0. 前言·
几年前分析过持久化KV数据库–LevelDB, 从今天开始,逐渐分析内存KV数据库–Redis。实际上也是《Redis设计与实现》的读书笔记。
本篇为redis内常用基本数据结构介绍。
1. SDS(Simple dynamic string)·
简单结构,不分析源码
SDS是redis内部的字符串实现,除了保存字字符串值外,还被用作缓冲区(buffer)
SDS 定义如下:
1 | struct sdshdr { |
SDS字符串结尾和C-style string一样,有’\0’, 但是len不算这个\0。
为什么Redis要单独实现一套字符串,不沿用C-style string?
- O(1)级别的字符长度获取:C-style string 无法直接获取字符串长度,需要通过strlen等O(n)级别的函数扫描。
- 安全:防止缓冲区溢出,比如在C函数 strcat(dest, src, len) 中,dest的分配长度是未知的,如果src过长,dest 未分配足够内存,会造成内存访问越界,从而带来问题。在SDS-family API中,会检测这类溢出,如果内存不够,会自动扩容。
- 减少内存分配:为了避免频繁内存分配,redis做了如下优化:
- 空间预分配:在对SDS做扩展时,按照以下规则扩展:
- 如果SDS预计扩容后的大小小于1M,则除了分配预计扩容后的大小外,还要再多分配一倍的空闲空间,此时len和free大小一致。比如预计扩容后len=13,则还要再分配free=13,总大小=13+13+1,1给\0用。
