SOSP2007:Dynamo: Amazon’s Highly Available Key-value Store·
本文采用wolai制作,原文link: https://www.wolai.com/ravenxrz/kfYbMeDC9eMYTdGs2sqjJS
Dynamo 是一个分布式存储系统,设计目标是提供高可用性和可扩展性,同时牺牲一定的数据一致性。以下是其主要特点和机制的总结:
- 接口与特性:
- 提供简单的键值(KV)接口,不支持复杂命名空间。
- 不保证ACID特性,优先确保系统可用性,采用最终一致性模型。
- 写冲突解决推迟到读取阶段,并由用户决定如何处理。
- 分区与复制:
- 使用一致性哈希进行分区,通过虚拟节点(VNODE)解决负载不均和节点异构问题。
- 每个键被复制到多个节点上,通过协调节点完成写入,副本分布基于一致性哈希环。
- 冲突解决:
- 采用向量时钟记录版本信息,用于检测因果关系和冲突。
- 在读取时发现冲突后,交由客户端合并不同版本。
- Quorum 协议:
- 读写操作需满足一定数量的节点响应(R 和 W 参数),以确保数据一致性和可用性。
- 故障处理:
- 临时故障:引入Hinted Handoff机制,允许将数据写入备用节点并在原节点恢复后移交。
- 永久故障:利用Merkle树识别差异并同步数据。
- 成员变更与故障检测:
- 借助Gossip协议传播成员状态,动态更新集群视图。
- 故障检测通过节点间通信实现,结合Gossip传播不可达信息。
- 一致性哈希优化:
- 初始使用随机令牌分配,逐步演进为固定大小分区加均匀令牌分布,显著提升负载均衡和迁移效率。
- 其他优化:
- Read Repair:在读取过程中修复过期副本。
- 协调节点选择:灵活选择偏好列表中的任意节点作为写操作协调器,避免单点瓶颈。
总体而言,Dynamo通过去中心化设计、多副本机制以及灵活的冲突解决策略,在大规模分布式环境中实现了高性能和高可用性,但对数据一致性的要求较低。
特点·
Dynamo设计假设和特点:
- 仅提供单kv的接口,接口简单,没有命名空间的概念(对比文件系统而言)
SIGOPS2010:Cassandra提供了列族的概念
