IEEE 2013-BwTree·
📌文本采用wolai制作,原文link: https://www.wolai.com/ravenxrz/oRqJQFiQUHU9zSprtUp3tX
原文名: The Bw-Tree: A B-tree for New Hardware Platforms
总结:
本文介绍了Bw-Tree,一种针对新型硬件平台设计的高度优化的B树数据结构。Bw-Tree通过多核优化和与缓存友好的特性,实现了高效的并发操作和数据访问。它的特点是支持delta更新和使用日志结构存储,这有助于提高缓存命中率并减少不必要的磁盘I/O操作。
Bw-Tree的设计考虑到了现代硬件的特点,它包括三个层次:Bw-Tree层、缓存层和闪存层,其中缓存层包含一个映射表,用于跟踪页面的物理位置和内存中的引用。这种映射机制允许Bw-Tree支持delta更新和变长物理页面,同时也使得latch free成为可能(在这篇文章之前,Btree系列还没有latch free的实现)。
文中详细讨论了Bw-Tree的多种操作,如插入、更新、删除、范围扫描、结构修改操作(SMO)和垃圾收集(GC),以及它们是如何在多线程环境下协同工作的。特别地,Bw-Tree采用了一种称为“序列化”的方法来保证操作的原子性和一致性,即使在高度并发的情况下也能保持数据完整性。
实验结果显示,Bw-Tree相对于传统的B树和无锁的跳列表表现出了显著的优势,特别是在高并发和数据密集型工作loads下。这主要得益于其对缓存的高效利用和latch free。
综上所述,Bw-Tree是一种适合现代硬件环境的高效B树实现,其设计巧妙地结合了并发优化、缓存友好性和数据持久化能力,为高性能数据存储和检索提供了强有力的支撑。
特点: 多核优化+cache friendly, update convert to delta, log structured
1 架构&组件·
架构图
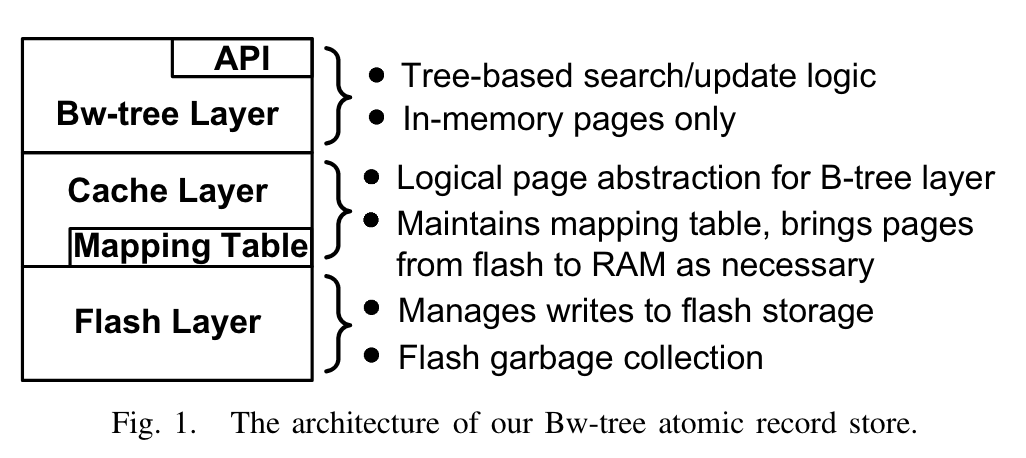
分为三层:
- Bw-tree Layer: 提供BwTree 的访问接口
- Cache Layer:中间层,承接上面Bwtree Layer与下面持久化层 Flash Layer
- Flash Layer: 持久化层,介质可选flash和disk。 持久化选用LSS(Log-structure store)。
特点:
latch free, 所有并发操作采用CAS,thread不会被卡住,除了要从盘上fetch page的场景。减少context-switch, 保证指令缓存。另外,并且page不采用update-in-place,而是采用 deltas-update 的方式,提高cache命中率。
📌为什么说,delta update的方式比update-in-place方式更cache friendly?
在 update-in-place 的方法中,当一个页面需要更新时,会直接修改页面在内存中的内容。如果这个页面之前已经被加载到 CPU 缓存中,那么修改操作会导致缓存中的页面副本与主内存中的页面内容不一致。为了保证数据一致性,CPU 需要将缓存中的页面副本失效 (invalidate),迫使下一次访问时重新从主内存加载。这会带来显著的性能开销,因为从主内存读取数据比从缓存读取数据慢得多。
而 delta updates 的方法则不同。它不是直接修改原页面,而是创建一个包含更新内容的 delta 记录,并将这个 delta 记录附加到原页面上。这样,原页面在缓存中的副本仍然有效,不需要失效。只有当需要读取更新后的页面内容时,CPU 才需要将 delta 记录合并到原页面中。这种方式大大减少了缓存失效的次数,提高了缓存命中率 (cache hit ratio),从而提升了性能。
写盘则是用了log structured的方式,攒buffer来写。一方面随机io转成顺序io(即使是flash ssd,随机写也是弱于顺序写的),另一方面io放大能减少,因为能更好做到按照文件系统4kb对齐,避免读改写。
mapping table
架构图中的cache layer含有一个mapping table, mapping table存放了PID(Page id) 到 物理页面的映射,如果物理页面在内存中,则映射指向内存地址,如果在盘上,则指向文件+offset。
这种mapping带来了delta update 和变长物理页的优势。
📌why? 原文:The mapping table severs the connection between physical location and inter-node links. This enables the physical location of a Bw-tree node to change on every update and every time a page is written to stable storage, without requiring that the location change be propagated to the root of the tree (i.e., updating inter-node links). This “relocation” tolerance directly enables both delta updating of the node in main memory and log structuring of our stable storage, as described below.