- 如果SDS预计扩容后的大小大于1M, 则free=1M, 比如扩容后len=30M,则分配大小为30M + 1M + 1byte
这是比c++ std::string 分配策略好的地方,c++ std::string 对于小于15字节的使用stack内存,对于大于16字节使用heap内存,但是要扩容采用两倍扩容方式。对于大内存来说,这是浪费的。不过实际上c++会通过预留内存来解决。
- 惰性空间释放:对SDS做做缩容时,并不立即释放这片内存,而是使用
free属性将这些字节数据量保存起来。如果是大片内存trim,就有些浪费了。 但是sds也提供真正缩减内存的函数。
- 空间预分配:在对SDS做扩展时,按照以下规则扩展:
- 二进制安全:c-style string只能处理文本数据,因为\0被认为字符串的结尾。 sds被认为是byte array,因为len才表示真实的结尾。
- 重用部分c-style string API
下图总结了c-style string和SDS的区别:

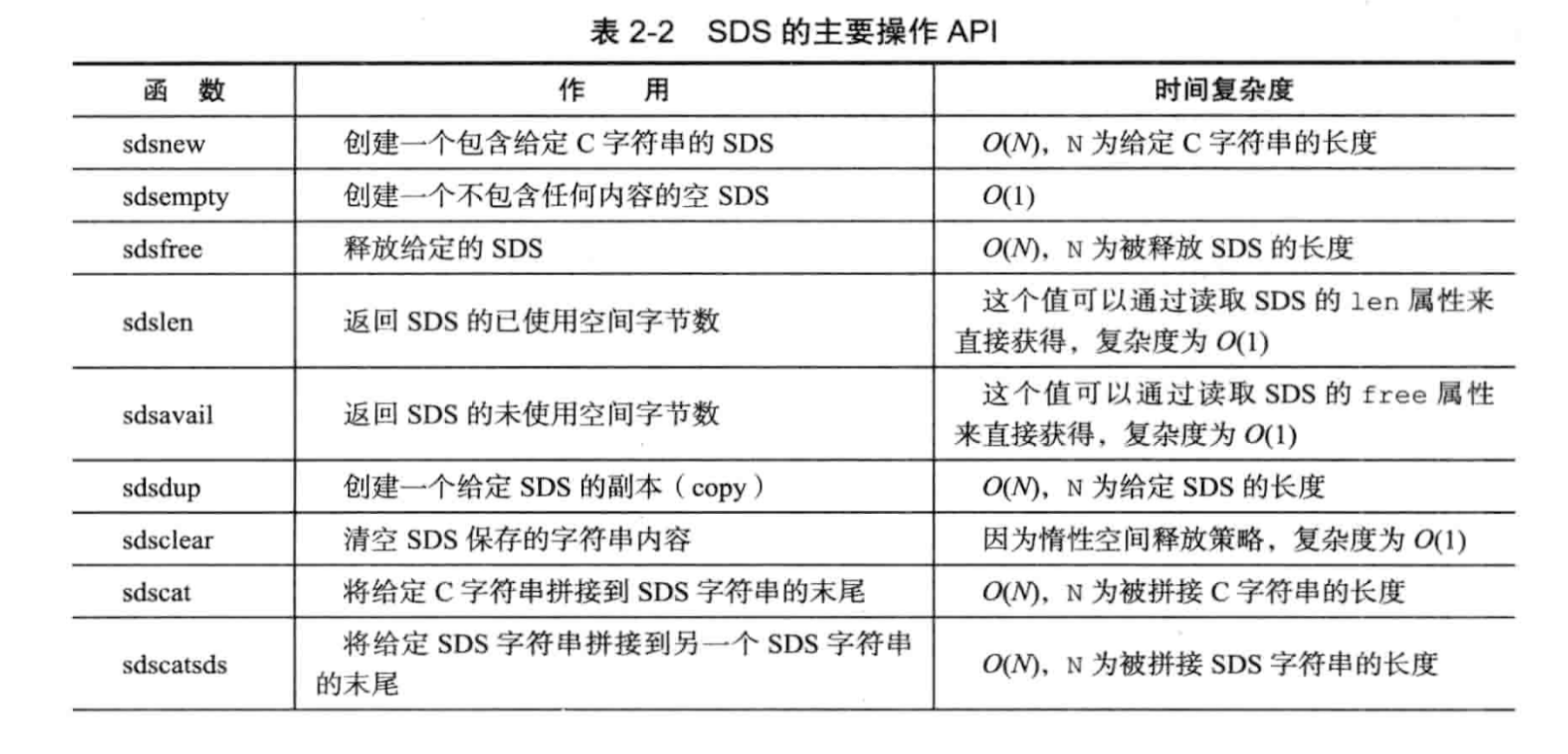
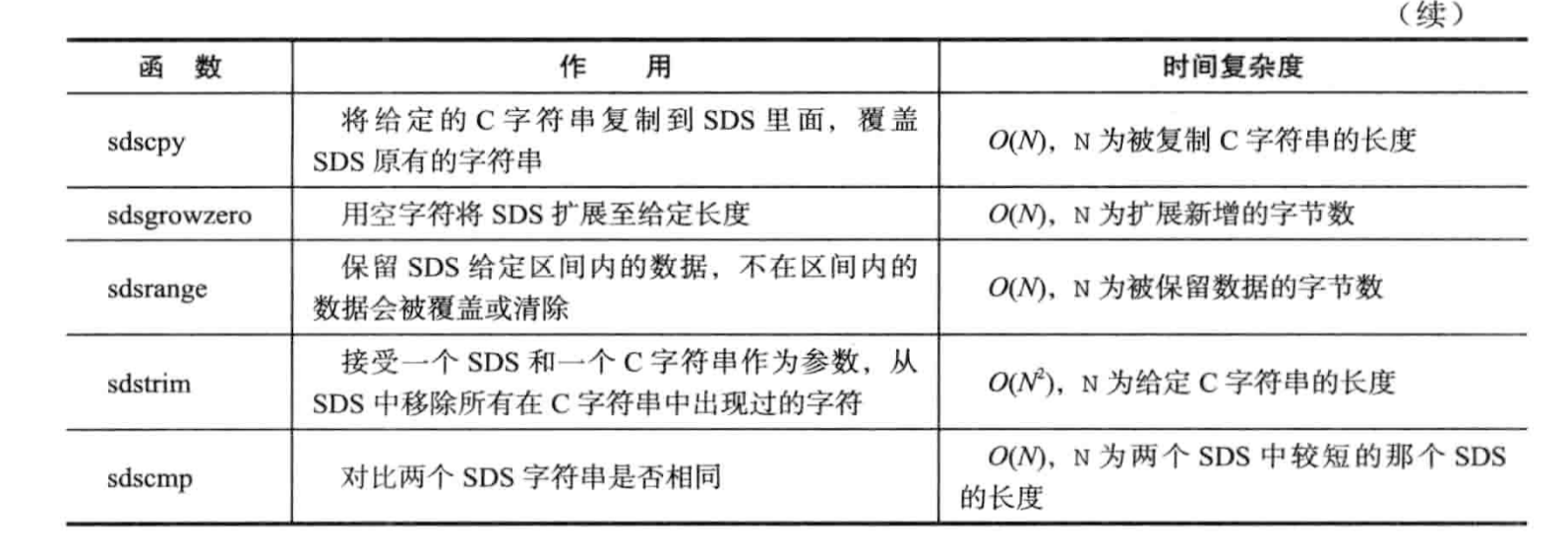
SDS API:
2. 链表·
简单结构,不分析源码
链表是redis内部的重要结构,可用于list key,pub/sub, 慢查询,监视器等。redis采用双向链表, 链表节点:
1 | /* |
还是linux kernel的链表牛逼。
使用list结构体表示一个链表, 定义如下:
1 | /* |