- 不提供ACID完整特性,优先保证可用性,无隔离性,采用最终一致性,故障可能产生写冲突,一般存储系统可能会在写阶段来解决冲突(保证读简单),并采用last write last win的策略,但是坏处是可能带来停写(比如在解决写冲突的时候超时了),Dynamo设计的目标是 “始终可写”,解决冲突的时机转移到读上,另外交给用户来决定如何solve conflicts
- 系统SLA评测采用99.9th (笔者注: 07年之前难道都不用P99来衡量吗?),延迟敏感性系统
- 去中心化设计
分布式系统中的组件繁多,本文重点介绍:partitioning, replication, versioning, membership, failure handling and scaling
分区·
采用一致性哈希,
优点:一个节点的故障,只影响相邻节点。
缺点:对负载倾斜不敏感,热点问题不好解决,也没有考虑集群内节点异构的情况
Dynamo加入了VNODE的,可以将一个物理节点拆分为多个虚拟节点
优点:
- 一个节点故障,其上的负载可以将均匀分散到其它节点上
- 一个节点的加入,会从其他多个节点上分摊负载
- vnode个数的指定,可以根据节点的能力来决定,解决节点异构的问题
key打散到哪个节点上采用的是MD5-128bit算法
复制·
每个key会复制成N份,N参数为per instance级别由用户指定。put一个key时,首先根据hash算法确定首个节点,该节点成为这个key的协调节点,负责将这个k复制N-1份(自己还占了一份),复制方向为从协调节点开始顺时针复制N-1份,如下图,B为协调节点,B向C和D复制。
每个节点还保留了一个preference list, 该list中记录对于一个key range,哪些节点可以处理这个key range,一个key range对应的节点数是大于N的(因为要应对故障),另外,由于要vnode的存在,不能简单的向顺时针复制N-1的,因为这N-1可能包含了重复的物理节点,所以复制时还要跳过同一个物理节点的node。
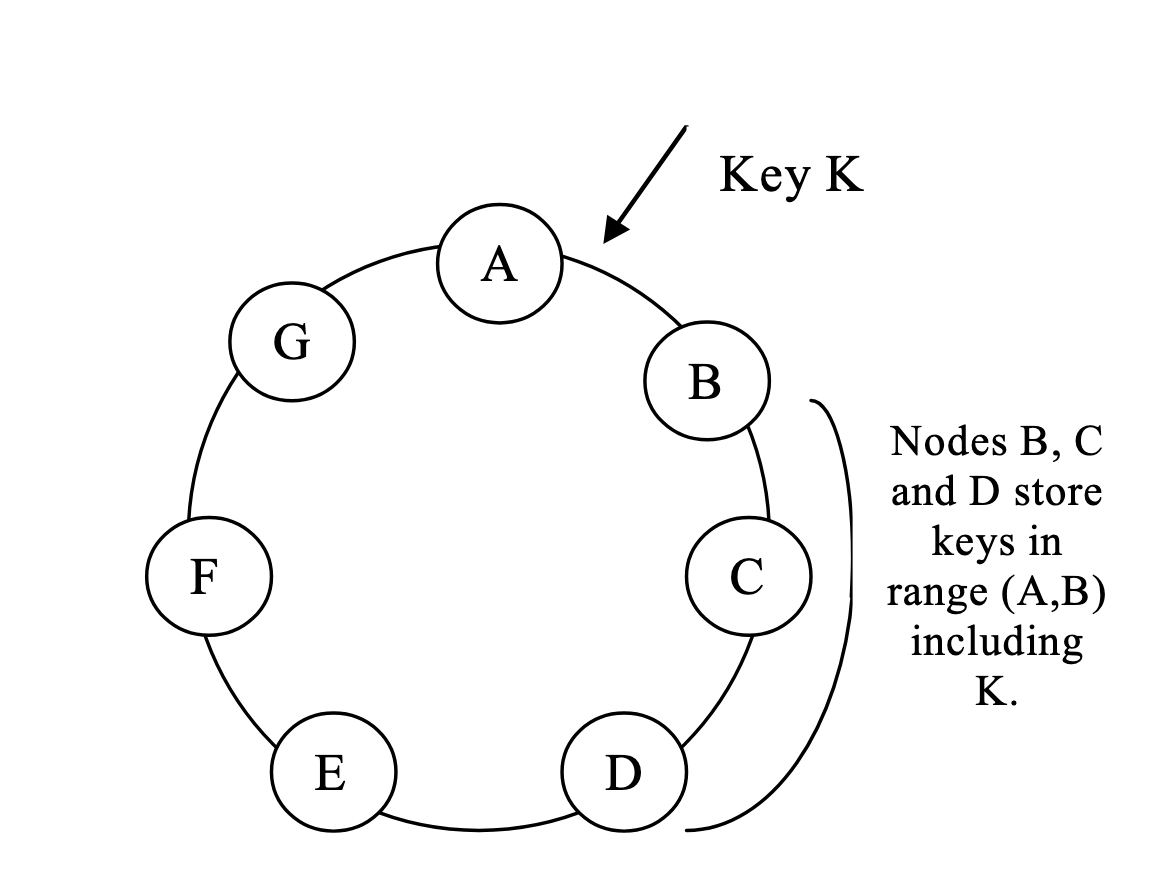
问题:写入多个份算write commit? 答: 系统采用quorum协议读写,R和W的个数由client(sdk)指定
冲突解决·
前文提到过,dynamo的设计目标是“始终可写”,当网络分区时,可能发生写冲突。Dynamo采用 向量时钟,并在读时由客户端来解决冲突。每个对象可能存在多个版本,每个版本都关联一个向量时钟。
文章举了一个向量时钟解决冲突的例子,如下:
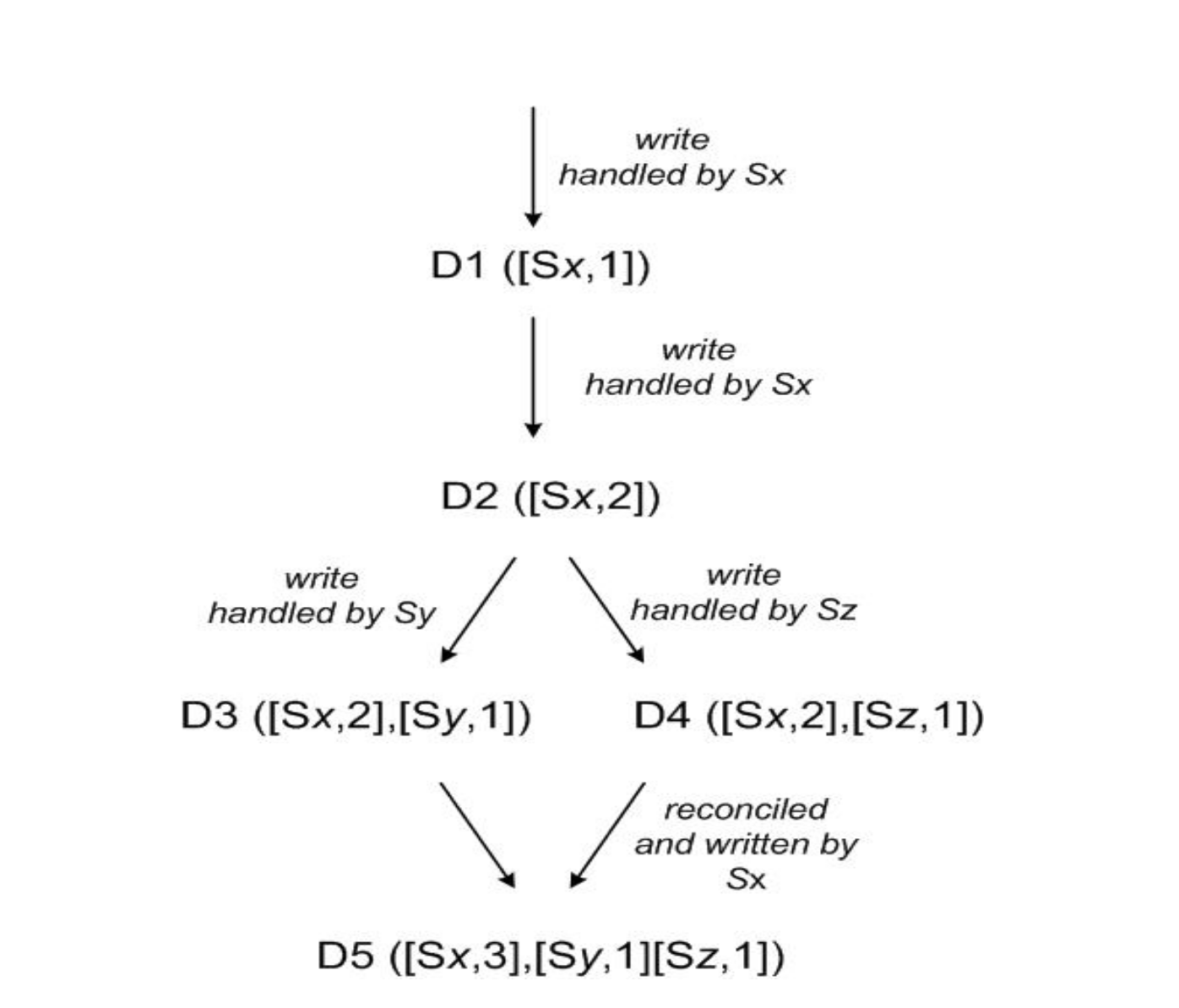
- 初始写入(D1):
- 客户端写入新对象,由节点Sx处理。
- Sx生成向量时钟
[(Sx, 1)],存储对象D1。 - 此时系统状态:D1([Sx,1])
- 同一存储节点再次更新(D2):
- 客户端更新D1,仍由Sx处理。
- Sx递增计数器,生成新时钟
[(Sx, 2)],D2覆盖D1。 - 系统状态:D2([Sx,2]),但部分副本可能仍存储D1(未同步)。
- 不同存储节点更新(D3):
- 客户端再次更新,由节点Sy处理(非初始节点)。
- Sy新增自己的计数器
(Sy, 1),向量时钟为[(Sx, 2), (Sy, 1)],生成D3。 - 此时D3与D2的时钟无法比较(D2仅含Sx,D3含Sx和Sy),形成冲突版本。
- 系统状态:D2([Sx,2])与D3([Sx,2],[Sy,1])并存。
- 另一存储节点更新(D4) (和上一步骤并发):
- 新客户端读取D2后更新,由节点Sz处理。
- Sz新增
(Sz, 1),向量时钟为[(Sx, 2), (Sz, 1)],生成D4。 - D4与D3的时钟仍无法比较(Sy vs. Sz),冲突版本增加。
- 系统状态:D3、D4并存,均为D2的分支。
- 版本合并(D5):
- 客户端读取D3和D4,获取两者的向量时钟合并为
[(Sx, 2), (Sy, 1), (Sz, 1)]。 (遇到冲突时,会将整条链路上的版本信息告诉客户端(传递context))为什么客户端会同时读到D3和D4?因为系统采用quorum协议读写。
- 客户端执行语义合并(如购物车合并),由Sx协调写入新对象D5。
- Sx递增自己的计数器至3,生成时钟
[(Sx, 3), (Sy, 1), (Sz, 1)],合并所有冲突版本。 - 系统状态:D5覆盖D3、D4,冲突解决。
向量时钟·
作用:向量时钟是用来描述因果关系和冲突关系的始终
本质上是一个 (节点,计数器)对的列表,每个元素代表某个节点对数据项的更新次数。其生成逻辑与写操作的节点处理直接相关,具体规则如下:
1. 初始写操作
- 当节点Sx首次处理写请求时,生成一个新的向量时钟,初始化为
[(S_x, 1)]。- 示例:图 3 中首次写入生成D1([Sx,1])。
2. 同一节点的后续更新
- 若同一节点Sx处理后续写请求,仅递增其计数器,不新增节点项。
- 示例:D1更新为D2时,Sx的计数器从 1 增至 2,时钟变为