Delta updating
每次insert或者update(split page等)都会转换成一个delta record,并记录在mapping table中,同时将mapping table中这个新page的地址记录为这个delta record的地址, 之后(某个实际)通过consolidate操作,将这些增量delta apply到前面的base page,变成真正的page,旧page即可被gc。 论文通过 epoch 的方式gc。
mapping table还使得access page latch free。因为它可以隔离各update操作。
SMO(Structure Modifications Operation)
虽然单个page的操作可以通过CAS操作原子更新,但是整个tree的SMO(如tree split或者merge)无法在单个原子操作中完成。 作者将SMO拆成多个原子操作,同时借鉴B-link tree的思想,每个page都有一个side pointer指向右兄弟节点,将split操作拆成两个"half-atomic"的操作。为了保证no thread is waiting for SMO, 如果一个thread在执行自己操作是发现有SMO操作,thread会先完成SMO,再完成自己的操作。
Log Structure Store
在flush page时,只用flush delta(顺序写),同时采用批量flush多个page的方式(减少io次数)。
📌todo(zhangxingrui):LSS gc怎么玩的?
Managing Transactional Logs
通过WAL保证crash recovery。
2 BwTree单个Page·
Elastic Virtual Pages
BwTree中一个Page包含如下属性:
- 内部节点和B+ tree一样,key + page pointer
- 叶子节点是key + data pointer
- 每个page还包含lowest key 和 highest key
- side link pointer 指向右兄弟
此外BwTere的page还有如下两个特点:
- 每个page是虚拟节点,具体页面地址需要通过PID在mapping table中查询
- 由于是虚拟节点,所以每个page可以不是定长的
page更新操作
BwTree的所有更新操作都是通过install delta来update的。如下图:
这里的install指的是CAS操作。
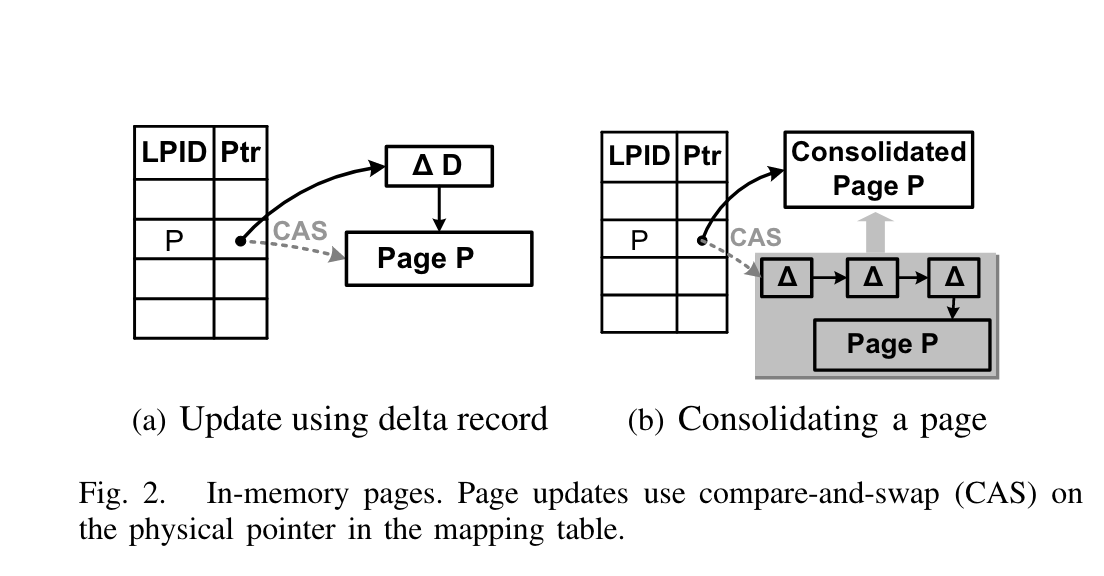
叶节点更新操作包含:
- insert,插入新节点
- modify, 更新同样key的value
- delete,删除目标key
所有都有LSN来完成WAL,用于后续crash recovery。
Consolidation
Page后的delta不能一直增长,不然读开销,空间开销都过大。所以需要在一定条件下合并,BwTree的做法是,当某个thread执行操作时,发现目标page后跟的delta 的长度超过系统设定阈值,则执行合并,如上图所示。通过base+ deltas回放成一个新的new page,并尝试install到mapping table中,如果install失败,该线程直接abort此次合并操作,交给后续thread完成。
Range scan