c没有oop的概念,只能使用函数指针来模拟oop。
注意: redis的链表的表头prev和表尾tail指针是NULL,所以redis的链表不是环形链表。
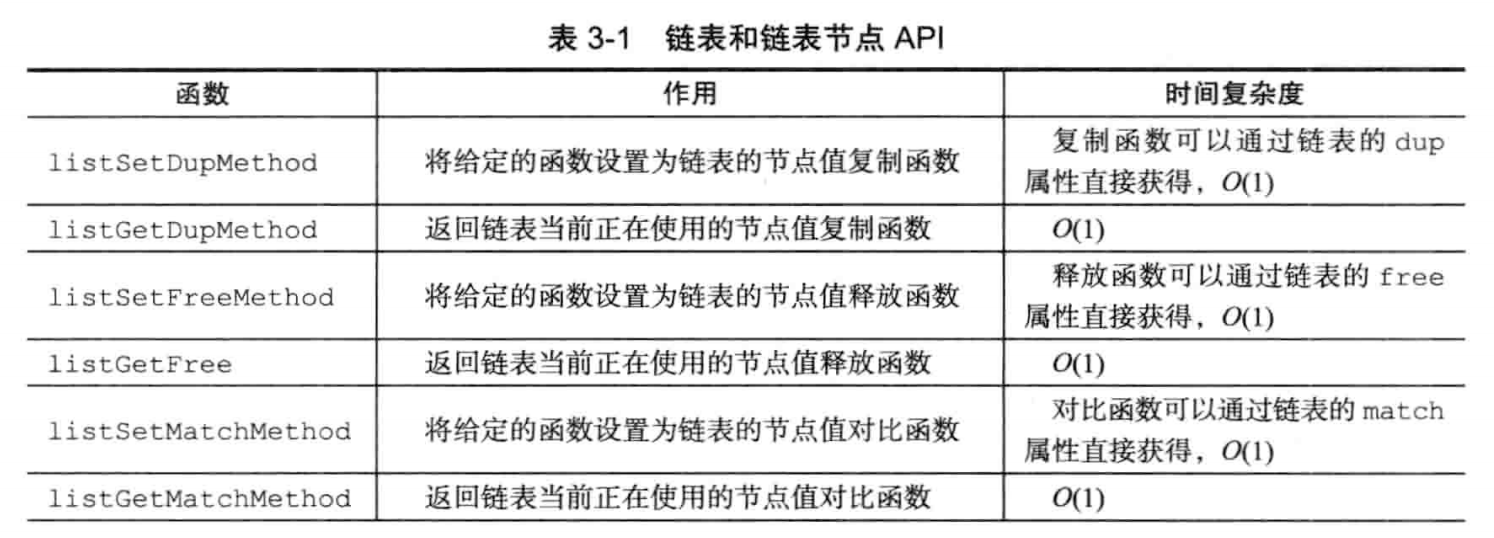
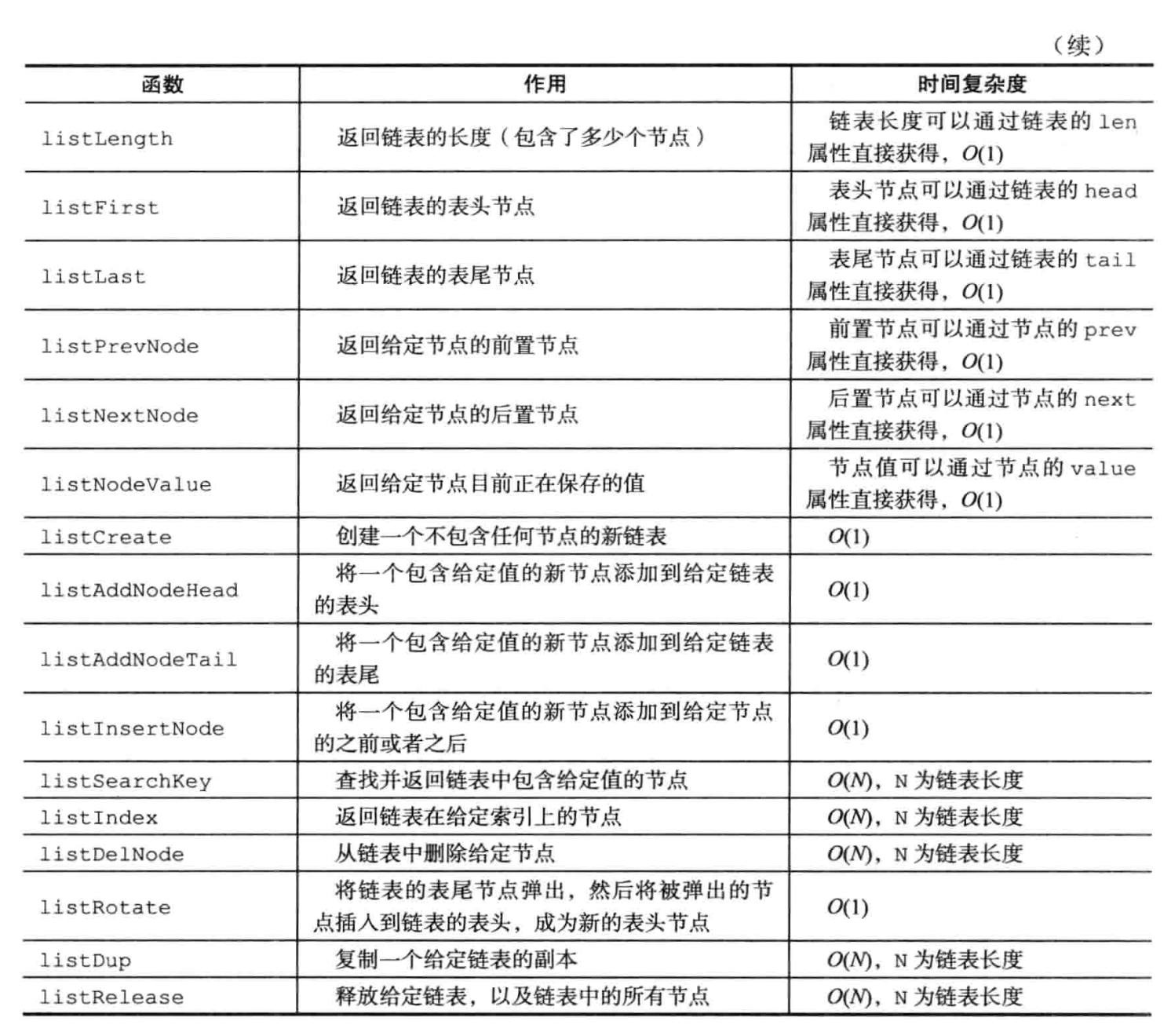
链表API:
3. 字典·
1. 字典实现·
字典即dict, 是redis内部的重要数据结构。
1. hash table·
1 | typedef struct dictht { |
This is our hash table structure. Every dictionary has two of this as we implement incremental rehashing, for the old to the new table. incremental rehash, 比较好奇。
其余结构和常规dict类型相似。
exmaple:

2. hash table node·
哈希表节点用dict entry来表示:
1 | /* |
看起来是链式hash,用list来解决哈希冲突
所以hash table的结构如下:
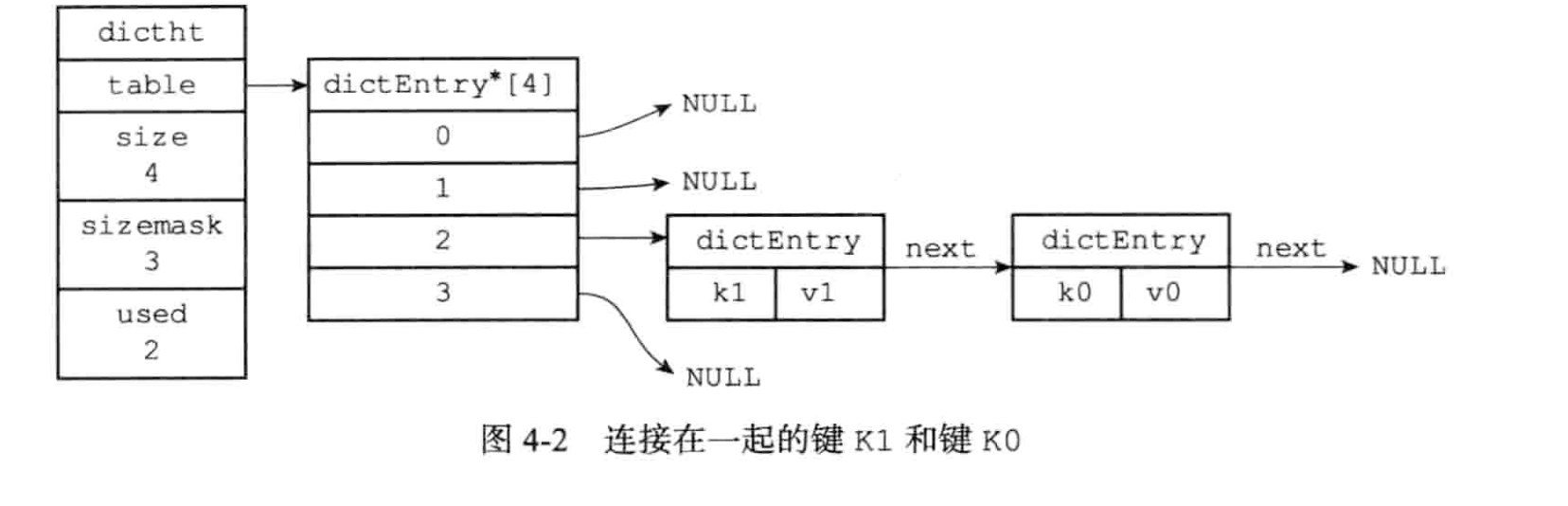
3. dict结构(这个是最外层的dict表示)·
代码如下:
1 | /* |
先说重要的, dictht ht 是一个数组,个数为2,用于做rehash,通常情况下,只会使用ht[0],当需要做rehash时,才会使用ht[1]. 而rehashidx 表示做rehash的进度, 当值为-1时,表示没有做rehash