[(Sx, 2)]。
- 示例:D1更新为D2时,Sx的计数器从 1 增至 2,时钟变为
3. 不同节点的并发更新
- 当另一个节点Sy处理写请求时,新增该节点的计数器项(初始为 1)。
- 示例:D2由Sy更新为D3时,时钟变为
[(Sx, 2), (Sy, 1)],表示Sx执行过 2 次更新,Sy执行过 1 次。
- 示例:D2由Sy更新为D3时,时钟变为
4. 版本合并时的时钟更新
- 当应用层合并冲突版本(如D3和D4),协调节点(如Sx)会继承所有冲突版本的计数器,并递增自身计数器。
- 示例:合并D3([Sx,2],[Sy,1])和D4([Sx,2],[Sz,1])时,新时钟为
[(Sx, 3), (Sy, 1), (Sz, 1)](Sx计数器 + 1,保留其他节点计数器)。
- 示例:合并D3([Sx,2],[Sy,1])和D4([Sx,2],[Sz,1])时,新时钟为
向量时钟的问题·
从最终合并的版本来看,向量时钟由于有三个节点参与,已经有三个元素,如果有更多的节点参与,向量时钟会膨胀。
优化方式:
- dynamo有perference list, 通常一个key都是由这个list的前N个节点之一单独处理(写请求),只有在节点故障,网络分区的时候才可能导致版本冲突
- 设置阈值(如 10 个节点),删除最旧的(节点,计数器)对,但带来的问题是可能无法推断因果关系
quorum读写·
略。
临时故障处理:Hinted Handoff(Sloppy Quorum)·
为了进一步提高dynamo的可用性,避免因为节点故障而停写的问题,dynamo还采用了Hinted Handoff机制保证高可用性。
柔性仲裁(Sloppy Quorum)·
- 基本思想:读写操作不再强制要求与偏好列表(Preference List)中的前 N 个节点通信,而是动态选择当前可用的 N 个健康节点,即使这些节点不在原本的偏好列表中。
- 示例:假设 $N=3$,偏好列表为 [A, B, C]。若节点 A 故障,写操作会将副本写入下一个可用节点 D,形成临时偏好列表 [D, B, C]。同时在D中附加一个Hint, 表示这些记录本身应该记录在A中,当A重新上线时,D 将提示副本主动移交给 A,然后删除本地的数据。
一些问题:
-
如果D又故障了,这些数据该如何记录? 是链式反应,比如复制到E,E觉得这些数据属于D?还是直接记录这些数据原本属于A?