每个Page的范围是(low key, high key), 其中一端是开区间(这个就看实现了)。在扫描时,记录一个cursor(最开始是lowkey),代表扫描进度。每次扫描到一个新range时,首先读取该range的所有数据,在内存中组成一个vector,如果整个scan过程中,该段数据没有改动,即可安全返回这段数据,并跳到下一段数据中。整个scan过程不是原子的,但是每段scan保证是原子的,事务并发控制(比如lock,mvcc),保证当前scan过程中已经看到的record不会被修改,但是对于未访问的record是可能修改的,所以在Bwtree scan过程中,再返回一端数据前,需要check一把这段数据是否被修改,如果被修改,直接retry,重新构造vector即可。
GC
为了实现latch-free的数据结构,作者采用了 epoch的gc方式。原因在于,不能释放别人还在引用的page页面,比如consolidation过程后,需要将旧page回收,但是如果其他线程还在引用旧page,该page是不能回收的。
📌todo(zhangxingrui): epoch 的回收方式。
3 BwTree SMO·
Node Split·
当访问线程发现某个page需要split时,该线程将执行Split操作。 BwTree采用Blink-tree split方式,将一次split操作分为两个阶段:
- 先install拆分出来的child node
- 再install拆分出来的parent node. We then atomically update the parent node with the new index term containing a new separator key and a pointer to the newly created split page.
这个过程可能递归,直到完成。
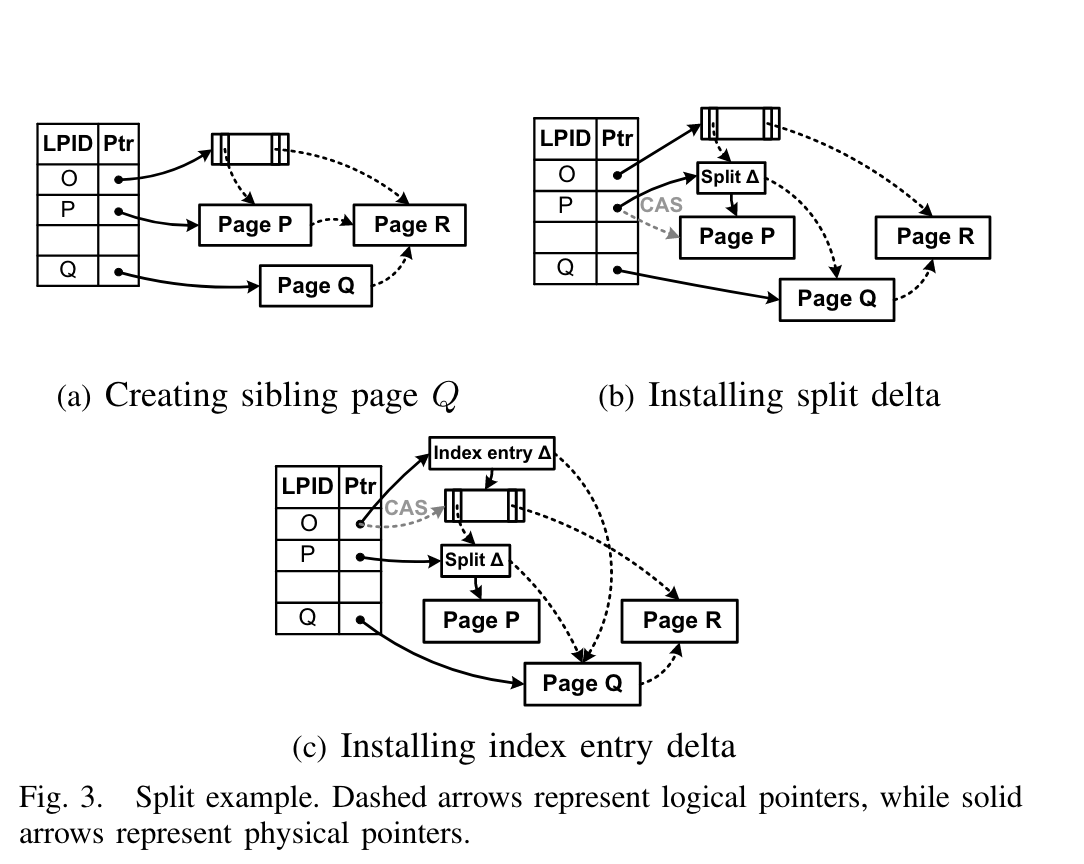
Child split操作:
如Fig 3. 假设Page p要split,分为两步:
- Fig3(a)先生成Page Q,在Page P中找到合适的分割key K,所有大于Kp的keys都拷贝一份到Page Q(注意这里是Page P的最新状态,也就是这个时候要先做合并操作再split?),接着Page Q的side link指向Page P的右兄弟,也就是Page R。接着install Page Q到mapping table中,这。到这里只有当前的操作线程能看到Page Q,因为Page Q还没有完全install到整个树中。
- 为了让Page Q生效,如Fig3(b), 生成一个split delta record到Page P中。这个split delta record包含两部分信息:
- 分割key Kp, 用于invalidate Page P中所有大于Kp的keys,因为这些key都在Q中有一份
- Page P的side pointer指向Page Q。 到这一步,其他线程对Page Q也是可见的,但是Page Q的父节点Page O还看不到Page Q,没有指向Page Q index。 所有要访问Page Q的操作都是通过Page P的side pointer切过来的。
todo(zhangxingrui):如果步骤a和步骤b之间有其他线程对Page P或者Page Q做了操作,步骤b还能顺利执行吗?