再来看redis 的 dict 多态, 使用dictType保存了一系列用于操作特定类型键值对的函数,结构如下:
1 | /* |
而private属性则保存了需要传递给这些特定函数的可选参数。
2. 哈希算法·
添加、查找一个key在dict中的位置时,需要先计算出hash值,根据hash值再计算slot:
1 | hash = dict->type->hashFunction(key) |
redis采用MurmurHash2算法来计算hash
关于 MurmurHash2 参考: https://en.wikipedia.org/wiki/MurmurHash 参考15445课程的hash函数性能对比:
看起来MurmurHash3(不知道2相比3的性能)比起XXHash3还是弱不少的
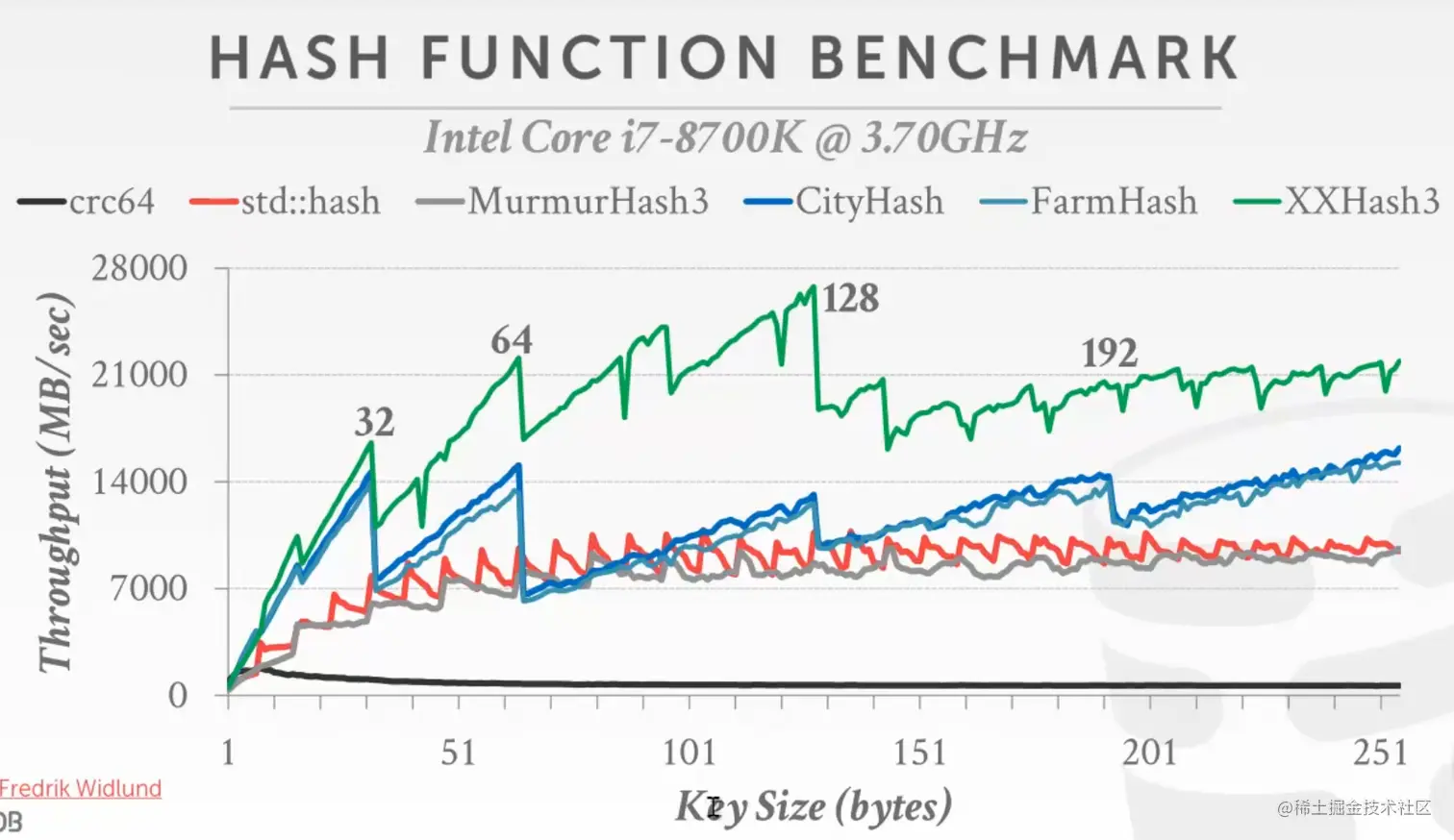 看起来MurmurHash3(不知道2相比3的性能)比起XXHash3还是弱不少的
看起来MurmurHash3(不知道2相比3的性能)比起XXHash3还是弱不少的3. hash冲突·
采用链式hash, 且头插法
4. rehash·
redis的hash table rehash规则如下:
- 为ht[1]分配空间,具体分配策略如下:
- 如果hash tbl需要expand, 则扩容大小为第一个大于等于 ht[0].used * 2 的 $2^n$。 如当前used为5,则扩容后为8.