原始目标有限,即E中记录的原始节点还是A
-
读写流程如何感知这些数据现在在D上?perference list中会记录D吗?
perference list原来就会记录到D,perference list不会动态调整(除非是管理调整?),perference list的节点个数是大于N的(前文也提到),在读写过程中,协调节点会跳过故障节点(通过gossip来检测哪些节点故障)
永久故障处理:反熵修复·
节点如果故障后再恢复,数据可能落后其他节点。或者节点永久故障,该节点原来的数据需要迁移到新选择节点。 这两者之间的共同之处都是要识别节点与其他节点之间的数据差异,之后才能同步差异的数据。
dynamo采用Merkle树来识别差异数据,然后通过数据。
dynamo的Merkle树生成方式:每个节点为其托管的每个键范围(一个虚拟节点覆盖的键集)维护一棵单独的默克尔树。这使得节点能够比较某个键范围内的键是否为最新 。此方案的缺点 在当一个节点加入或离开系统时,许多键范围会发生变化 ,因此需要重新计算树。
成员变更·
通过gossip协议传播成员变更关闭,维护最终一致性的成员视图。节点加入到集群中,首先获取token(vnode处在的位置),此时节点只有本地视图,之后通过gossip和其他节点交换集群信息(包括每个节点负责的key range, 后面方便路由请求)。
问题:才加入的节点,怎么知道向哪个节点发起交换信息的请求?答:集群的种子节点,这些节点信息是通过静态配置,或者通过配置服务发现的。
故障检测·
dynamo的故障检测是附带在两个节点之间的通信中的(如A向B发起副本同步信息,读写转发等),若A发现B不可达,则A认为B“故障”(可能会经过多轮通信才会认定B是故障的),然后通过gossip传播“B是不可达的”故障信息,最终集群内的所有节点都知道B是故障的,避免向B转发请求。
另外管理员显示的移除节点优先级更高。
一致性hash环如何分配·
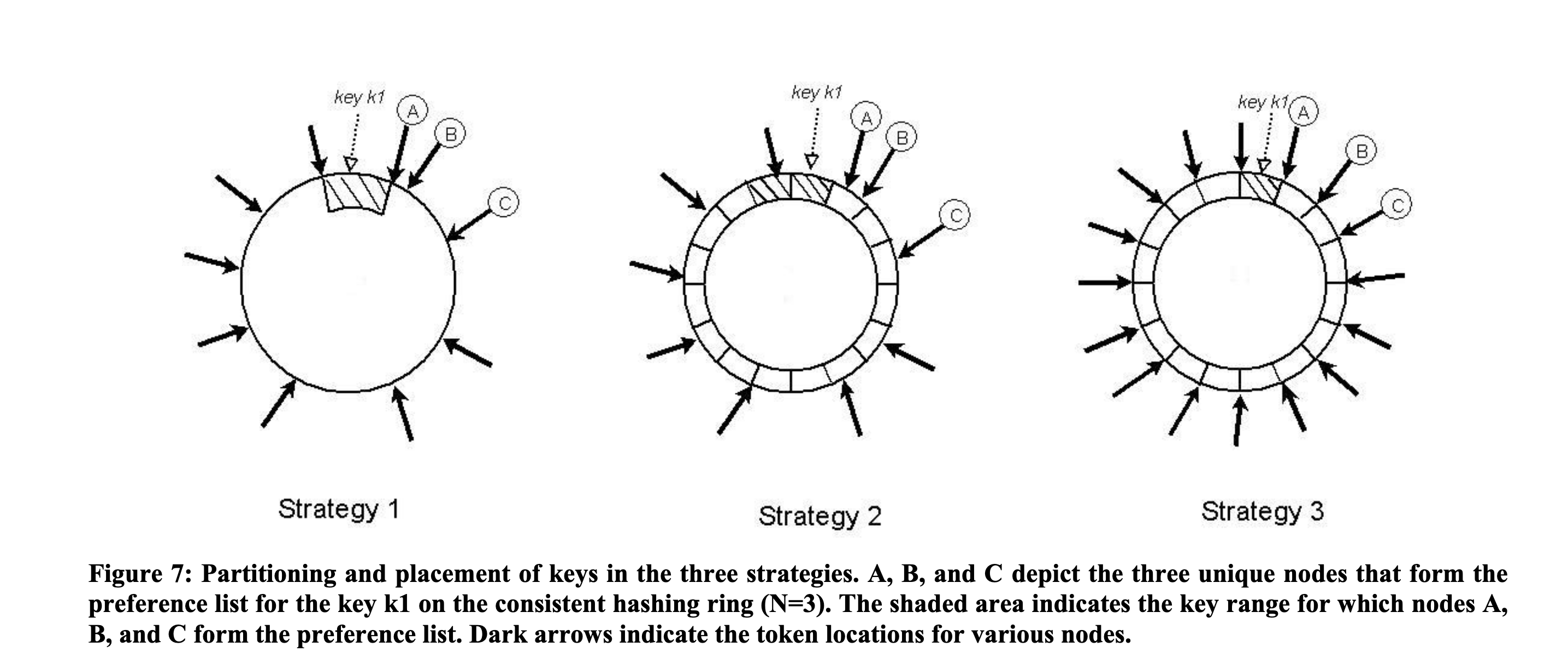
一、策略 1:随机令牌分区(初始策略)
核心逻辑
- 分区方式:
- 每个节点分配