Parent Update操作
Child Split完成后,Page Q的Parent中还没有关于Page Q的index。所以此步骤中:
- 生成一个 index term delta record 到父节点Page O中, 这个index term包括:
- Kp Page P和Page Q的分割key。
- 一个指向Page Q的指针
- Kq, 作为Page Q的分割key(原始是你作为Page P的分割key)
这个过程可以这样理解,如下图,分裂前:

假设Page P 分裂成:

则Kp 为6,Kq为8.
- 添加索引的过程同样可以递归,从root走到leaf的path是被记住的,所以很容易得到父节点有哪些,如果没有并发,这些父节点是确定的,一路更新即可。如果有并发,某些父节点被merge到其它节点,bwtree的epoch机制保证当前持有的“父节点”们是一定没被删除的,如果某个父节点过期了,再回到该父节点的父节点(即祖父节点),重新寻找新的父节点即可。这个过程可能会回溯到root节点。
index term delta record持有Kp和Kq的作用是为了加速search: 如果要search 的Kv是大于Kp小于等于Kq的,那么直接索引到Page Q即可。如果没有这个信息,search的过程不得不找到Base Page,中Base Page中采用binary search的方式找到合适的index pointer,然后再定位到Page Q。
Consolidation操作
通过追加delta的方式,能够降低split时延,降低split时延也就减少了update冲突的可能,提高并发。但是最终还是需要在某个实际合并这些deltas。
📌todo(zhangxingrui)合并实际如何选择?
3.2 Node merge·
和split操作对立的是merge操作, 当某个节点内key数低于阈值时发生。
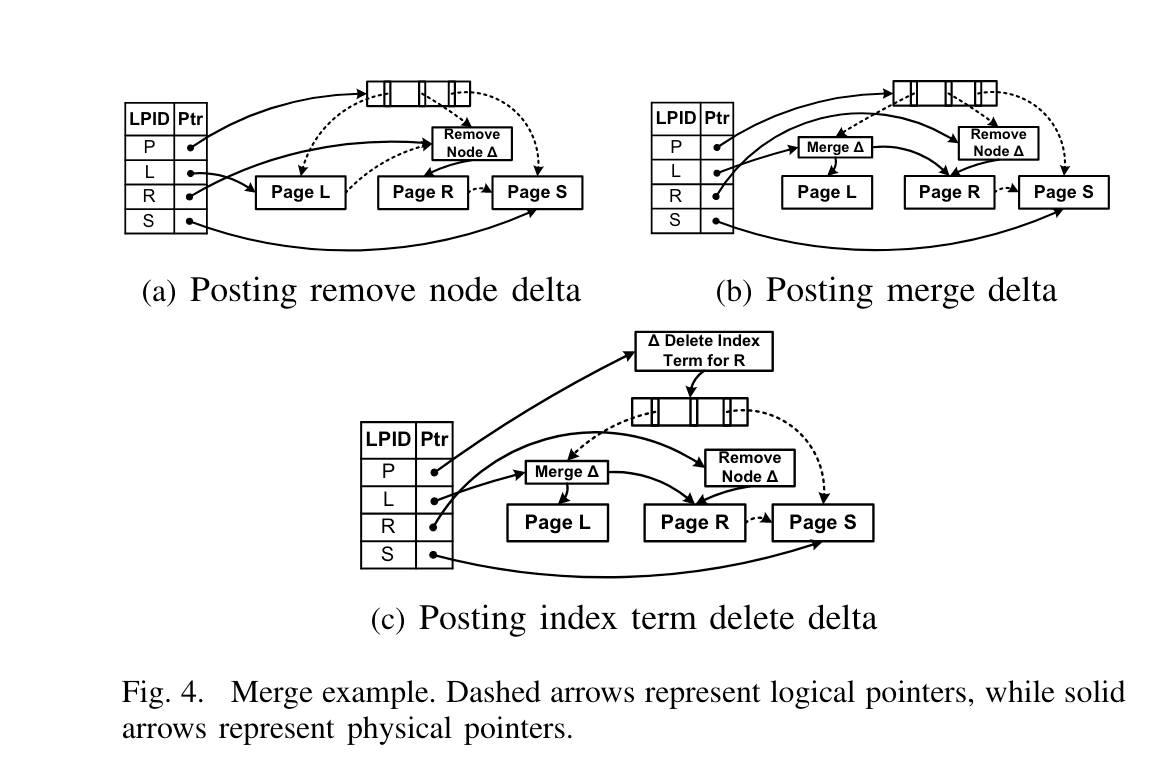