- 如果hash tbl需要shrink, 则缩容大小为第一个大于等于ht[0].used 的 $2^n$ . 如当前used=3, 则缩容后ht[0].size为4
- 将当前ht[0]的所有kv rehash到ht[1]
- 释放ht[0],将ht[1]设置为ht[0],同时为ht[1]创建一个空白hash table
尚不明确redis执行rehash是否会阻塞io,考虑到redis是单线程模型,可能不需要加锁,但是hash table越大,rehash时间越长,前台io阻塞越长。 #[5. 渐进式rehash] 回答了本问题
个人感觉,逐渐异步rehash,超过一定阈值再block io rehash更好
expand和shrink的条件, hash table内部有一个核心参数 $$ load factor = used / size $$
对于redis来说,满足以下条件之一, 则rehash:
- 如果服务器目前没有执行BGSAVE,或者BGREWRITEAOF命令,并且load factor >=1 --> expand
- 服务器目前正在执行BGSAVE或者BGREWRITEAOF命令,且load factor >=5 --> expand
- loading factor <= 0.1 -> shrink
为什么BGSAVE或者BGREWRITEAOF时,loading factor更大才能rehash?其实挺直观的, BGSAVE或者BGREWRITEAOF都需要fork子进程来做,linux采用COW来避免多于内存拷贝,所以在子进程还未完成工作前,如果父进程频繁分配内存,都会频繁触发COW分配内存。 应该尽可能避免内存分配
5. 渐进式rehash·
在第4小结中,笔者怀疑过大量key做rehash时,前台io可能block的场景,redis也的确考虑了这种场景,和笔者想法不同,笔者倾向采用异步rehash的方式(可能这不符合redis单线程的架构),redis采用分而治之的方式。逐渐将key rehash到ht[1]中:
- 将字典中维护一个
rehashidx值, 开始rehash时,将它标成0,表示要把slot0的keys rehash到ht[1]中 - rehash期间,每次对dict做添加、删除、查找更新操作时,除了完成本来需要做的操作外,还会顺带将ht[0]哈希表在rehashidx索引上的所有键值对rehash到ht[1],rehash一个slot完成后,rehashidx++
- rehash期间,所有的新增key,都直接插入到ht[1]中
- 随着dict不断操作,最终某个时间点,ht[0]的所有kv都rehash到ht[1], 将rehashidx标成-1, 表示操作完成
- 切换ht[1]到ht[0], 重新为ht[1]分配空白hash表
渐进式rehash解决了大量kv的block问题,但是放慢了rehash的速度,在rehash期间,进程的内存开销变大。 不知道redis是否还要其他策略,例如定时器的方式,强制rehash一个slot
6. dict API·

4. Skip List·
Skip list支持平均O(logN), 最坏O(N)复杂度的节点查找,还可以通过顺序性操作来批量处理节点。
B-tree 系列也可以, 不过感觉内存index用Skip list的较多,LevelDB也是。 B-tree实现更复杂,并发控制实现很难。
Redis使用skiplist 作为有序集合键的底层实现之一。** 如果一个有序集合包含的元素数量较多,或者元素的长度较长时,redis使用skiplist来实现有序集合键。**
Redis中使用skiplist的地方很有限,一个是有序集合键,一个是集群节点用作内部数据结构。
1. skiplist 实现·
skiplist 由zskiplistNode和zskiplist两个结构定义。一个典型的redis skiplist示意图如下:

- header:指向跳跃表的表头节点。
- tail:指向跳跃表的表尾节点。
- leve1:记录目前跳跃表内,层数最大的那个节点的层数((表头节点的层数不计算在内)。 length:记录跳跃表的长度,也即是,跳跃表目前包含节点的数量(表头节点不计算在内)。位于zskiplist结构右方的是四个zskiplistNode结构,该结构包含以下属性:
- 层(level):节点中用11、L2、L3等字样标记节点的各个层,L1代表第一层,L2代表第二层,以此类推。每个层都带有两个属性:前进指针和跨度。前进指针用于访问位于表尾方向的其他节点,而跨度则记录了前进指针所指向节点和当前节点的距离(笔者注:为啥需要这个?更新起来挺麻烦的)。在上面的图片中,连线上带有数字的箭头就代表前进指针,而那个数字就是跨度。当程序从表头向表尾进行遍历时,访问会沿着层的前进指针进行。
- 后退(backward)指针:节点中用B字样标记节点的后退指针,它指向位于当前节点的前一个节点。后退指针在程序从表尾向表头遍历时使用。
- 分值: 从小到大排序
- 成员对象(obj): 保存的value
1. zskiplistNode·
定义如下:
1 | /* ZSETs use a specialized version of Skiplists */ |
各属性解释:
- level: level数组,表示skiplist的层数,每次创建一个新跳跃表节点时,随机生成一个介于1和32之间的值作为level数组的大小,这个大小就是高度
- forward pointer: 前向指针
- span: 两个节点之间的span越大,说明它们之间隔得更远, span是用来计算rank的。(笔者注:目前仍不明确span、rank的是用来做什么的)
- backward: backward指针,每个node只有一个backward指针,用于后向遍历
- score and obj: obj是一个SDS对象,同一个skiplist中,每个node保存的obj是唯一的,但是不同的node可以有相同的score,相同score之间的对象按照key的字典序排序。
2. zskiplist·
1 | /* |
属性见注释。
2. skiplist API·
skiplist介绍得比较简单,详细算法原理和实现可参考:https://www.geeksforgeeks.org/skip-list/
5. 整数集合(intset)·
intset是集合键的底层实现之一,当一个集合只包含整数,并且这个集合的元素数量不多时,redis使用intset作为set的实现
比如:
1 | SADD numbers 1 3 5 8 0 |
1. 实现·
1 | typedef struct intset { |
contents是底层存储数据的数组。conotents数组按值从小到大有序排列(更快去重判定),不包含任何重复项。
笔者注:用数组实现有序array,插入删除开销是否过大?