T个随机令牌(Token),令牌在一致性哈希环上的位置随机分布。 - 哈希环被划分为多个随机大小的区间,每个区间由顺时针方向的下一个节点负责。
- 每个节点分配
- 负载均衡:
- 假设键的访问分布均匀,理论上随机令牌可实现负载均衡,但实际中存在热点键或节点异构性时,负载可能不均。
- 节点扩缩容:
- 新增节点时,需从相邻节点逐个迁移键范围,涉及大量磁盘扫描和随机 IO,引导时间长。
优缺点
- 优点:实现简单,无需预设分区规则。
- 缺点:
- 负载不均:随机令牌无法对抗访问偏斜(如少数键被高频访问)。
- 迁移低效:键范围随机分布,迁移时需逐键操作,无法批量处理。
二、策略 2:等大小分区 + 随机令牌(中间策略)
核心逻辑
- 分区方式:
- 将哈希空间划分为
Q个等大小的固定分区(如 Q=1000),每个分区对应一个连续的键范围。 - 节点仍分配
T个随机令牌,但分区的归属与令牌解耦:每个分区的归属节点由环上顺时针前N个节点决定,与令牌位置无关。
- 将哈希空间划分为
- 负载均衡:
- 分区大小一致,但节点的令牌随机分布,可能导致某些节点负责的分区数过多(如节点 A 持有 300 个分区,节点 B 仅持有 100 个)。
- 节点扩缩容:
- 新增节点时,分区归属重新计算,但无需迁移单个键,可按分区批量迁移(如迁移整个分区的文件)。
优缺点
- 优点:
- 分区固定,支持按分区迁移,效率高于策略 1。
- 缺点:
- 负载仍可能不均,因令牌随机分配导致节点负责的分区数不一致。
- 需维护分区与节点的映射关系,复杂度高于策略 1。
三、策略 3:等大小分区 + 均匀令牌分配(最终策略)
核心逻辑
- 分区方式:
- 哈希空间划分为
Q个等大小分区,Q远大于节点数S(如 Q=10000,S=30)。 - 每个节点分配
Q/S个令牌,令牌在环上均匀分布,确保每个节点负责相同数量的分区。
- 哈希空间划分为
- 负载均衡:
- 每个节点的分区数严格相等(如 30 节点时,每个节点负责 10000/30≈333 个分区),访问均匀时负载完全均衡。
- 节点扩缩容:
- 新增节点时,从现有节点均匀窃取分区(如每个现有节点迁移少量分区给新节点),迁移以分区为单位(如复制分区文件),速度极快。