整个过程如下:
Marking for Delete
如Fig4(a) , 假设Page R要被删除,首先追加一个 remove node delta record, 这标记该node被frozen掉了, 该节点后续不能再使用,所有对Page R的操作都会被重定向。 如果某个线程操作时遇到了Page R带remove node delta reocord,需要转到其左兄弟节点读数据、或更新数据,因为Page R的数据已经“转移”到左兄弟了。
Merging Children
如Fig4(b), Page L增加一个 node merge delta record. 该delta包含一个指向Page R content的指针(也就是说不直接复制Page R的数据)。 当完成这个操作时,即可认为Page R的状态完全转移到Page L(除了remove node delta record),等到consolidate操作时再移除Page R。
当search L时,L包含了原来L的数据和来自R的数据, ndoe merge delta record还包含一个分割key,用于正确导向Page R。
Parent Update
如Fig4©, 通过给Parent添加一个 index term delete delta record , 表明Page R被删除,同时Page L包含了Page R的原数据。 同时更新L的key space range,low key是L原来的low key,high key则是R的high key。 使得搜索delta时能正确定位,如果穿透了delta到了base page,则采用二分查找的方式。 另外,一旦这个delta record被install好后,要访问Page R的所有操作均为block,之后就可以开启Page R的页面回收,通过将Page R的PID加入到当前epoch的pending delete list中完成。当当前epoch所有对Page R的访问线程均退出后,该Page即可回收。