比较有意思的是 intset统一用int8_t保存数据,但实际上intset可以保存多种长度类型的数据。 如int16_t, int32_t int64_t, 宏定义:
1 |
另一个值得注意的是, contents内的所有数据的宽度都是一样的,即使某些元素宽度大,某些元素宽度小。如:
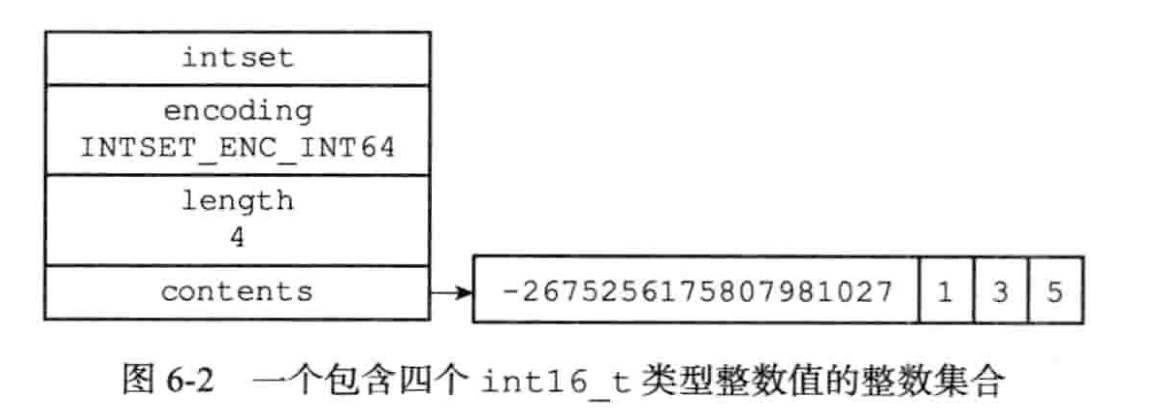
笔者注:初始化的宽度是多少? 插入新宽度时,如何处理?
实现比较有趣,可以动态调整底层存储内存,较大程度上节省内存。
2. 升级·
当插入一个新元素到intset中,且新元素的宽度比现有元素的类型都要长时,需要对intset进行升级(笔者注:开销是否很大)。步骤如下:
- 根据插入元素的宽度,分配空间
- 将底层数组元素转换到新分配空间,保持有序性
- 将新元素添加到底层数组中
3. 降级·
intset不支持降级,一旦升级后就固定了。
笔者猜想,不好降级的原因是不知道当前intset中剩下的元素中最大宽度是多少,不可能每次delete一个元素后,都走O(n)去扫描。而单独维护一个宽度map开销又过大。
4. API·
6. ziplist(压缩列表)·
ziplist是列表键和hash键的底层实现之一. 当一个list key中只包含少量的item,且每个item要么是小整数值,要么是比较短的字符串,那么redis就会使用ziplist来实现。另外,哈希键包含少量item,且每个item要么是小整数,要么字符串较短
小整数值,有多小? 哪种位宽?还是有什么整数池化?
1. 压缩列表构成·
ziplist 主要为了节约内存而设计。 由一块连续内存组成的顺序结构。 如下:

- zlbytes: 4B, 记录整个ziplist占用的内存字节数。
- zltail: 4B, 记录ziplist尾节点距离ziplist的其实地址有多少字节。
- zllen: 2B, 当属性小于UIINT16_MAX时,代码节点数量。等于UINT16_MAX时,节点的真实数量需要遍历整个压缩列表才能算出。
所以当节点数量较多的时候,需要转换成其他数据结构?
- entryX: 不定。具体节点
