2024-6-30 update: 实际上本文是linux process的内存布局,而不是c语言内存布局。
1. 前言·
老早就接触到了C语言中的内存布局,如代码段,数据段等等名词,也曾因为不了解C语言的内存分布机制而吃过亏。所以这里总结以下。现在让我们以两个问题来引入,先看下面这两段代码:
1 | // code 1 |
1 | // code 2 |
上面两段代码,除了一个是字符指针,一个是字符数组以外,没什么不同。但是,你觉得上面两份代码的执行结果是什么呢?(假定的输入都是"world")。
i> code 1 将会报段错误,code 2才能正确执行。
好,这是第一个问题。再来看第二个问题。
1 | int main(void) |
那这个程序,你觉得输出是怎样的呢?
先给答案:
1 | 1 |
i> 也就是说str1和str2指向的地址是完全相同的。而str3的首地址和str4的首地址是不同的。
恩,现在带着这个问题,我们来谈谈C语言中的内存分布情况。
2. C语言内存分布·
典型的C语言程序由以下几个sections组成:
- 文本段
- 数据段
- 已初始化数据段
- 未初始化数据段(这样命名略微有点出入,稍后会对它进行解释)
- 堆
- 栈
具体分布可见下图:
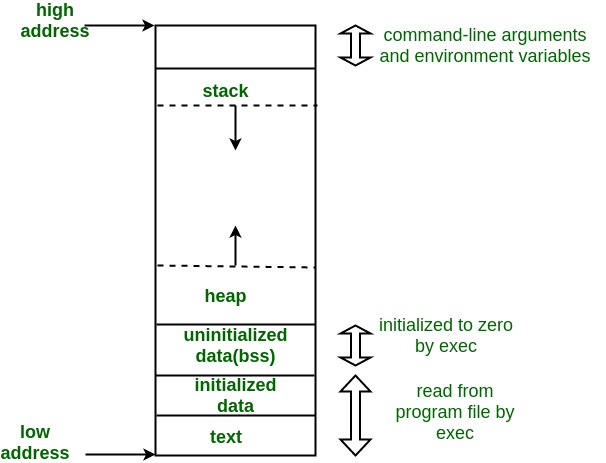
2.1 文本段·
文本段,又称为代码段。代码段中存放可执行的指令,在内存中,为了保证不会因为堆栈溢出被覆盖,将其放在了堆栈段下面(从上图可以看出)。通常来讲代码段是共享的,这样多次反复执行的指令只需要在内存中驻留一个副本即可,比如C编译器,文本编辑器等。代码段一般是只读的,程序执行时不能随意更改指令,也是为了进行隔离保护。
2.2 数据段·
数据段是用来存储“全局变量和静态变量”的。根据是否被初始化为0(手动或由编译器自动)又分为了“初始化数据段”和“未初始化数据段”。
2.2.1 未初始化数据段·
未初始化数据段,又名bss(block started by symbol),指的是在程序中未被手工初始化或者被初始化为0的全局变量或静态变量。如:
1 | int a; |
上面这些变量均会被存储在“未初始化数据段”(观察到有些变量我们手工赋值为了0,所以我说这样的命名并不太准确)。对于未手工初始化的变量,编译器也会自动帮助我们初始化。
2.2.2 初始化数据段·
初始化数据段值的是在程序中被手工初始化为非0的全局变量或静态变量。如:
1 | int a = 10; |
但初始化数据段又可分为可读写数据段和只读数据段。
举个栗子,对于字符串常量来说,它们存储在只读数据段中,且在整个内存中只保留一份副本。如
1 | char *str1 = "hello"; |
这的"hello"就是存在只读数据段中。
而对于全局字符串来说,他们是存储在可读写数据段中,注意,我说的是全局字符串。
1 | char str2[] = "hello"; // str2[] 定义为全局变量 |
3. 堆区·
堆区是动态内存分配的地方,在这里的内存需要程序员自己分配与释放。
一般来说,堆区紧跟BSS区末端,然后从低地址往高地址增长。堆中内存分配管理由malloc,remalloc和free标准库函数来完成。堆可以被进程的所有共享库以及动态加载模块共享。
4. 栈区·
栈区中存放着我们常见的变量,这些变量由操作系统自动管理释放。
栈区一般与堆区相邻,但它是由上往下生长(即从高地址向低地址生长,和堆区相反),当栈区指针和堆区指针相遇时,说明堆栈已耗尽(现代大地址空间和虚拟内存技术可以将栈和堆放在任何地方,但是二者增长方向也是相反的)。栈指针寄存器记录栈顶地址,每次有值push进栈就会对栈指针进行修改。一个函数push进栈的一组值被称做堆栈帧,堆栈帧保存有该函数的最小的返回地址。
写个简单的程序,来大体验证各个区在内存中的位置:
当然了,文本区就没办法验证了。
1 | int main(void) |
这段代码中,我分别定义了数据段,栈区和堆区变量,之后分别打印了它们的地址。结果如下:
1 | init_a 0x601050 |
可以看到init_a和uninit_a都在内存的相对较低的位置,stack_a在相对很高的位置。heap_a所指向的位置也就是堆区的位置依旧不高,而heap_a这个指针本身是属于栈区,所以它的地址较高,且紧跟stack_a变量。stack_a和heap_a指针本身的地址刚好差了4个字节,这也是一个int所占的字节数。
3. 使用size指令来验证·
我们可以使用size指令来看未初始化数据段和初始化数据段中所占的字节数。
先看这样一段代码:
1 |
|
将这段代码编译,并在命令窗口执行下面这样的命令:
1 | gcc memory-layout.c -o memory-layout |
可以得到:
1 | text data bss dec hex filename |
现在我们对源代码进行简单修改:
1 |
|
重新编译并执行size命令后可得:
1 | text data bss dec hex filename |
是不是看到bss区的数据多了4个字节?这是因为我们多定义了一个static变量。
再来修改:
1 |
|
1 | text data bss dec hex filename |
这次是data区(初始化数据段)多了4个字节。
1 |
|
1 | text data bss dec hex filename |
4. 问题解答·
好勒,现在我们介绍介绍完c语言内存分布的基础概念,已经可以解决在文初所提出的问题了。
4.1 问题1·
1 | // code 1 |
1 | // code 2 |
这里为什么code 1会报段错误呢?
因为“hello"是存放在初始化数据段中,且字符串常量是只读数据段。我们尝试通过scanf对"hello"所在的地址的数据进行修改是不合法的。
而在code 2中,char str[] = “hello”; 这里的”hello“是作为副本存储在str[]中的,而str[] 是存放在栈区的,栈区的内容当然就可以更改咯。
我们再通过下面这份代码来验证:
1 | int main(void) |
结果:
1 | str1 point to 0x4006b8 |
明显看到"hello"在低内存地址的地方,也从一定程度上说明了"hello"是存放在数据段的。
而str1和str2本身都属于栈区。也就不难理解为什么str2的内容可以更改了。
4.2 问题2·
1 | int main(void) |
理解了问题1,其实问题2也就迎刃而解了。str1和str2都指向了数据段中的“hello”(字符串常量在内存中仅有一份副本,str3和str4则是在栈区的数组,它们各持有"hello"的一份副本)。
所以str1 = str2(指向地址相同),而str3 != str4(两者首地址不同)。
2022年2月26日更新, 感谢@DYH-Hong的指正,对于字符串常量来说,并不一定在内存中只有一份副本,这由编译器决定,在标准中属于 unspecified behavior, 不过这里的重点在于 str1 和 str2 所指向的位置为常量,是不可修改的。
你可将最后的4行printf注释取消,然后执行来查看。在我的电脑上的结果是:
1 | 0x400704 |
看到了吧,前两个是低地址,也就是“hello‘所在数据段,后面都是高地址,也就是栈区。
OK,就到这里了,希望能帮到你,当然如有错误,也欢迎你的指正。
参考·
- Memory Layout of C Programs
- C程序的内存布局
- 从编写源代码到程序在内存中运行的全过程解析
- C语言中字符串常量到底存在哪了?