3.3 序列化SMO和Update·
要保证SMO和update操作是 serial schedule , 也即保证每个SMO和update都是atomic的是相当困难的。因为SMO是由多个原子操作组成的。
📌什么是serial schedule? 这是一个DBMS中的概念,serial schedule 是指一个调度,它不 interleaving(即不交错)不同事务的动作。换句话说,serial schedule 是一个顺序执行的调度,其中每个事务的操作都是按照一定的顺序依次执行的,没有并发执行的情况。在数据库管理系统(DBMS)中,serial schedule 提供了事务之间隔离的最高级别,因为每个事务都像是在系统中单独运行,看不到其他并发事务的影响。
为什么Bwtree要保证 serial schedule? 因为要保证多线程操作时Bwtree的一致性,例如两个线程,thread 1要删除Page 1,将Page 1合并到Page0, 但是此时thread 1又要分裂Page 0,这种并发怎么处理?
Bwtree的解决方式很简单(听起来简单,实现起来应该很难受),所有thread在执行自己的操作(update或者SMO)时,如果遇到了其它incomplete 的SMO操作(可以看做是一个uncommited的事务),暂停自己的update或SMO操作(可能是直接abort后retry),先完成这个incomplete的SMO操作,再重新执行自己的操作。 这保证了各个SMO、update直接一定是串行的。 整个过程像是一个stack,遇到新的incompeted操作就先完成该操作(FILO)。
4 Cache管理·
cache layer负责read、flush和swap page between 内存和flash设备。