- zlend: 一个magic number(0XFF)
eg:

2. 压缩列表节点的构成·
每个entry可以保存一个字节数组或者一个整数值。字节数组可以是:
- 长度小于等于2^6 - 1字节
- 长度小于等于2&14 -1字节
- 长度小于等于2^32 - 1字节
整数可以是:
- 4 bit长,0~12之间的无符号整数
- 1字节长的有符号整数
- 3字节长的有符号整数
- int16_t
- int32_t
- int64_t
每个entry都由previous_entry_length, encoding, content三个部分组成:

previous_entry_length·
以字节为单位,记录ziplist中前一个节点的长度。 previous_entry_length的长度可以是1字节或者5字节:
- 如果前一个节点的长度小于254字节,那么previous_entry_length的长度为1字节。
- 如果前一个字节的长度大于等于254字节,那么previous_entry_length长度为5字节:其中第一个字节设置为0xFE(254),而之后的四个字节则用来保存前一节点的长度。
笔者注:这或许是需要变数据结构的原因,用4字节来保存长度过于浪费。
eg:

使用previous_entry_length,可以实现ziplist从tail到head的遍历。
encoding·
encoding 保存了数据的类型和content的长度
- 1,2或5字节长。值的最高位为00,01或者10的,表示content是字节数组。 余下的bits表示conotent的长度。
- 1字节长,值最高位为11的,是整数编码。 余下的bits表示conotent的长度。
eg:
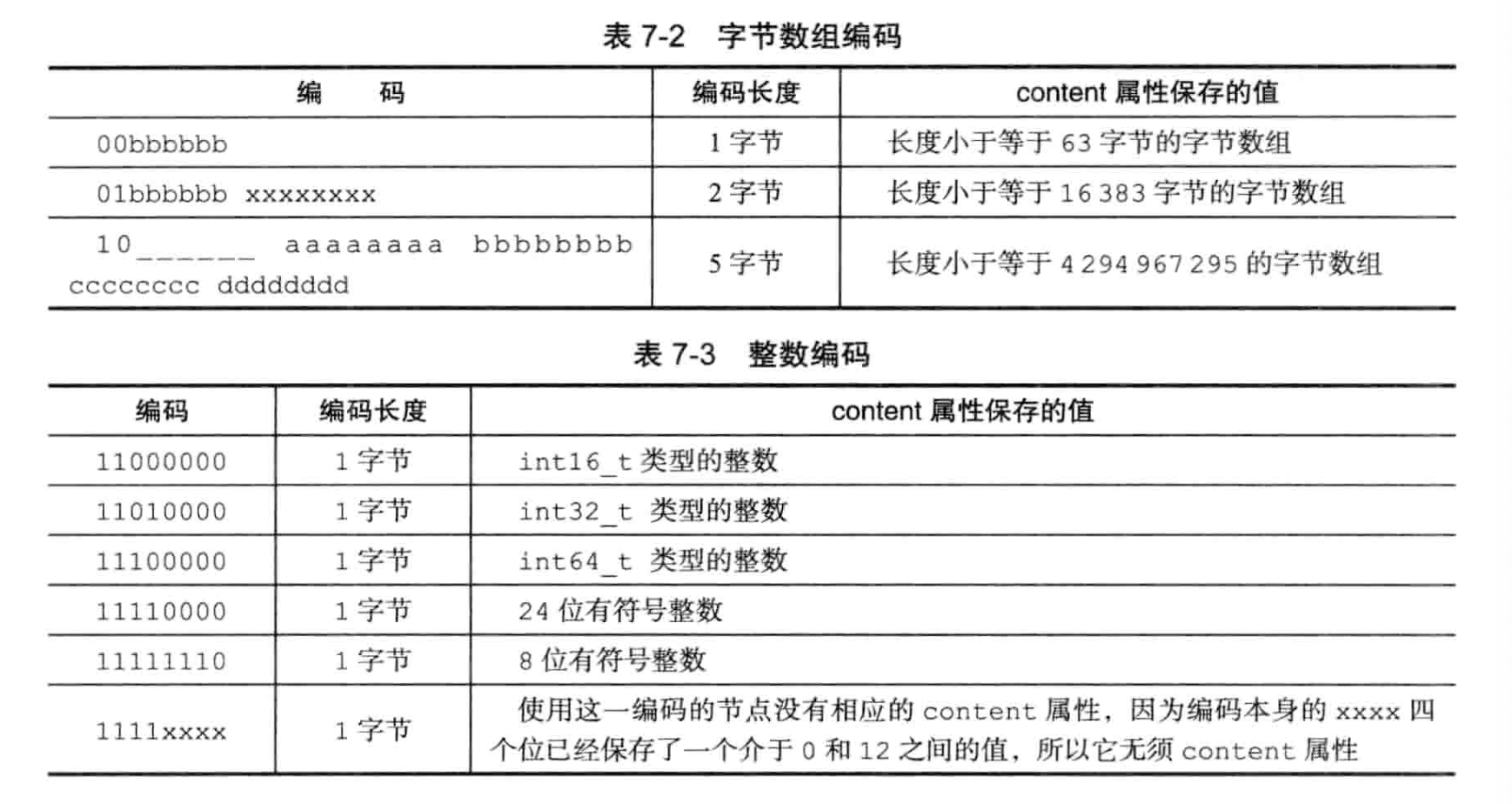
整数编码似乎书上没说清楚? 感觉顶2bit为11表示整数编码,后2bit又表示content的位宽,00为int16_t,01为int32_t,10为int64_t,11为其他。
content·
content为具体value
3. cascade update·
