_.fetch_and(~mask, std::memory_order_relaxed) & mask) == 0) { // 清空sleep_workers对应的mask bit // Someone woken us up before we cleared the flag, wake up a new worker // for him. WakeUpOneWorker(); // TODO(zhangxingrui): 不理解这里为什么需要唤醒其他人,或许是为了保证系统正在做的worker数量更多,加大并发? } return f; }
wait_slots_[worker_index_].Wait(); // wait
// We only return non-`nullptr` here. If we return `nullptr` to the caller, // it'll go spinning immediately. Doing that will likely waste CPU cycles. if (auto f = AcquireFiber(worker)) { // 有人把我唤醒,尝试看有没有fiber需要做 return f; } // Otherwise try again (and possibly sleep) until a fiber is ready. } }