在将内存page flush到flash设备时,会给page添加一个flush delta record, flush delta record记录了哪些修改已经被flush到设备了(笔者注:估计用LSN来表示),之后的flush即是增量flush。
4.1 WAL协议和LSN·
📌本节可跳过, 文章中的TC和DC概念笔者不清楚,描述大概率有误。
LSN: 所有insert和update delta都绑定了一个LSN,flush时记录LSN号,表明更新到哪里。 LSN由上游TC生成(笔者注:可类比mysql的redo log lsn)。
Transaction log coordination:ESL(End of stable LSN)表明当前TC持久化log持久化到的最新LSN, 系统周期性将该值返回给DC,DC只承认小于等于ESL的LSN被持久化。在flush page到LSS时,也只会flush到小于等于ESL的page修改。
📌todo(zhangxingrui): TC、DC的概念待查
Bwtree中做consolidation时,只会consolidate LSN≤ESL的那部分。
后续部分,略。
4.2 Flushing Pages to LSS·
这部分主要描述的是BwTree如何实现的log增量刷新(通过LSN和ESL来控制要刷新的部分),以及聚合IO来写,这些加速了flush速度、减少了写放大。
cache层监控BwTree当前使用的内存大小,如果太大,则将内存papge交换到LSS, 之后即可通过epoch的方式回收。
5 实验·
BwTree采用传统B tree(BerkeleyDB) 和 latch free skiplist作为对照组。实验负载包括XBox,Dedup和合成负载,每个负载都执行实验时,采用8 thread worker。
另,Bwtree内部部分代码都有约1w行。相当复杂的数据结构了。
首先分析BwTree内部参数的影响:
- 对比了不同 delta chain len 对系统OPS的影响,效果如下图:
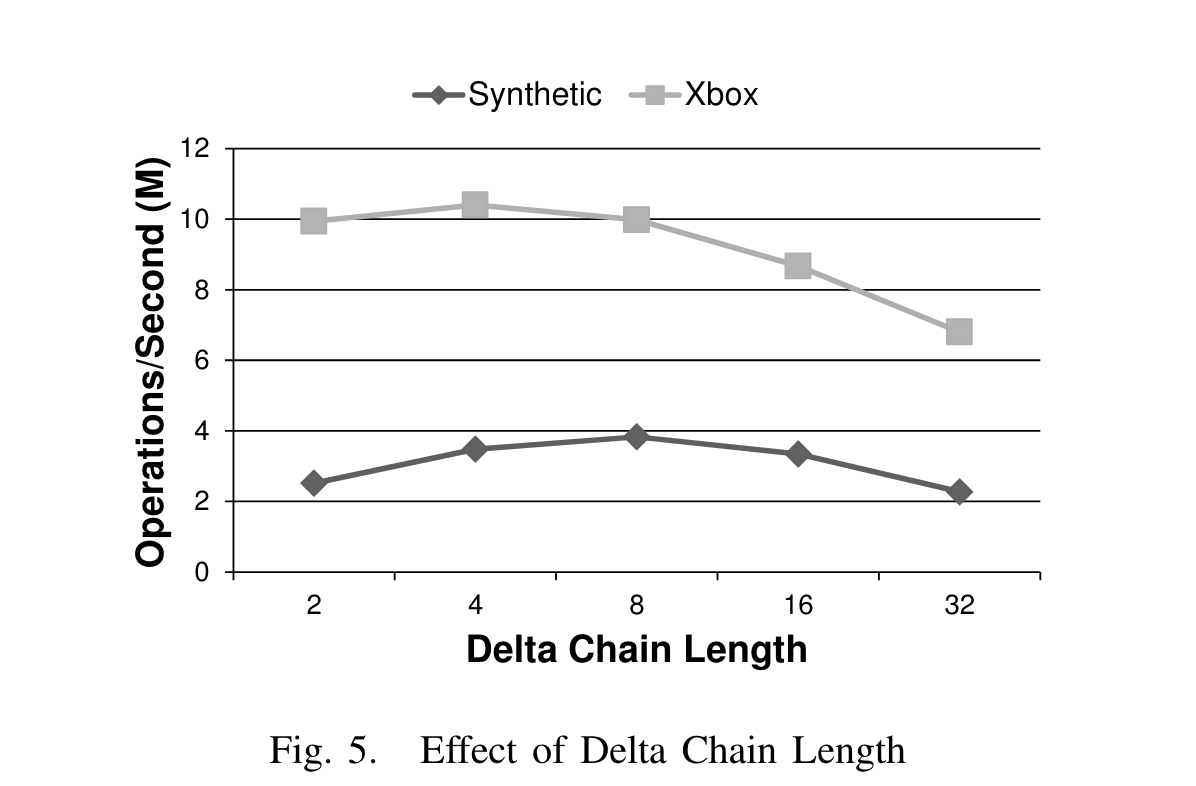
对于XBox负载,length长于4,searach性能就开始衰减,对于合成负载,length要长于8. 作者认为,对于scan操作,由于XBox负载中,value长度较大(论文中说有超过100B的),无法hold in L1 cache,无法充分利用cache和预取,而合成负载只有8B,很小,可以充分利用cache和预取。
- 做了 latch free 操作失败的实验:
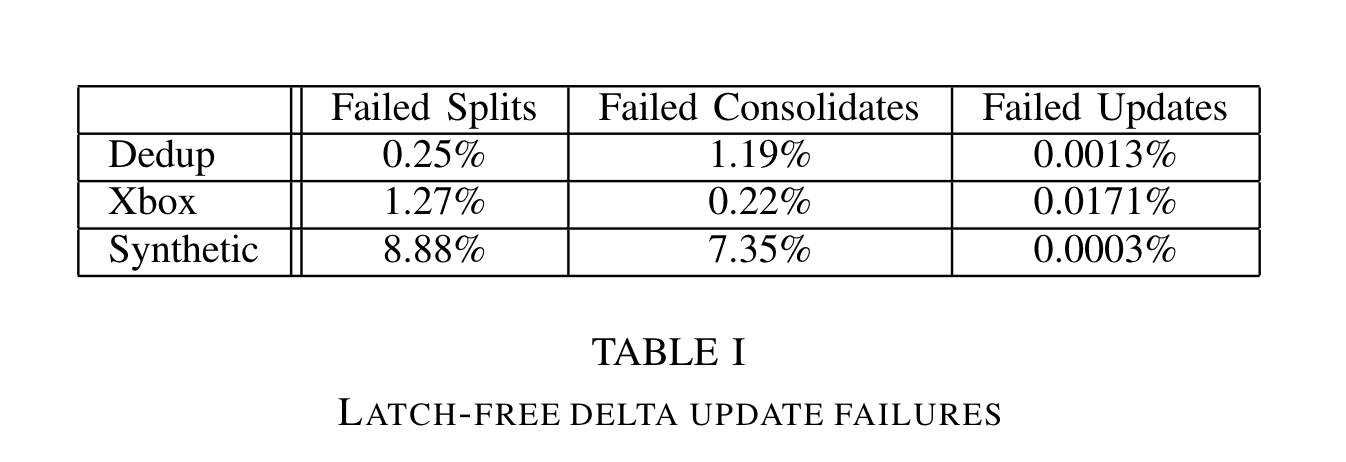
update类操作在所有负载下都很低,split和consolidate操作略高,但是作者认为可以接受,在合成负载中,失败率最高,因为合成负载的key value都很小,update操作很快完成。
之后对比B tree:
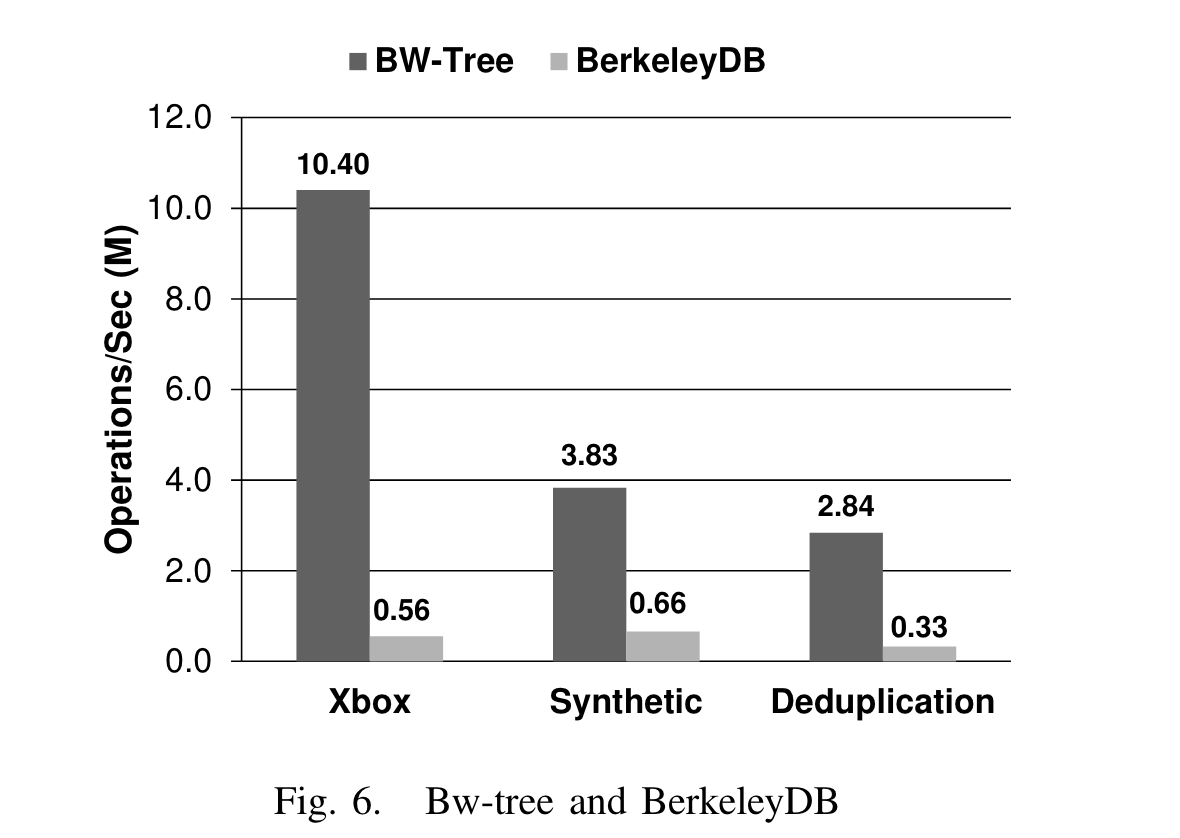
XBox负载下,高了18.7x ,dedup负载(update intensive)下高了8.6x,合成负载(小kv)高了5.8x。
作者分析,BwTree性能优秀的原因来自两方面: 1. latch-free, b tree需要latch,cpu利用率不如bwtree高(btree只有60%的利用率,bwtree则达到99%)。 2. bwtree更cache friendly,因为没有update-in-place。
再对比latch free 的skiplist:
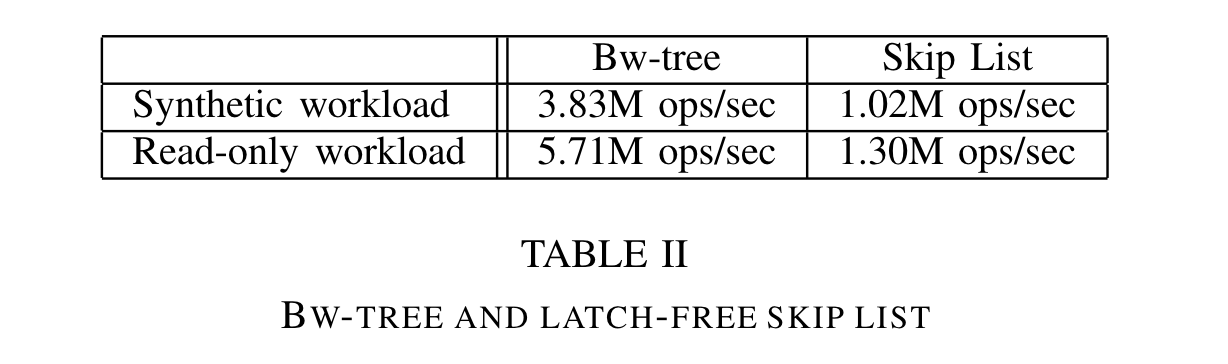
BwTree依然优秀。
另外,作者还用Intel VTune 套件测试对比了cache efficiency:
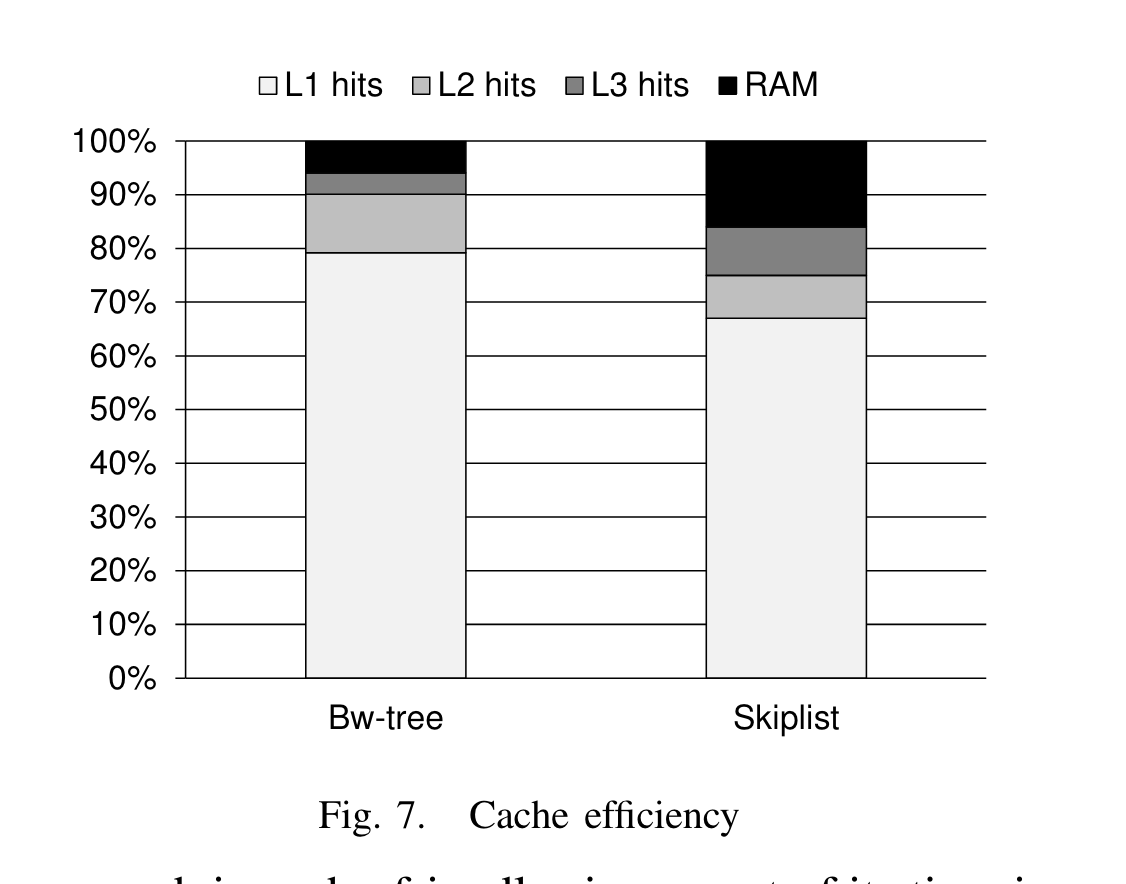
结果再次证明BwTree用cache更友好,90%以上的数据来自L1或者L2cache。