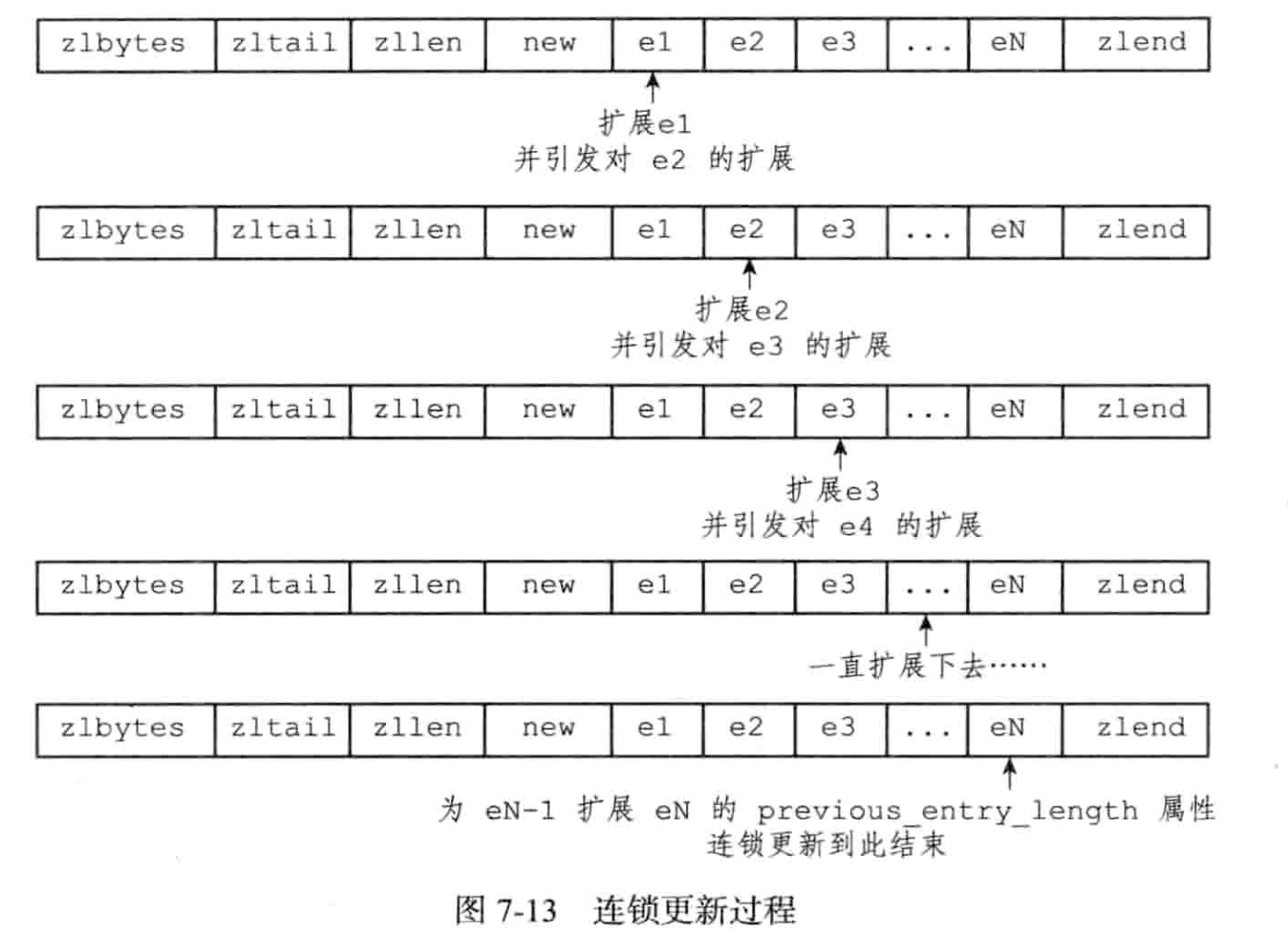
由于previous_entry_length的存在,每个节点需要记录前一个节点的长度,用于反向遍历。那么可能存在某个节点更新了长度,导致后一个节点的previous_entry_length更新,从1个字节变成5个字节,又进而影响后一个节点,一直递归下去。书中举了两个例子:
-
插入引起cascade update, 由于e1到eN都是253长度的节点,new是新插入的节点,长度超过253,再加上new的previous_entry_length,长度超过254,导致e1的previous_entry_length需要从1字节扩张到5字节,那么e1的总长度也超过254字节,引起e2…
![]()
-
删除引起
其中big是>=254B, small是小于254B的节点。此时删除small,e1需要更新其previous_entry_length, 之后的情况就和case1一样了。

每次更新,都需要重新分配内存和计算, 这种开销是巨大的。复杂度O(N^2), 实际的cost会更大。设计到内存分配,重计算。
笔者注:书中没有给出解决方法,而是“赖皮”的说,这种case的出现概率低。
4. ziplist API·
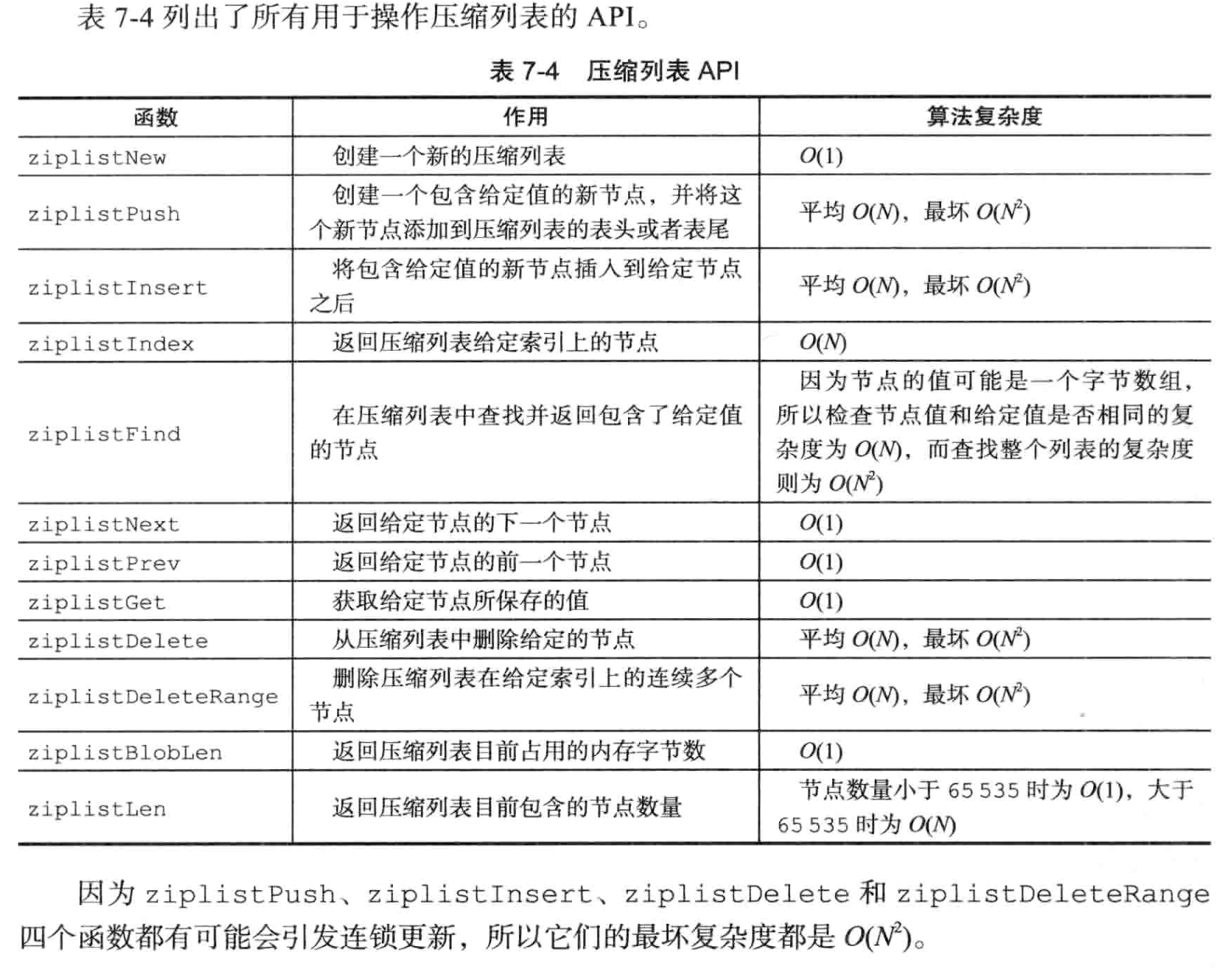
TODO(zhangxingrui): 看下实现, 贴下源码路径。
至此,redis内常用数据结构已经介绍完毕。
总结·
本篇介绍了redis内部的底层数据结构,包括 SDS、链表、dict、skiplist。。。,值得学习的有:
- SDS,避免直接使用c-style string, 更安全, get length操作变O(1)
- 内存分配策略优化,小于1M是怎么分配(2倍扩容+预留),大于1M怎么扩容(满足要求+1M预留)
- dict的渐进式rehash,避免海量key的rehash block io
- intset 的升级方案和ziplist的压缩方式 尽可能节省内存。
- ziplist的cascade update
- c 语言的多态实现, 函数指针是精髓