优缺点
- 优点:
- 完美负载均衡:分区数均匀分配,对抗访问偏斜能力强。
- 高效迁移:分区级批量迁移,引导时间从 “天级” 降至 “分钟级”。
- 易于归档:分区文件可独立备份,无需跨节点检索(如策略 1 需逐个节点归档)。
- 缺点:
- 初始配置复杂:需计算均匀令牌分布,动态调整令牌时需全局协调。
四、策略对比与演进原因
| 维度 | 策略 1 | 策略 2 | 策略 3 |
|---|---|---|---|
| 分区规则 | 随机区间 | 固定等大小分区 | 固定等大小分区 |
| 令牌分配 | 随机 | 随机 | 均匀分布 |
| 负载均衡 | 依赖键分布均匀性 | 可能不均 | 严格均匀 |
| 迁移效率 | 逐键迁移,低效 | 分区级迁移,中等 | 分区级批量迁移,高效 |
| 元数据开销 | 高(需存储所有令牌位置) | 中(需存储分区映射) | 低(仅需存储分区归属) |
其他优化·
read repair·
在得到read的response后,client还会维护这个read state一段时间,如果其他节点返回了一个旧版本上来,可以使用这个read state来fix该节点上的数据,这个过程成为read repair
写操作协调节点选择·
通常协调节点由perference list中的第一个节点决定,但是fix到一个节点,容易造成负载不均,dynamo的做法是允许偏好列表中前N个节点中的任意一个来协调写操作。具体而言 ,由于每次写操作通常紧随读操作之后,因此选择对前一次读操作回复最快的节点作为写操作的协调器。
协调方式:client-driven vs server-driven·
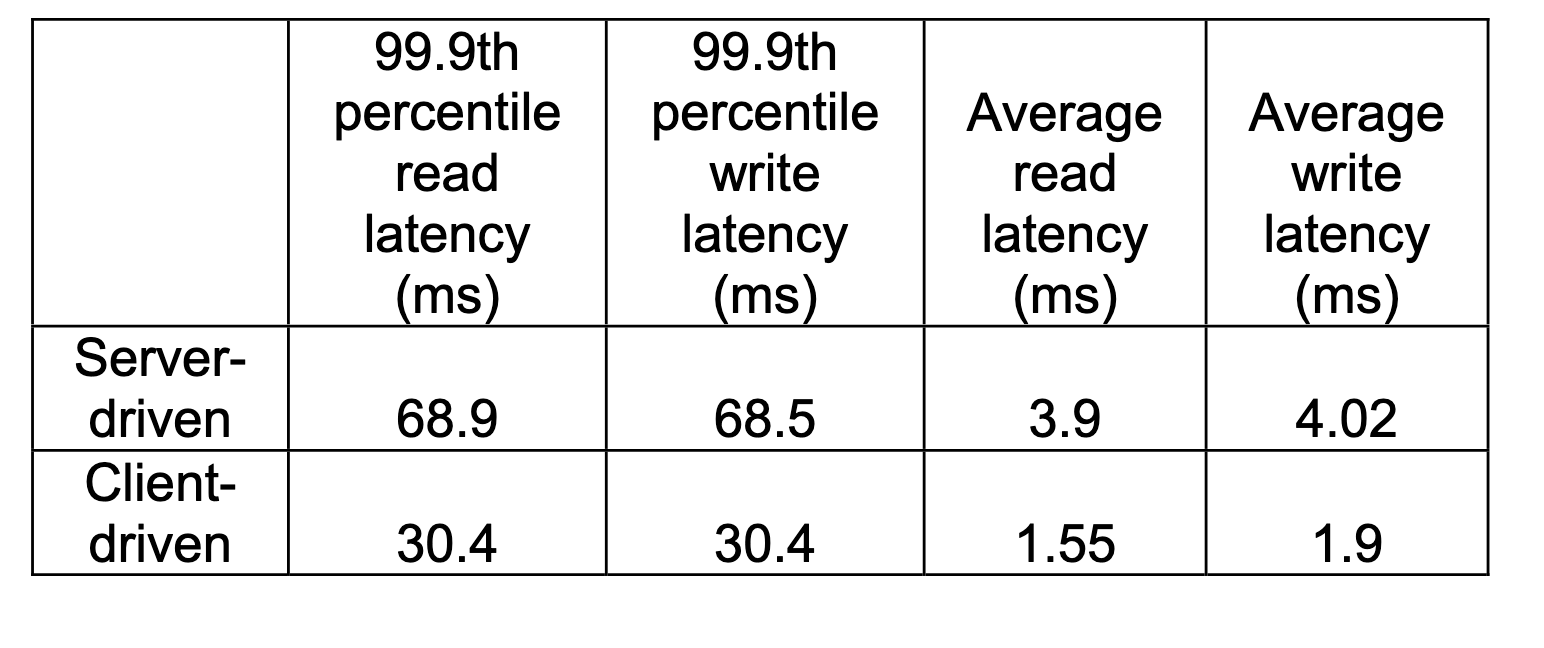
server-driven: 负载均衡器选择协调节点,或者任意节点+perference list来选择
client-driven: client定期和server同步成员视图,后面由client缓存的成员视图来发起请求,client中的成员视图可能会过期,发现过期时立即更新,通常10s会同步1次。
上表对比了两种方式,client-driven明显更加。

